 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Token Communication with Parametric Memory Network
May 03, 2026Token communication has emerged as a promising framework for efficient wireless transmission by representing source data as compact semantic tokens. However, transmitting full semantic tokens still incurs considerable communication overhead. In this paper, we propose an evolving semantic token communication system with a parametric memory network over MIMO fading channels. Specifically, only an equal-length prefix of each semantic token is transmitted, which reduces transmission cost while preserving a consistent token structure for receiver-side recovery. At the receiver, a parametric memory network is introduced to reconstruct the missing suffix information from the received token prefixes, where semantic memory is stored implicitly in the network parameters. To realize this design, full semantic tokens are first organized into a codebook, and truncated tokens are paired with the codeword labels of their corresponding full tokens. Based on these token-label pairs, kNN-based teacher distributions are constructed to fine-tune a pretrained GPT-2-based recovery module, which learns to infer the codeword distribution of each incomplete token and recover the corresponding complete semantic token. In addition, an online evolution strategy is developed to periodically update the parametric memory network and the entire system using newly observed test samples, thereby improving adaptability under distribution shifts. Experimental results demonstrate that the proposed method consistently outperforms the existing evolving memory benchmark under different channel conditions and channel bandwidth ratios, with up to 1.09 dB PSNR improvement.
HumanOmni-Speaker: Identifying Who said What and When
Mar 23, 2026While Omni-modal Large Language Models have made strides in joint sensory processing, they fundamentally struggle with a cornerstone of human interaction: deciphering complex, multi-person conversational dynamics to accurately answer ``Who said what and when.'' Current models suffer from an ``illusion of competence'' -- they exploit visual biases in conventional benchmarks to bypass genuine cross-modal alignment, while relying on sparse, low-frame-rate visual sampling that destroys crucial high-frequency dynamics like lip movements. To shatter this illusion, we introduce Visual-Registered Speaker Diarization and Recognition (VR-SDR) and the HumanOmni-Speaker Benchmark. By strictly eliminating visual shortcuts, this rigorous paradigm demands true end-to-end spatio-temporal identity binding using only natural language queries. To overcome the underlying architectural perception gap, we propose HumanOmni-Speaker, powered by a Visual Delta Encoder. By sampling raw video at 25 fps and explicitly compressing inter-frame motion residuals into just 6 tokens per frame, it captures fine-grained visemes and speaker trajectories without triggering a catastrophic token explosion. Ultimately, HumanOmni-Speaker demonstrates strong multimodal synergy, natively enabling end-to-end lip-reading and high-precision spatial localization without intrusive cropping, and achieving superior performance across a wide spectrum of speaker-centric tasks.
Can Knowledge Improve Security? A Coding-Enhanced Jamming Approach for Semantic Communication
May 06, 2025As semantic communication (SemCom) attracts growing attention as a novel communication paradigm, ensuring the security of transmitted semantic information over open wireless channels has become a critical issue. However, traditional encryption methods often introduce significant additional communication overhead to maintain stability, and conventional learning-based secure SemCom methods typically rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in real-world scenarios. In this paper, we propose a coding-enhanced jamming method that eliminates the need to transmit a secret key by utilizing shared knowledge-potentially part of the training set of the SemCom system-between the legitimate receiver and the transmitter. Specifically, we leverage the shared private knowledge base to generate a set of private digital codebooks in advance using neural network (NN)-based encoders. For each transmission, we encode the transmitted data into digital sequence Y1 and associate Y1 with a sequence randomly picked from the private codebook, denoted as Y2, through superposition coding. Here, Y1 serves as the outer code and Y2 as the inner code. By optimizing the power allocation between the inner and outer codes, the legitimate receiver can reconstruct the transmitted data using successive decoding with the index of Y2 shared, while the eavesdropper' s decoding performance is severely degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.
Enhancing the Security of Semantic Communication via Knowledge-Aided Coding and Jamming
May 01, 2025As semantic communication (SemCom) emerges as a promising communication paradigm, ensuring the security of semantic information over open wireless channels has become crucial. Traditional encryption methods introduce considerable communication overhead, while existing learning-based secure SemCom schemes often rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in practice. In this paper, we propose a coding-enhanced jamming approach that eliminates the need to transmit a secret key by utilizing shared knowledge between the legitimate receiver and the transmitter. We generate private codebooks with neural network (NN)-based encoders, using them to encode data into a sequence Y1, which is then superposed with a sequence Y2 drawn from the private codebook. By optimizing the power allocation between the two sequences, the legitimate receiver can successfully decode the data, while the eavesdropper' s performance is significantly degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.
A Coding-Enhanced Jamming Approach for Secure Semantic Communication over Wiretap Channels
Apr 23, 2025As semantic communication (SemCom) gains increasing attention as a novel communication paradigm, ensuring the security of transmitted semantic information over open wireless channels becomes crucial. Existing secure SemCom solutions often lack explicit control over security. To address this, we propose a coding-enhanced jamming approach for secure SemCom over wiretap channels. This approach integrates deep joint source and channel coding (DeepJSCC) with neural network-based digital modulation, enabling controlled jamming through two-layer superposition coding. The outer constellation sequence encodes the source image, while the inner constellation sequence, derived from a secret image, acts as the jamming signal. By minimizing the mutual information between the outer and inner constellation sequences, the jamming effect is enhanced. The jamming signal is superposed on the outer constellation sequence, preventing the eavesdropper from recovering the source image. The power allocation coefficient (PAC) in the superposition coding can be adjusted to control system security. Experiments show that our approach matches existing methods in security while significantly improving reconstruction performance across varying channel signal-to-noise ratios (SNRs) and compression ratios.
Enhancing Privacy in Semantic Communication over Wiretap Channels leveraging Differential Privacy
Apr 23, 2025



Semantic communication (SemCom) improves transmission efficiency by focusing on task-relevant information. However, transmitting semantic-rich data over insecure channels introduces privacy risks. This paper proposes a novel SemCom framework that integrates differential privacy (DP) mechanisms to protect sensitive semantic features. This method employs the generative adversarial network (GAN) inversion technique to extract disentangled semantic features and uses neural networks (NNs) to approximate the DP application and removal processes, effectively mitigating the non-invertibility issue of DP. Additionally, an NN-based encryption scheme is introduced to strengthen the security of channel inputs. Simulation results demonstrate that the proposed approach effectively prevents eavesdroppers from reconstructing sensitive information by generating chaotic or fake images, while ensuring high-quality image reconstruction for legitimate users. The system exhibits robust performance across various privacy budgets and channel conditions, achieving an optimal balance between privacy protection and reconstruction fidelity.
Semantic Communication with Entropy-and-Channel-Adaptive Rate Control
Jan 26, 2025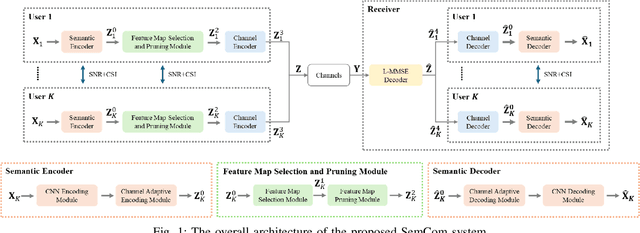
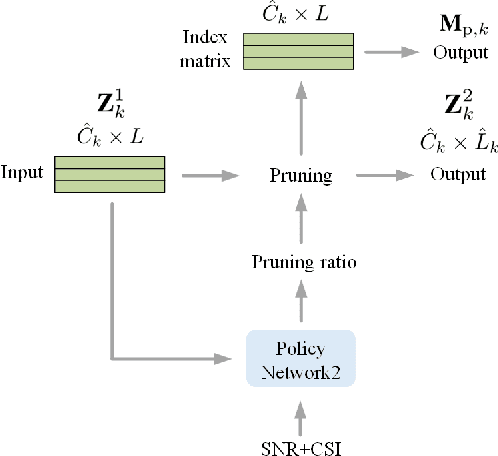
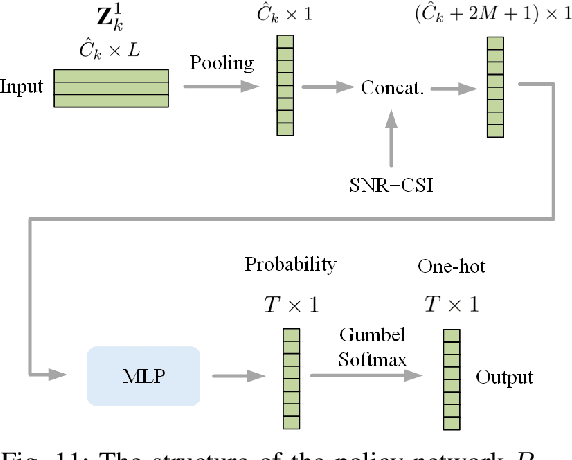
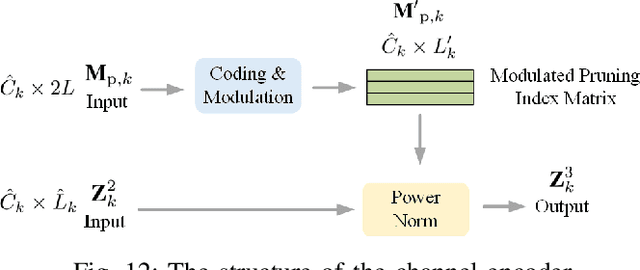
Traditional wireless image transmission methods struggle to balance rate efficiency and reconstruction quality under varying channel conditions. To address these challenges, we propose a novel semantic communication (SemCom) system that integrates entropy-aware and channel-adaptive mechanisms for wireless image transmission over multi-user multiple-input multiple-output (MU-MIMO) fading channels. Unlike existing approaches, our system dynamically adjusts transmission rates based on the entropy of feature maps, channel state information (CSI), and signal-to-noise ratio (SNR), ensuring optimal resource utilization and robust performance. The system employs feature map pruning, channel attention, spatial attention, and multihead self-attention (MHSA) mechanisms to prioritize critical semantic features and effectively reconstruct images. Experimental results demonstrate that the proposed system outperforms state-of-the-art benchmarks, including BPG+LDPC+4QAM and Deep JSCC, in terms of rate-distortion performance, flexibility, and robustness, particularly under challenging conditions such as low SNR, imperfect CSI, and inter-user interference. This work establishes a strong foundation for adaptive-rate SemCom systems and highlights their potential for real-time, bandwidthintensive applications.
CASC: Condition-Aware Semantic Communication with Latent Diffusion Models
Nov 10, 2024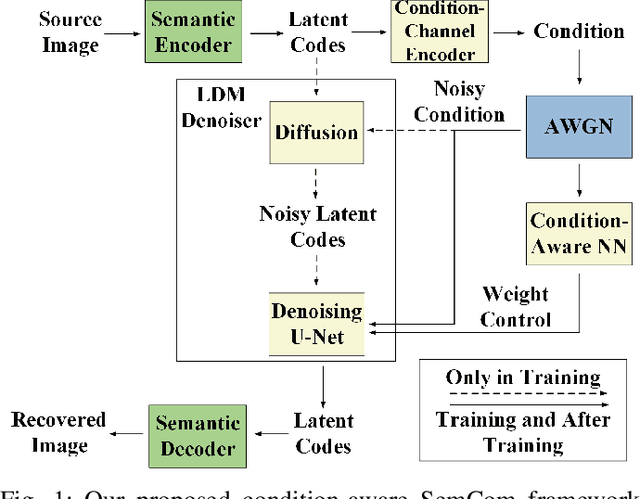

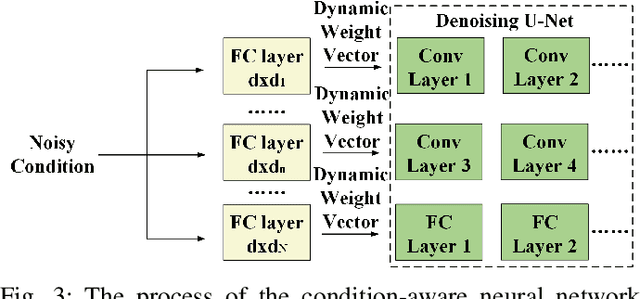

Diffusion-based semantic communication methods have shown significant advantages in image transmission by harnessing the generative power of diffusion models. However, they still face challenges, including generation randomness that leads to distorted reconstructions and high computational costs. To address these issues, we propose CASC, a condition-aware semantic communication framework that incorporates a latent diffusion model (LDM)-based denoiser. The LDM denoiser at the receiver utilizes the received noisy latent codes as the conditioning signal to reconstruct the latent codes, enabling the decoder to accurately recover the source image. By operating in the latent space, the LDM reduces computational complexity compared to traditional diffusion models (DMs). Additionally, we introduce a condition-aware neural network (CAN) that dynamically adjusts the weights in the hidden layers of the LDM based on the conditioning signal. This enables finer control over the generation process, significantly improving the perceptual quality of the reconstructed images. Experimental results show that CASC significantly outperforms DeepJSCC in both perceptual quality and visual effect. Moreover, CASC reduces inference time by 51.7% compared to existing DM-based semantic communication systems, while maintaining comparable perceptual performance. The ablation studies also validate the effectiveness of the CAN module in improving the image reconstruction quality.
Enhancing Image Privacy in Semantic Communication over Wiretap Channels leveraging Differential Privacy
May 15, 2024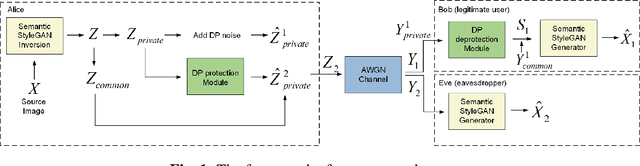
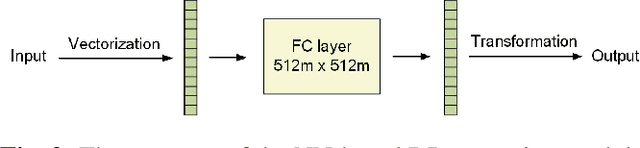
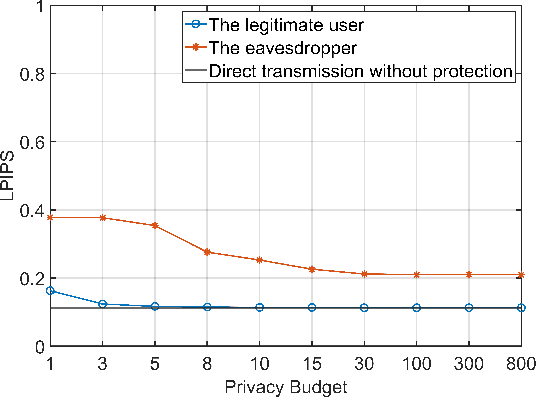
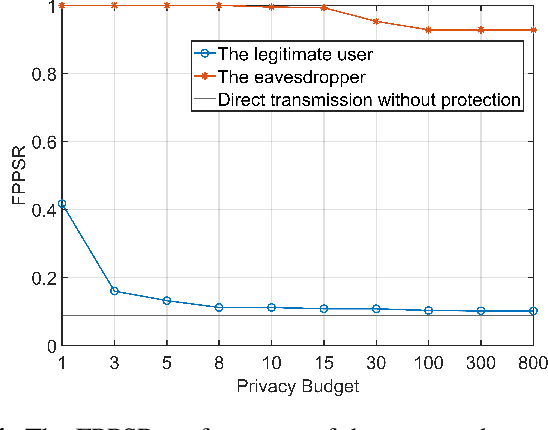
Semantic communication (SemCom) enhances transmission efficiency by sending only task-relevant information compared to traditional methods. However, transmitting semantic-rich data over insecure or public channels poses security and privacy risks. This paper addresses the privacy problem of transmitting images over wiretap channels and proposes a novel SemCom approach ensuring privacy through a differential privacy (DP)-based image protection and deprotection mechanism. The method utilizes the GAN inversion technique to extract disentangled semantic features and applies a DP mechanism to protect sensitive features within the extracted semantic information. To address the non-invertibility of DP, we introduce two neural networks to approximate the DP application and removal processes, offering a privacy protection level close to that by the original DP process. Simulation results validate the effectiveness of our method in preventing eavesdroppers from obtaining sensitive information while maintaining high-fidelity image reconstruction at the legitimate receiver.
A Nearly Information Theoretically Secure Approach for Semantic Communications over Wiretap Channel
Jan 25, 2024This paper addresses the challenge of achieving information-theoretic security in semantic communication (SeCom) over a wiretap channel, where a legitimate receiver coexists with an eavesdropper experiencing a poorer channel condition. Despite previous efforts to secure SeCom against eavesdroppers, achieving information-theoretic security in such schemes remains an open issue. In this work, we propose a secure digital SeCom approach based on superposition codes, aiming to attain nearly information-theoretic security. Our proposed method involves associating semantic information with satellite constellation points within a double-layered constellation map, where cloud center constellation points are randomly selected. By carefully allocating power between these two layers of constellation, we ensure that the symbol error probability (SEP) of the eavesdropper decoding satellite constellation points is nearly equivalent to random guessing, while maintaining a low SEP for the legitimate receiver to successfully decode the semantic information. Simulation results showcase that the Peak Signal-to-Noise Ratio (PSNR) and Mean Squared Error (MSE) for the eavesdropper's reconstructed data, using our proposed method, can range from decoding Gaussian-distributed random noise to approaching the variance of the data. This validates the ability of our method to achieve nearly information-theoretic security, demonstrating superior data security compared to benchmark methods.