 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCache-enabled Generative Joint Source-Channel Coding for Evolving Semantic Communications
Mar 18, 2026Learning-based semantic communication (SemCom) has recently emerged as a promising paradigm for improving the transmission efficiency of wireless networks. However, existing methods typically rely on extensive end-to-end training, which is both inflexible and computationally expensive in dynamic wireless environments. Moreover, they fail to exploit redundancy across multiple transmissions of semantically similar content, limiting overall efficiency. To overcome these limitations, we propose a channel-aware generative adversarial network (GAN) inversion-based joint source-channel coding (CAGI-JSCC) framework that enables training-free SemCom by leveraging a pre-trained SemanticStyleGAN model. By explicitly incorporating wireless channel characteristics into the GAN inversion process, CAGI-JSCC adapts to varying channel conditions without additional training. Furthermore, we introduce a cache-enabled dynamic codebook (CDC) that caches disentangled semantic components at both the transmitter and receiver, allowing the system to reuse previously transmitted content. This semantic-level caching can continuously reduce redundant transmissions as experience accumulates. Extensive experiments on image transmission demonstrate the effectiveness of the proposed framework. In particular, our system achieves comparable perceptual quality with an average bandwidth compression ratio (BCR) of 1/224, and as low as 1/1024 for a single image, significantly outperforming baselines with a BCR of 1/128.
Rethinking Secure Semantic Communications in the Age of Generative and Agentic AI: Threats and Opportunities
Jan 06, 2026Semantic communication (SemCom) improves communication efficiency by transmitting task-relevant information instead of raw bits and is expected to be a key technology for 6G networks. Recent advances in generative AI (GenAI) further enhance SemCom by enabling robust semantic encoding and decoding under limited channel conditions. However, these efficiency gains also introduce new security and privacy vulnerabilities. Due to the broadcast nature of wireless channels, eavesdroppers can also use powerful GenAI-based semantic decoders to recover private information from intercepted signals. Moreover, rapid advances in agentic AI enable eavesdroppers to perform long-term and adaptive inference through the integration of memory, external knowledge, and reasoning capabilities. This allows eavesdroppers to further infer user private behavior and intent beyond the transmitted content. Motivated by these emerging challenges, this paper comprehensively rethinks the security and privacy of SemCom systems in the age of generative and agentic AI. We first present a systematic taxonomy of eavesdropping threat models in SemCom systems. Then, we provide insights into how GenAI and agentic AI can enhance eavesdropping threats. Meanwhile, we also highlight potential opportunities for leveraging GenAI and agentic AI to design privacy-preserving SemCom systems.
Enabling Training-Free Semantic Communication Systems with Generative Diffusion Models
May 05, 2025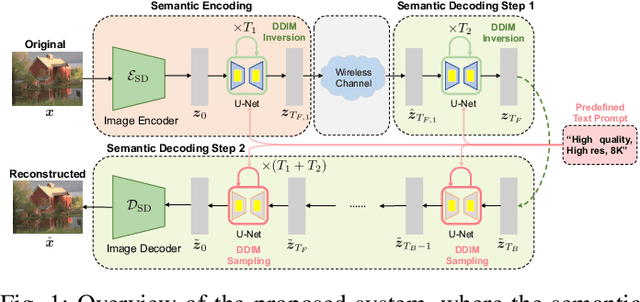
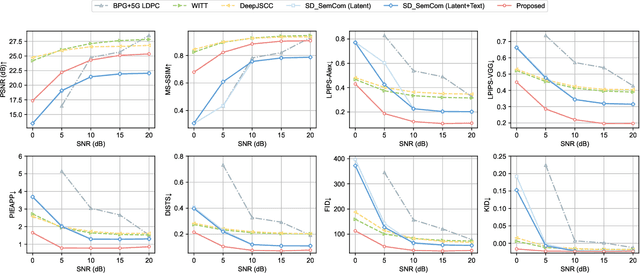


Semantic communication (SemCom) has recently emerged as a promising paradigm for next-generation wireless systems. Empowered by advanced artificial intelligence (AI) technologies, SemCom has achieved significant improvements in transmission quality and efficiency. However, existing SemCom systems either rely on training over large datasets and specific channel conditions or suffer from performance degradation under channel noise when operating in a training-free manner. To address these issues, we explore the use of generative diffusion models (GDMs) as training-free SemCom systems. Specifically, we design a semantic encoding and decoding method based on the inversion and sampling process of the denoising diffusion implicit model (DDIM), which introduces a two-stage forward diffusion process, split between the transmitter and receiver to enhance robustness against channel noise. Moreover, we optimize sampling steps to compensate for the increased noise level caused by channel noise. We also conduct a brief analysis to provide insights about this design. Simulations on the Kodak dataset validate that the proposed system outperforms the existing baseline SemCom systems across various metrics.
Enhancing Privacy in Semantic Communication over Wiretap Channels leveraging Differential Privacy
Apr 23, 2025



Semantic communication (SemCom) improves transmission efficiency by focusing on task-relevant information. However, transmitting semantic-rich data over insecure channels introduces privacy risks. This paper proposes a novel SemCom framework that integrates differential privacy (DP) mechanisms to protect sensitive semantic features. This method employs the generative adversarial network (GAN) inversion technique to extract disentangled semantic features and uses neural networks (NNs) to approximate the DP application and removal processes, effectively mitigating the non-invertibility issue of DP. Additionally, an NN-based encryption scheme is introduced to strengthen the security of channel inputs. Simulation results demonstrate that the proposed approach effectively prevents eavesdroppers from reconstructing sensitive information by generating chaotic or fake images, while ensuring high-quality image reconstruction for legitimate users. The system exhibits robust performance across various privacy budgets and channel conditions, achieving an optimal balance between privacy protection and reconstruction fidelity.
Towards Secure Semantic Communications in the Presence of Intelligent Eavesdroppers
Mar 29, 2025Semantic communication has emerged as a promising paradigm for enhancing communication efficiency in sixth-generation (6G) networks. However, the broadcast nature of wireless channels makes SemCom systems vulnerable to eavesdropping, which poses a serious threat to data privacy. Therefore, we investigate secure SemCom systems that preserve data privacy in the presence of eavesdroppers. Specifically, we first explore a scenario where eavesdroppers are intelligent and can exploit semantic information to reconstruct the transmitted data based on advanced artificial intelligence (AI) techniques. To counter this, we introduce novel eavesdropping attack strategies that utilize model inversion attacks and generative AI (GenAI) models. These strategies effectively reconstruct transmitted private data processed by the semantic encoder, operating in both glass-box and closed-box settings. Existing defense mechanisms against eavesdropping often cause significant distortions in the data reconstructed by eavesdroppers, potentially arousing their suspicion. To address this, we propose a semantic covert communication approach that leverages an invertible neural network (INN)-based signal steganography module. This module covertly embeds the channel input signal of a private sample into that of a non-sensitive host sample, thereby misleading eavesdroppers. Without access to this module, eavesdroppers can only extract host-related information and remain unaware of the hidden private content. We conduct extensive simulations under various channel conditions in image transmission tasks. Numerical results show that while conventional eavesdropping strategies achieve a success rate of over 80\% in reconstructing private information, the proposed semantic covert communication effectively reduces the eavesdropping success rate to 0.
Toward Agentic AI: Generative Information Retrieval Inspired Intelligent Communications and Networking
Feb 24, 2025



The increasing complexity and scale of modern telecommunications networks demand intelligent automation to enhance efficiency, adaptability, and resilience. Agentic AI has emerged as a key paradigm for intelligent communications and networking, enabling AI-driven agents to perceive, reason, decide, and act within dynamic networking environments. However, effective decision-making in telecom applications, such as network planning, management, and resource allocation, requires integrating retrieval mechanisms that support multi-hop reasoning, historical cross-referencing, and compliance with evolving 3GPP standards. This article presents a forward-looking perspective on generative information retrieval-inspired intelligent communications and networking, emphasizing the role of knowledge acquisition, processing, and retrieval in agentic AI for telecom systems. We first provide a comprehensive review of generative information retrieval strategies, including traditional retrieval, hybrid retrieval, semantic retrieval, knowledge-based retrieval, and agentic contextual retrieval. We then analyze their advantages, limitations, and suitability for various networking scenarios. Next, we present a survey about their applications in communications and networking. Additionally, we introduce an agentic contextual retrieval framework to enhance telecom-specific planning by integrating multi-source retrieval, structured reasoning, and self-reflective validation. Experimental results demonstrate that our framework significantly improves answer accuracy, explanation consistency, and retrieval efficiency compared to traditional and semantic retrieval methods. Finally, we outline future research directions.
Retrieval-augmented Generation for GenAI-enabled Semantic Communications
Dec 27, 2024



Semantic communication (SemCom) is an emerging paradigm aiming at transmitting only task-relevant semantic information to the receiver, which can significantly improve communication efficiency. Recent advancements in generative artificial intelligence (GenAI) have empowered GenAI-enabled SemCom (GenSemCom) to further expand its potential in various applications. However, current GenSemCom systems still face challenges such as semantic inconsistency, limited adaptability to diverse tasks and dynamic environments, and the inability to leverage insights from past transmission. Motivated by the success of retrieval-augmented generation (RAG) in the domain of GenAI, this paper explores the integration of RAG in GenSemCom systems. Specifically, we first provide a comprehensive review of existing GenSemCom systems and the fundamentals of RAG techniques. We then discuss how RAG can be integrated into GenSemCom. Following this, we conduct a case study on semantic image transmission using an RAG-enabled diffusion-based SemCom system, demonstrating the effectiveness of the proposed integration. Finally, we outline future directions for advancing RAG-enabled GenSemCom systems.
Enhancing Image Privacy in Semantic Communication over Wiretap Channels leveraging Differential Privacy
May 15, 2024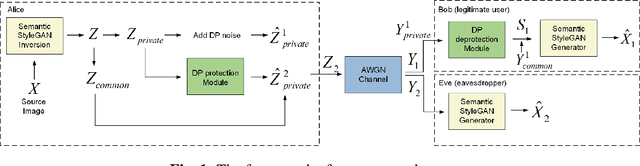
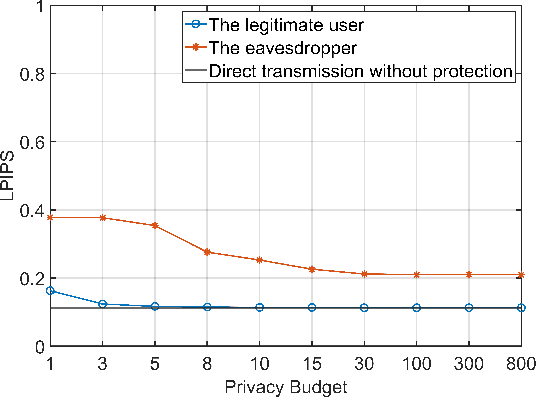
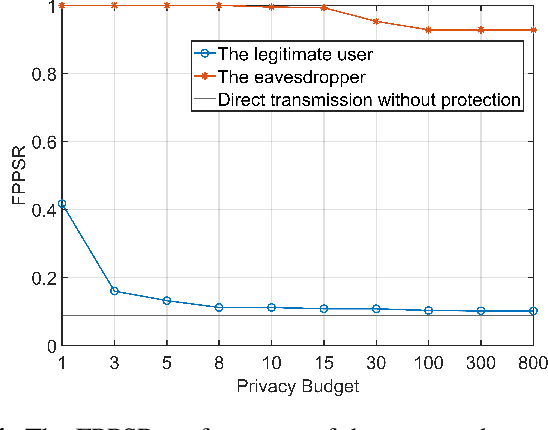
Semantic communication (SemCom) enhances transmission efficiency by sending only task-relevant information compared to traditional methods. However, transmitting semantic-rich data over insecure or public channels poses security and privacy risks. This paper addresses the privacy problem of transmitting images over wiretap channels and proposes a novel SemCom approach ensuring privacy through a differential privacy (DP)-based image protection and deprotection mechanism. The method utilizes the GAN inversion technique to extract disentangled semantic features and applies a DP mechanism to protect sensitive features within the extracted semantic information. To address the non-invertibility of DP, we introduce two neural networks to approximate the DP application and removal processes, offering a privacy protection level close to that by the original DP process. Simulation results validate the effectiveness of our method in preventing eavesdroppers from obtaining sensitive information while maintaining high-fidelity image reconstruction at the legitimate receiver.
FeDeRA:Efficient Fine-tuning of Language Models in Federated Learning Leveraging Weight Decomposition
Apr 30, 2024Pre-trained Language Models (PLMs) have shown excellent performance on various downstream tasks after fine-tuning. Nevertheless, the escalating concerns surrounding user privacy have posed significant challenges to centralized training reliant on extensive data collection. Federated learning, which only requires training on the clients and aggregates weights on the server without sharing data, has emerged as a solution. However, the substantial parameter size of PLMs places a significant burden on the computational resources of client devices, while also leading to costly communication expenses. Introducing Parameter-Efficient Fine-Tuning(PEFT) into federated learning can effectively address this problem. However, we observe that the non-IID data in federated learning leads to a gap in performance between the PEFT method and full parameter fine-tuning(FFT). To overcome this, we propose FeDeRA, an improvement over the Low-Rank Adaption(LoRA) method in federated learning. FeDeRA uses the same adapter module as LoRA. However, the difference lies in FeDeRA's initialization of the adapter module by performing Singular Value Decomposition (SVD) on the pre-trained matrix and selecting its principal components. We conducted extensive experiments, using RoBERTa and DeBERTaV3, on six datasets, comparing the methods including FFT and the other three different PEFT methods. FeDeRA outperforms all other PEFT methods and is comparable to or even surpasses the performance of FFT method. We also deployed federated learning on Jetson AGX Orin and compared the time required by different methods to achieve the target accuracy on specific tasks. Compared to FFT, FeDeRA reduces the training time by 95.9\%, 97.9\%, 96.9\% and 97.3\%, 96.5\%, 96.5\% respectively on three tasks using RoBERTa and DeBERTaV3. The overall experiments indicate that FeDeRA achieves good performance while also maintaining efficiency.
Secure Semantic Communication for Image Transmission in the Presence of Eavesdroppers
Apr 18, 2024Semantic communication (SemCom) has emerged as a key technology for the forthcoming sixth-generation (6G) network, attributed to its enhanced communication efficiency and robustness against channel noise. However, the open nature of wireless channels renders them vulnerable to eavesdropping, posing a serious threat to privacy. To address this issue, we propose a novel secure semantic communication (SemCom) approach for image transmission, which integrates steganography technology to conceal private information within non-private images (host images). Specifically, we propose an invertible neural network (INN)-based signal steganography approach, which embeds channel input signals of a private image into those of a host image before transmission. This ensures that the original private image can be reconstructed from the received signals at the legitimate receiver, while the eavesdropper can only decode the information of the host image. Simulation results demonstrate that the proposed approach maintains comparable reconstruction quality of both host and private images at the legitimate receiver, compared to scenarios without any secure mechanisms. Experiments also show that the eavesdropper is only able to reconstruct host images, showcasing the enhanced security provided by our approach.