 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Secure Semantic Communications in the Age of Generative and Agentic AI: Threats and Opportunities
Jan 06, 2026Semantic communication (SemCom) improves communication efficiency by transmitting task-relevant information instead of raw bits and is expected to be a key technology for 6G networks. Recent advances in generative AI (GenAI) further enhance SemCom by enabling robust semantic encoding and decoding under limited channel conditions. However, these efficiency gains also introduce new security and privacy vulnerabilities. Due to the broadcast nature of wireless channels, eavesdroppers can also use powerful GenAI-based semantic decoders to recover private information from intercepted signals. Moreover, rapid advances in agentic AI enable eavesdroppers to perform long-term and adaptive inference through the integration of memory, external knowledge, and reasoning capabilities. This allows eavesdroppers to further infer user private behavior and intent beyond the transmitted content. Motivated by these emerging challenges, this paper comprehensively rethinks the security and privacy of SemCom systems in the age of generative and agentic AI. We first present a systematic taxonomy of eavesdropping threat models in SemCom systems. Then, we provide insights into how GenAI and agentic AI can enhance eavesdropping threats. Meanwhile, we also highlight potential opportunities for leveraging GenAI and agentic AI to design privacy-preserving SemCom systems.
Enabling Training-Free Semantic Communication Systems with Generative Diffusion Models
May 05, 2025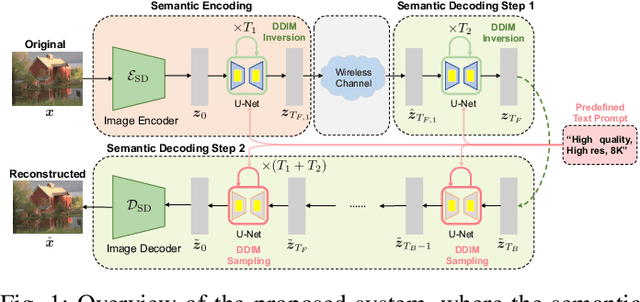
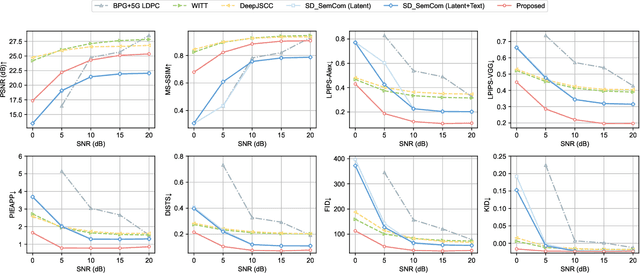


Semantic communication (SemCom) has recently emerged as a promising paradigm for next-generation wireless systems. Empowered by advanced artificial intelligence (AI) technologies, SemCom has achieved significant improvements in transmission quality and efficiency. However, existing SemCom systems either rely on training over large datasets and specific channel conditions or suffer from performance degradation under channel noise when operating in a training-free manner. To address these issues, we explore the use of generative diffusion models (GDMs) as training-free SemCom systems. Specifically, we design a semantic encoding and decoding method based on the inversion and sampling process of the denoising diffusion implicit model (DDIM), which introduces a two-stage forward diffusion process, split between the transmitter and receiver to enhance robustness against channel noise. Moreover, we optimize sampling steps to compensate for the increased noise level caused by channel noise. We also conduct a brief analysis to provide insights about this design. Simulations on the Kodak dataset validate that the proposed system outperforms the existing baseline SemCom systems across various metrics.
FHEDN: A based on context modeling Feature Hierarchy Encoder-Decoder Network for face detection
Dec 11, 2017

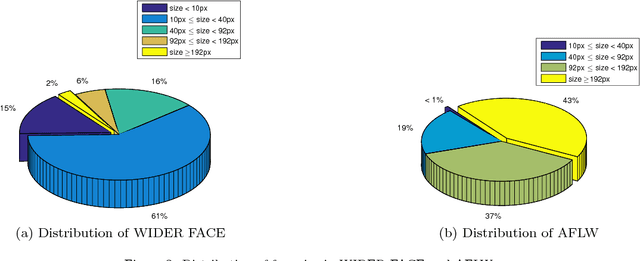
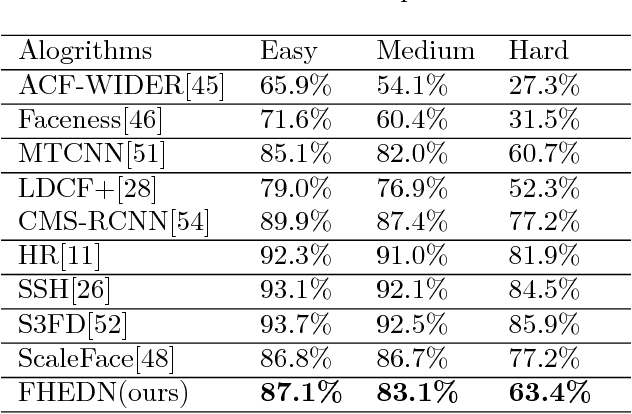
Because of affected by weather conditions, camera pose and range, etc. Objects are usually small, blur, occluded and diverse pose in the images gathered from outdoor surveillance cameras or access control system. It is challenging and important to detect faces precisely for face recognition system in the field of public security. In this paper, we design a based on context modeling structure named Feature Hierarchy Encoder-Decoder Network for face detection(FHEDN), which can detect small, blur and occluded face with hierarchy by hierarchy from the end to the beginning likes encoder-decoder in a single network. The proposed network is consist of multiple context modeling and prediction modules, which are in order to detect small, blur, occluded and diverse pose faces. In addition, we analyse the influence of distribution of training set, scale of default box and receipt field size to detection performance in implement stage. Demonstrated by experiments, Our network achieves promising performance on WIDER FACE and FDDB benchmarks.