 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMD-SLAM: Structure-Enhanced Multi-Meta Gaussian Distribution-Guided Visual SLAM
Jun 18, 20263D Gaussian Splatting (3DGS) has significantly boosted novel view synthesis and high-fidelity scene reconstruction, expanding the potential of 3DGS-based Visual Simultaneous Localization and Mapping (SLAM) methods. However, most existing systems fail to fully exploit the underlying structural information, which limits rendering quality and often leads to inconsistent maps. To address these limitations, we propose MMD-SLAM, a structure-enhanced Visual SLAM framework that leverages the Atlanta World (AW) assumption to guide a Multi-Meta Gaussian representation for photorealistic mapping. First, we introduce a point-line fusion strategy for pose optimization, where 3D line segments are incorporated to improve tracking robustness and provide additional constraints for mapping. Second, we design a Multi-Meta Gaussian representation with dominant directions, explicitly encoding structural priors from the AW hypothesis. Finally, we propose a Gaussian evolution strategy that adapts to scene geometry and incorporates structural cues into global optimization. Extensive experiments demonstrate that these innovations enable MMD-SLAM to achieve state-of-the-art performance in both tracking accuracy and mapping quality. e.g., our method achieves a 48.56% reduction in ATE RMSE on ScanNet and a 5.71% improvement in PSNR on Replica, compared with MonoGS.
CurvZO: Adaptive Curvature-Guided Sparse Zeroth-Order Optimization for Efficient LLM Fine-Tuning
Mar 23, 2026Fine-tuning large language models (LLMs) with backpropagation achieves high performance but incurs substantial memory overhead, limiting scalability on resource-constrained hardware. Zeroth-order (ZO) optimization provides a memory-efficient alternative by relying solely on forward passes, yet it typically suffers from slow or unstable convergence due to high-variance gradient estimates. Sparse ZO updates partially address this issue by perturbing only a subset of parameters, but their effectiveness hinges on selecting informative parameters, which is challenging in ZO optimization because each query yields only scalar feedback. We propose \textbf{Adaptive Curvature-Guided Sparse Zeroth-Order Optimization (CurvZO)}, which tracks curvature signals online from scalar ZO feedback and leverages these signals to construct a parameter-wise sampling distribution for selecting coordinates at each update, reducing the variance of the sparse ZO gradient estimator. Moreover, CurvZO dynamically adapts the perturbation budget to the evolving curvature signal distribution, yielding sparse ZO updates that remain both focused and sufficiently exploratory. Extensive experiments on OPT and Llama across diverse NLP tasks show that CurvZO consistently improves fine-tuning performance and reduces training time over ZO baselines. It improves accuracy by up to 4.4 points and achieves up to a $2\times$ speedup, while preserving memory efficiency.
Signals of Success and Struggle: Early Prediction and Physiological Signatures of Human Performance across Task Complexity
Mar 19, 2026User performance is crucial in interactive systems, capturing how effectively users engage with task execution. Prospectively predicting performance enables the timely identification of users struggling with task demands. While ocular and cardiac signals are widely used to characterise performance-relevant visual behaviour and physiological activation, their potential for early prediction and for revealing the physiological mechanisms underlying performance differences remains underexplored. We conducted a within-subject experiment in a game environment with naturally unfolding complexity, using early ocular and cardiac signals to predict later performance and to examine physiological and self-reported group differences. Results show that the ocular-cardiac fusion model achieves a balanced accuracy of 0.86, and the ocular-only model shows comparable predictive power. High performers exhibited targeted gaze and adjusted visual sampling, and sustained more stable cardiac activation as demands intensified, with a more positive affective experience. These findings demonstrate the feasibility of cross-session prediction from early physiology, providing interpretable insights into performance variation and facilitating future proactive intervention.
LR-SGS: Robust LiDAR-Reflectance-Guided Salient Gaussian Splatting for Self-Driving Scene Reconstruction
Mar 13, 2026Recent 3D Gaussian Splatting (3DGS) methods have demonstrated the feasibility of self-driving scene reconstruction and novel view synthesis. However, most existing methods either rely solely on cameras or use LiDAR only for Gaussian initialization or depth supervision, while the rich scene information contained in point clouds, such as reflectance, and the complementarity between LiDAR and RGB have not been fully exploited, leading to degradation in challenging self-driving scenes, such as those with high ego-motion and complex lighting. To address these issues, we propose a robust and efficient LiDAR-reflectance-guided Salient Gaussian Splatting method (LR-SGS) for self-driving scenes, which introduces a structure-aware Salient Gaussian representation, initialized from geometric and reflectance feature points extracted from LiDAR and refined through a salient transform and improved density control to capture edge and planar structures. Furthermore, we calibrate LiDAR intensity into reflectance and attach it to each Gaussian as a lighting-invariant material channel, jointly aligned with RGB to enforce boundary consistency. Extensive experiments on the Waymo Open Dataset demonstrate that LR-SGS achieves superior reconstruction performance with fewer Gaussians and shorter training time. In particular, on Complex Lighting scenes, our method surpasses OmniRe by 1.18 dB PSNR.
SciMDR: Benchmarking and Advancing Scientific Multimodal Document Reasoning
Mar 12, 2026Constructing scientific multimodal document reasoning datasets for foundation model training involves an inherent trade-off among scale, faithfulness, and realism. To address this challenge, we introduce the synthesize-and-reground framework, a two-stage pipeline comprising: (1) Claim-Centric QA Synthesis, which generates faithful, isolated QA pairs and reasoning on focused segments, and (2) Document-Scale Regrounding, which programmatically re-embeds these pairs into full-document tasks to ensure realistic complexity. Using this framework, we construct SciMDR, a large-scale training dataset for cross-modal comprehension, comprising 300K QA pairs with explicit reasoning chains across 20K scientific papers. We further construct SciMDR-Eval, an expert-annotated benchmark to evaluate multimodal comprehension within full-length scientific workflows. Experiments demonstrate that models fine-tuned on SciMDR achieve significant improvements across multiple scientific QA benchmarks, particularly in those tasks requiring complex document-level reasoning.
RealWonder: Real-Time Physical Action-Conditioned Video Generation
Mar 05, 2026Current video generation models cannot simulate physical consequences of 3D actions like forces and robotic manipulations, as they lack structural understanding of how actions affect 3D scenes. We present RealWonder, the first real-time system for action-conditioned video generation from a single image. Our key insight is using physics simulation as an intermediate bridge: instead of directly encoding continuous actions, we translate them through physics simulation into visual representations (optical flow and RGB) that video models can process. RealWonder integrates three components: 3D reconstruction from single images, physics simulation, and a distilled video generator requiring only 4 diffusion steps. Our system achieves 13.2 FPS at 480x832 resolution, enabling interactive exploration of forces, robot actions, and camera controls on rigid objects, deformable bodies, fluids, and granular materials. We envision RealWonder opens new opportunities to apply video models in immersive experiences, AR/VR, and robot learning. Our code and model weights are publicly available in our project website: https://liuwei283.github.io/RealWonder/
Optimizing Decoding Paths in Masked Diffusion Models by Quantifying Uncertainty
Dec 24, 2025Masked Diffusion Models (MDMs) offer flexible, non-autoregressive generation, but this freedom introduces a challenge: final output quality is highly sensitive to the decoding order. We are the first to formalize this issue, attributing the variability in output quality to the cumulative predictive uncertainty along a generative path. To quantify this uncertainty, we introduce Denoising Entropy, a computable metric that serves as an internal signal for evaluating generative process. Leveraging this metric, we propose two algorithms designed to optimize the decoding path: a post-hoc selection method and a real-time guidance strategy. Experiments demonstrate that our entropy-guided methods significantly improve generation quality, consistently boosting accuracy on challenging reasoning, planning, and code benchmarks. Our work establishes Denoising Entropy as a principled tool for understanding and controlling generation, effectively turning the uncertainty in MDMs from a liability into a key advantage for discovering high-quality solutions.
A Survey on Reconfigurable Intelligent Surfaces in Practical Systems: Security and Privacy Perspectives
Dec 12, 2025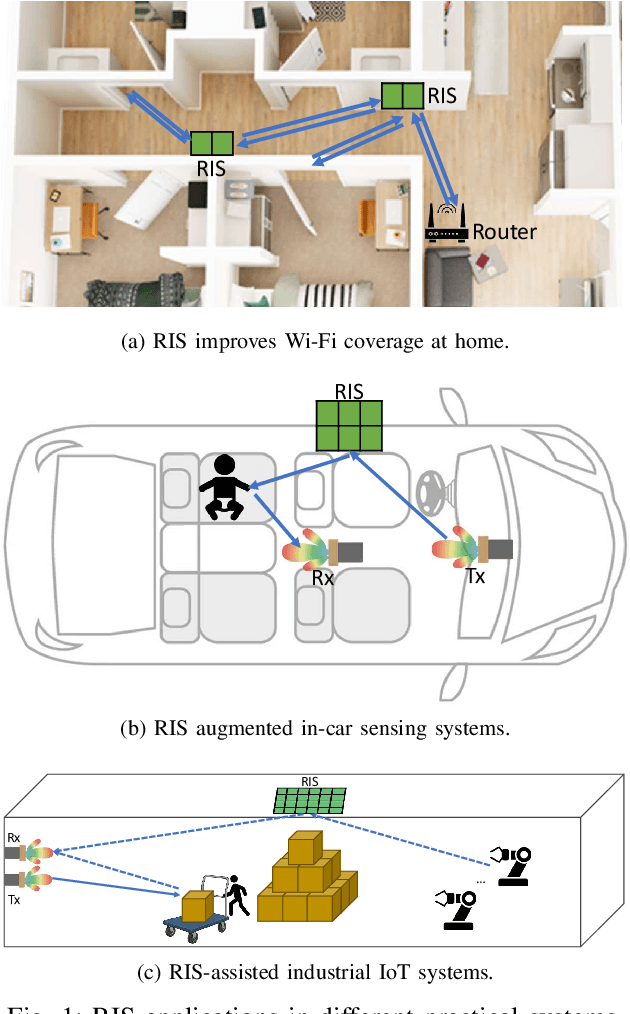
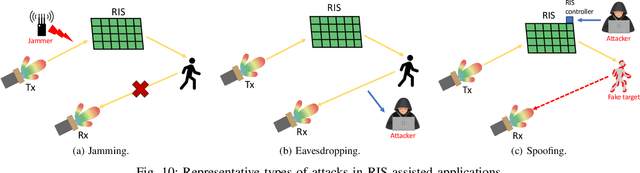
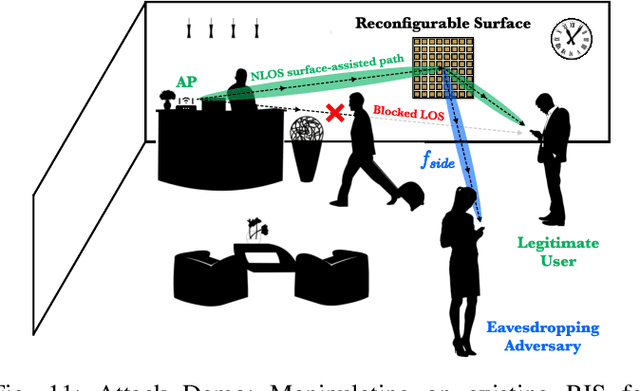
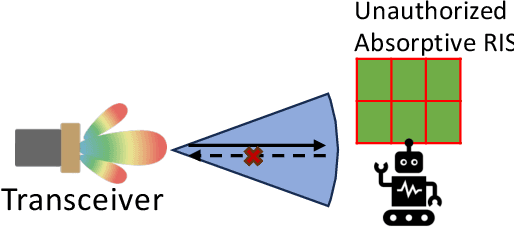
Reconfigurable Intelligent Surfaces (RIS) have emerged as a transformative technology capable of reshaping wireless environments through dynamic manipulation of electromagnetic waves. While extensive research has explored their theoretical benefits for communication and sensing, practical deployments in smart environments such as homes, vehicles, and industrial settings remain limited and under-examined, particularly from security and privacy perspectives. This survey provides a comprehensive examination of RIS applications in real-world systems, with a focus on the security and privacy threats, vulnerabilities, and defensive strategies relevant to practical use. We analyze scenarios with two types of systems (with and without legitimate RIS) and two types of attackers (with and without malicious RIS), and demonstrate how RIS may introduce new attacks to practical systems, including eavesdropping, jamming, and spoofing attacks. In response, we review defenses against RIS-related attacks in these systems, such as applying additional security algorithms, disrupting attackers, and early detection of unauthorized RIS. We also discuss scenarios in which the legitimate user applies an additional RIS to defend against attacks. To support future research, we also provide a collection of open-source tools, datasets, demos, and papers at: https://awesome-ris-security.github.io/. By highlighting RIS's functionality and its security/privacy challenges and opportunities, this survey aims to guide researchers and engineers toward the development of secure, resilient, and privacy-preserving RIS-enabled practical wireless systems and environments.
Towards Efficient and Effective Multi-Camera Encoding for End-to-End Driving
Dec 12, 2025We present Flex, an efficient and effective scene encoder that addresses the computational bottleneck of processing high-volume multi-camera data in end-to-end autonomous driving. Flex employs a small set of learnable scene tokens to jointly encode information from all image tokens across different cameras and timesteps. By design, our approach is geometry-agnostic, learning a compact scene representation directly from data without relying on the explicit 3D inductive biases, such as Bird-Eye-View (BEV), occupancy or tri-plane representations, which are common in prior work. This holistic encoding strategy aggressively compresses the visual input for the downstream Large Language Model (LLM) based policy model. Evaluated on a large-scale proprietary dataset of 20,000 driving hours, our Flex achieves 2.2x greater inference throughput while improving driving performance by a large margin compared to state-of-the-art methods. Furthermore, we show that these compact scene tokens develop an emergent capability for scene decomposition without any explicit supervision. Our findings challenge the prevailing assumption that 3D priors are necessary, demonstrating that a data-driven, joint encoding strategy offers a more scalable, efficient and effective path for future autonomous driving systems.
FASIONAD++ : Integrating High-Level Instruction and Information Bottleneck in FAt-Slow fusION Systems for Enhanced Safety in Autonomous Driving with Adaptive Feedback
Mar 11, 2025



Ensuring safe, comfortable, and efficient planning is crucial for autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving scenarios, they struggle with complex low-frequency events. Recent Large Language Models (LLMs) and Vision Language Models (VLMs) advancements offer enhanced reasoning but suffer from computational inefficiency. Inspired by the dual-process cognitive model "Thinking, Fast and Slow", we propose $\textbf{FASIONAD}$ -- a novel dual-system framework that synergizes a fast end-to-end planner with a VLM-based reasoning module. The fast system leverages end-to-end learning to achieve real-time trajectory generation in common scenarios, while the slow system activates through uncertainty estimation to perform contextual analysis and complex scenario resolution. Our architecture introduces three key innovations: (1) A dynamic switching mechanism enabling slow system intervention based on real-time uncertainty assessment; (2) An information bottleneck with high-level plan feedback that optimizes the slow system's guidance capability; (3) A bidirectional knowledge exchange where visual prompts enhance the slow system's reasoning while its feedback refines the fast planner's decision-making. To strengthen VLM reasoning, we develop a question-answering mechanism coupled with reward-instruct training strategy. In open-loop experiments, FASIONAD achieves a $6.7\%$ reduction in average $L2$ trajectory error and $28.1\%$ lower collision rate.