 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTPano: Multi-Task Panoramic Scene Understanding via Label-Free Integration of Dense Prediction Priors
Feb 05, 2026Comprehensive panoramic scene understanding is critical for immersive applications, yet it remains challenging due to the scarcity of high-resolution, multi-task annotations. While perspective foundation models have achieved success through data scaling, directly adapting them to the panoramic domain often fails due to severe geometric distortions and coordinate system discrepancies. Furthermore, the underlying relations between diverse dense prediction tasks in spherical spaces are underexplored. To address these challenges, we propose MTPano, a robust multi-task panoramic foundation model established by a label-free training pipeline. First, to circumvent data scarcity, we leverage powerful perspective dense priors. We project panoramic images into perspective patches to generate accurate, domain-gap-free pseudo-labels using off-the-shelf foundation models, which are then re-projected to serve as patch-wise supervision. Second, to tackle the interference between task types, we categorize tasks into rotation-invariant (e.g., depth, segmentation) and rotation-variant (e.g., surface normals) groups. We introduce the Panoramic Dual BridgeNet, which disentangles these feature streams via geometry-aware modulation layers that inject absolute position and ray direction priors. To handle the distortion from equirectangular projections (ERP), we incorporate ERP token mixers followed by a dual-branch BridgeNet for interactions with gradient truncation, facilitating beneficial cross-task information sharing while blocking conflicting gradients from incompatible task attributes. Additionally, we introduce auxiliary tasks (image gradient, point map, etc.) to fertilize the cross-task learning process. Extensive experiments demonstrate that MTPano achieves state-of-the-art performance on multiple benchmarks and delivers competitive results against task-specific panoramic specialist foundation models.
SPGen: Spherical Projection as Consistent and Flexible Representation for Single Image 3D Shape Generation
Sep 16, 2025
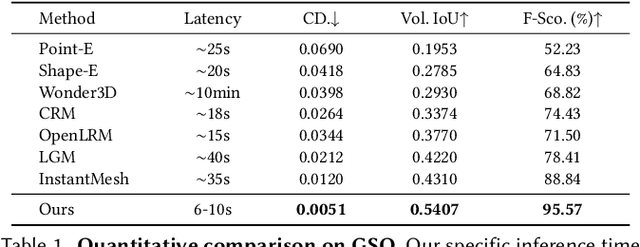
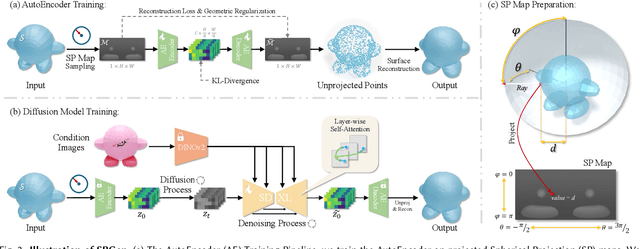
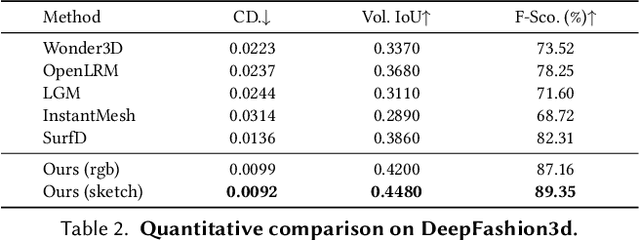
Existing single-view 3D generative models typically adopt multiview diffusion priors to reconstruct object surfaces, yet they remain prone to inter-view inconsistencies and are unable to faithfully represent complex internal structure or nontrivial topologies. In particular, we encode geometry information by projecting it onto a bounding sphere and unwrapping it into a compact and structural multi-layer 2D Spherical Projection (SP) representation. Operating solely in the image domain, SPGen offers three key advantages simultaneously: (1) Consistency. The injective SP mapping encodes surface geometry with a single viewpoint which naturally eliminates view inconsistency and ambiguity; (2) Flexibility. Multi-layer SP maps represent nested internal structures and support direct lifting to watertight or open 3D surfaces; (3) Efficiency. The image-domain formulation allows the direct inheritance of powerful 2D diffusion priors and enables efficient finetuning with limited computational resources. Extensive experiments demonstrate that SPGen significantly outperforms existing baselines in geometric quality and computational efficiency.
Disentangled Clothed Avatar Generation from Text Descriptions
Dec 08, 2023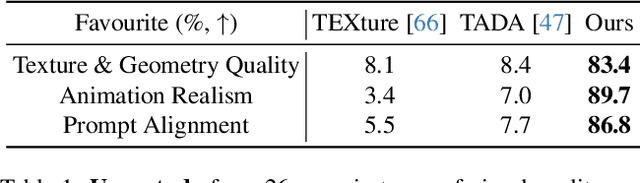
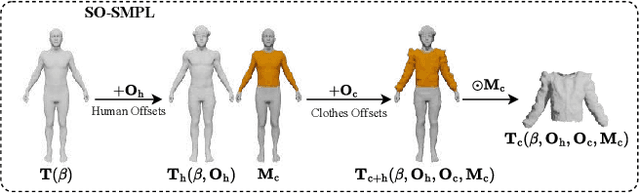
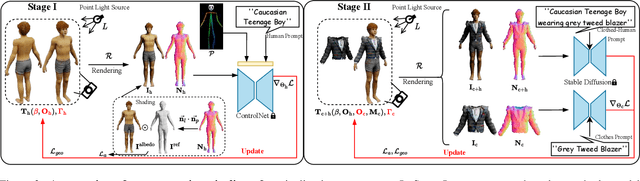

In this paper, we introduced a novel text-to-avatar generation method that separately generates the human body and the clothes and allows high-quality animation on the generated avatar. While recent advancements in text-to-avatar generation have yielded diverse human avatars from text prompts, these methods typically combine all elements-clothes, hair, and body-into a single 3D representation. Such an entangled approach poses challenges for downstream tasks like editing or animation. To overcome these limitations, we propose a novel disentangled 3D avatar representation named Sequentially Offset-SMPL (SO-SMPL), building upon the SMPL model. SO-SMPL represents the human body and clothes with two separate meshes, but associates them with offsets to ensure the physical alignment between the body and the clothes. Then, we design an Score Distillation Sampling(SDS)-based distillation framework to generate the proposed SO-SMPL representation from text prompts. In comparison with existing text-to-avatar methods, our approach not only achieves higher exture and geometry quality and better semantic alignment with text prompts, but also significantly improves the visual quality of character animation, virtual try-on, and avatar editing. Our project page is at https://shanemankiw.github.io/SO-SMPL/.
360-Degree Panorama Generation from Few Unregistered NFoV Images
Aug 28, 2023



360$^\circ$ panoramas are extensively utilized as environmental light sources in computer graphics. However, capturing a 360$^\circ$ $\times$ 180$^\circ$ panorama poses challenges due to the necessity of specialized and costly equipment, and additional human resources. Prior studies develop various learning-based generative methods to synthesize panoramas from a single Narrow Field-of-View (NFoV) image, but they are limited in alterable input patterns, generation quality, and controllability. To address these issues, we propose a novel pipeline called PanoDiff, which efficiently generates complete 360$^\circ$ panoramas using one or more unregistered NFoV images captured from arbitrary angles. Our approach has two primary components to overcome the limitations. Firstly, a two-stage angle prediction module to handle various numbers of NFoV inputs. Secondly, a novel latent diffusion-based panorama generation model uses incomplete panorama and text prompts as control signals and utilizes several geometric augmentation schemes to ensure geometric properties in generated panoramas. Experiments show that PanoDiff achieves state-of-the-art panoramic generation quality and high controllability, making it suitable for applications such as content editing.