 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Wireless Communication for 6G: Intent-Aware and Continuously Evolving Physical-Layer Intelligence
Feb 19, 2026As 6G wireless systems evolve, growing functional complexity and diverse service demands are driving a shift from rule-based control to intent-driven autonomous intelligence. User requirements are no longer captured by a single metric (e.g., throughput or reliability), but by multi-dimensional objectives such as latency sensitivity, energy preference, computational constraints, and service-level requirements. These objectives may also change over time due to environmental dynamics and user-network interactions. Therefore, accurate understanding of both the communication environment and user intent is critical for autonomous and sustainably evolving 6G communications. Large language models (LLMs), with strong contextual understanding and cross-modal reasoning, provide a promising foundation for intent-aware network agents. Compared with rule-driven or centrally optimized designs, LLM-based agents can integrate heterogeneous information and translate natural-language intents into executable control and configuration decisions. Focusing on a closed-loop pipeline of intent perception, autonomous decision making, and network execution, this paper investigates agentic AI for the 6G physical layer and its realization pathways. We review representative physical-layer tasks and their limitations in supporting intent awareness and autonomy, identify application scenarios where agentic AI is advantageous, and discuss key challenges and enabling technologies in multimodal perception, cross-layer decision making, and sustainable optimization. Finally, we present a case study of an intent-driven link decision agent, termed AgenCom, which adaptively constructs communication links under diverse user preferences and channel conditions.
Sim2Real Deep Transfer for Per-Device CFO Calibration
Jan 15, 2026Carrier Frequency Offset (CFO) estimation in Orthogonal Frequency Division Multiplexing (OFDM) systems faces significant performance degradation across heterogeneous software-defined radio (SDR) platforms due to uncalibrated hardware impairments. Existing deep neural network (DNN)-based approaches lack device-level adaptation, limiting their practical deployment. This paper proposes a Sim2Real transfer learning framework for per-device CFO calibration, combining simulation-driven pretraining with lightweight receiver adaptation. A backbone DNN is pre-trained on synthetic OFDM signals incorporating parametric hardware distortions (e.g., phase noise, IQ imbalance), enabling generalized feature learning without costly cross-device data collection. Subsequently, only the regression layers are fine-tuned using $1,000$ real frames per target device, preserving hardware-agnostic knowledge while adapting to device-specific impairments. Experiments across three SDR families (USRP B210, USRP N210, HackRF One) achieve $30\times$ BER reduction compared to conventional CP-based methods under indoor multipath conditions. The framework bridges the simulation-to-reality gap for robust CFO estimation, enabling cost-effective deployment in heterogeneous wireless systems.
Rethinking Secure Semantic Communications in the Age of Generative and Agentic AI: Threats and Opportunities
Jan 06, 2026Semantic communication (SemCom) improves communication efficiency by transmitting task-relevant information instead of raw bits and is expected to be a key technology for 6G networks. Recent advances in generative AI (GenAI) further enhance SemCom by enabling robust semantic encoding and decoding under limited channel conditions. However, these efficiency gains also introduce new security and privacy vulnerabilities. Due to the broadcast nature of wireless channels, eavesdroppers can also use powerful GenAI-based semantic decoders to recover private information from intercepted signals. Moreover, rapid advances in agentic AI enable eavesdroppers to perform long-term and adaptive inference through the integration of memory, external knowledge, and reasoning capabilities. This allows eavesdroppers to further infer user private behavior and intent beyond the transmitted content. Motivated by these emerging challenges, this paper comprehensively rethinks the security and privacy of SemCom systems in the age of generative and agentic AI. We first present a systematic taxonomy of eavesdropping threat models in SemCom systems. Then, we provide insights into how GenAI and agentic AI can enhance eavesdropping threats. Meanwhile, we also highlight potential opportunities for leveraging GenAI and agentic AI to design privacy-preserving SemCom systems.
Bridging the Modality Gap: Enhancing Channel Prediction with Semantically Aligned LLMs and Knowledge Distillation
May 19, 2025Accurate channel prediction is essential in massive multiple-input multiple-output (m-MIMO) systems to improve precoding effectiveness and reduce the overhead of channel state information (CSI) feedback. However, existing methods often suffer from accumulated prediction errors and poor generalization to dynamic wireless environments. Large language models (LLMs) have demonstrated remarkable modeling and generalization capabilities in tasks such as time series prediction, making them a promising solution. Nevertheless, a significant modality gap exists between the linguistic knowledge embedded in pretrained LLMs and the intrinsic characteristics of CSI, posing substantial challenges for their direct application to channel prediction. Moreover, the large parameter size of LLMs hinders their practical deployment in real-world communication systems with stringent latency constraints. To address these challenges, we propose a novel channel prediction framework based on semantically aligned large models, referred to as CSI-ALM, which bridges the modality gap between natural language and channel information. Specifically, we design a cross-modal fusion module that aligns CSI representations . Additionally, we maximize the cosine similarity between word embeddings and CSI embeddings to construct semantic cues. To reduce complexity and enable practical implementation, we further introduce a lightweight version of the proposed approach, called CSI-ALM-Light. This variant is derived via a knowledge distillation strategy based on attention matrices. Extensive experimental results demonstrate that CSI-ALM achieves a 1 dB gain over state-of-the-art deep learning methods. Moreover, under limited training data conditions, CSI-ALM-Light, with only 0.34M parameters, attains performance comparable to CSI-ALM and significantly outperforms conventional deep learning approaches.
Can Knowledge Improve Security? A Coding-Enhanced Jamming Approach for Semantic Communication
May 06, 2025As semantic communication (SemCom) attracts growing attention as a novel communication paradigm, ensuring the security of transmitted semantic information over open wireless channels has become a critical issue. However, traditional encryption methods often introduce significant additional communication overhead to maintain stability, and conventional learning-based secure SemCom methods typically rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in real-world scenarios. In this paper, we propose a coding-enhanced jamming method that eliminates the need to transmit a secret key by utilizing shared knowledge-potentially part of the training set of the SemCom system-between the legitimate receiver and the transmitter. Specifically, we leverage the shared private knowledge base to generate a set of private digital codebooks in advance using neural network (NN)-based encoders. For each transmission, we encode the transmitted data into digital sequence Y1 and associate Y1 with a sequence randomly picked from the private codebook, denoted as Y2, through superposition coding. Here, Y1 serves as the outer code and Y2 as the inner code. By optimizing the power allocation between the inner and outer codes, the legitimate receiver can reconstruct the transmitted data using successive decoding with the index of Y2 shared, while the eavesdropper' s decoding performance is severely degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.
Enhancing the Security of Semantic Communication via Knowledge-Aided Coding and Jamming
May 01, 2025As semantic communication (SemCom) emerges as a promising communication paradigm, ensuring the security of semantic information over open wireless channels has become crucial. Traditional encryption methods introduce considerable communication overhead, while existing learning-based secure SemCom schemes often rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in practice. In this paper, we propose a coding-enhanced jamming approach that eliminates the need to transmit a secret key by utilizing shared knowledge between the legitimate receiver and the transmitter. We generate private codebooks with neural network (NN)-based encoders, using them to encode data into a sequence Y1, which is then superposed with a sequence Y2 drawn from the private codebook. By optimizing the power allocation between the two sequences, the legitimate receiver can successfully decode the data, while the eavesdropper' s performance is significantly degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.
Enhancing Privacy in Semantic Communication over Wiretap Channels leveraging Differential Privacy
Apr 23, 2025



Semantic communication (SemCom) improves transmission efficiency by focusing on task-relevant information. However, transmitting semantic-rich data over insecure channels introduces privacy risks. This paper proposes a novel SemCom framework that integrates differential privacy (DP) mechanisms to protect sensitive semantic features. This method employs the generative adversarial network (GAN) inversion technique to extract disentangled semantic features and uses neural networks (NNs) to approximate the DP application and removal processes, effectively mitigating the non-invertibility issue of DP. Additionally, an NN-based encryption scheme is introduced to strengthen the security of channel inputs. Simulation results demonstrate that the proposed approach effectively prevents eavesdroppers from reconstructing sensitive information by generating chaotic or fake images, while ensuring high-quality image reconstruction for legitimate users. The system exhibits robust performance across various privacy budgets and channel conditions, achieving an optimal balance between privacy protection and reconstruction fidelity.
A Coding-Enhanced Jamming Approach for Secure Semantic Communication over Wiretap Channels
Apr 23, 2025As semantic communication (SemCom) gains increasing attention as a novel communication paradigm, ensuring the security of transmitted semantic information over open wireless channels becomes crucial. Existing secure SemCom solutions often lack explicit control over security. To address this, we propose a coding-enhanced jamming approach for secure SemCom over wiretap channels. This approach integrates deep joint source and channel coding (DeepJSCC) with neural network-based digital modulation, enabling controlled jamming through two-layer superposition coding. The outer constellation sequence encodes the source image, while the inner constellation sequence, derived from a secret image, acts as the jamming signal. By minimizing the mutual information between the outer and inner constellation sequences, the jamming effect is enhanced. The jamming signal is superposed on the outer constellation sequence, preventing the eavesdropper from recovering the source image. The power allocation coefficient (PAC) in the superposition coding can be adjusted to control system security. Experiments show that our approach matches existing methods in security while significantly improving reconstruction performance across varying channel signal-to-noise ratios (SNRs) and compression ratios.
Towards Secure Semantic Communications in the Presence of Intelligent Eavesdroppers
Mar 29, 2025Semantic communication has emerged as a promising paradigm for enhancing communication efficiency in sixth-generation (6G) networks. However, the broadcast nature of wireless channels makes SemCom systems vulnerable to eavesdropping, which poses a serious threat to data privacy. Therefore, we investigate secure SemCom systems that preserve data privacy in the presence of eavesdroppers. Specifically, we first explore a scenario where eavesdroppers are intelligent and can exploit semantic information to reconstruct the transmitted data based on advanced artificial intelligence (AI) techniques. To counter this, we introduce novel eavesdropping attack strategies that utilize model inversion attacks and generative AI (GenAI) models. These strategies effectively reconstruct transmitted private data processed by the semantic encoder, operating in both glass-box and closed-box settings. Existing defense mechanisms against eavesdropping often cause significant distortions in the data reconstructed by eavesdroppers, potentially arousing their suspicion. To address this, we propose a semantic covert communication approach that leverages an invertible neural network (INN)-based signal steganography module. This module covertly embeds the channel input signal of a private sample into that of a non-sensitive host sample, thereby misleading eavesdroppers. Without access to this module, eavesdroppers can only extract host-related information and remain unaware of the hidden private content. We conduct extensive simulations under various channel conditions in image transmission tasks. Numerical results show that while conventional eavesdropping strategies achieve a success rate of over 80\% in reconstructing private information, the proposed semantic covert communication effectively reduces the eavesdropping success rate to 0.
A Remedy to Compute-in-Memory with Dynamic Random Access Memory: 1FeFET-1C Technology for Neuro-Symbolic AI
Oct 20, 2024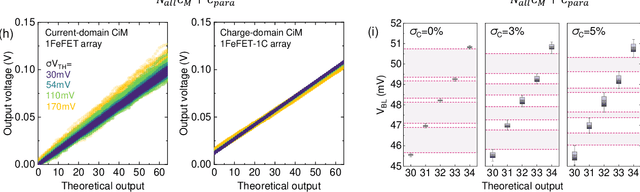
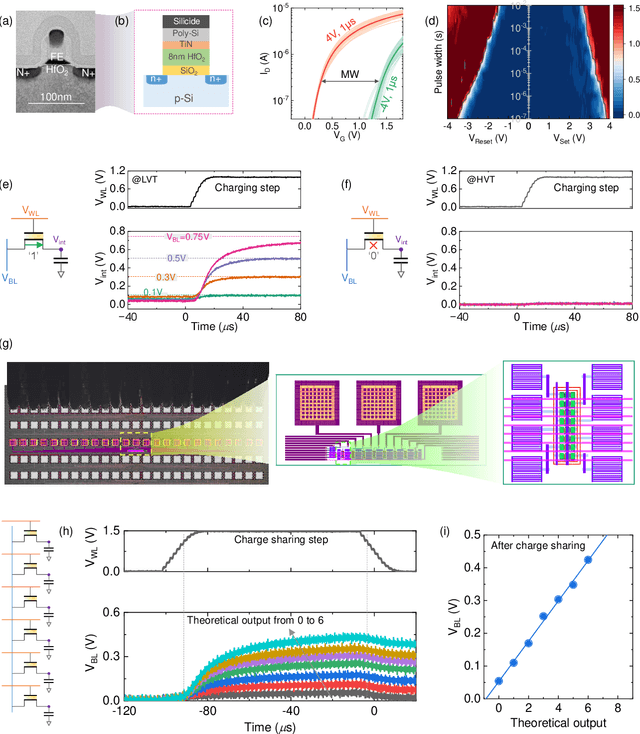
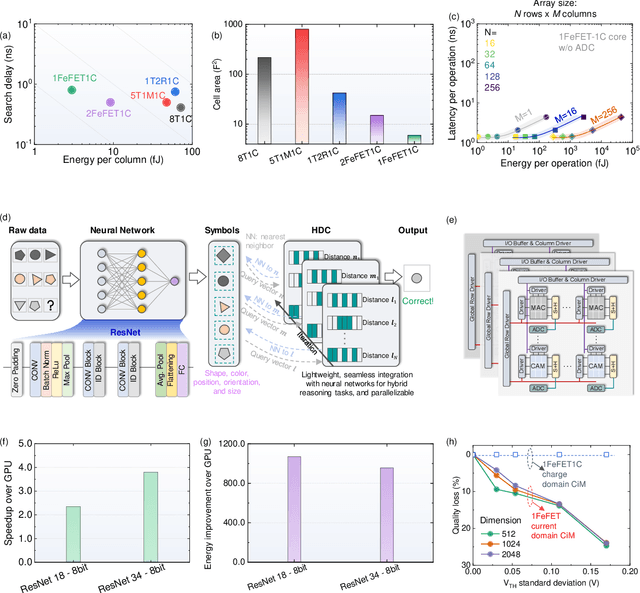
Neuro-symbolic artificial intelligence (AI) excels at learning from noisy and generalized patterns, conducting logical inferences, and providing interpretable reasoning. Comprising a 'neuro' component for feature extraction and a 'symbolic' component for decision-making, neuro-symbolic AI has yet to fully benefit from efficient hardware accelerators. Additionally, current hardware struggles to accommodate applications requiring dynamic resource allocation between these two components. To address these challenges-and mitigate the typical data-transfer bottleneck of classical Von Neumann architectures-we propose a ferroelectric charge-domain compute-in-memory (CiM) array as the foundational processing element for neuro-symbolic AI. This array seamlessly handles both the critical multiply-accumulate (MAC) operations of the 'neuro' workload and the parallel associative search operations of the 'symbolic' workload. To enable this approach, we introduce an innovative 1FeFET-1C cell, combining a ferroelectric field-effect transistor (FeFET) with a capacitor. This design, overcomes the destructive sensing limitations of DRAM in CiM applications, while capable of capitalizing decades of DRAM expertise with a similar cell structure as DRAM, achieves high immunity against FeFET variation-crucial for neuro-symbolic AI-and demonstrates superior energy efficiency. The functionalities of our design have been successfully validated through SPICE simulations and prototype fabrication and testing. Our hardware platform has been benchmarked in executing typical neuro-symbolic AI reasoning tasks, showing over 2x improvement in latency and 1000x improvement in energy efficiency compared to GPU-based implementations.