 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Change Detection with Vision-Language Representation Learning
Apr 13, 2026Scene change detection (SCD) is crucial for urban monitoring and navigation but remains challenging in real-world environments due to lighting variations, seasonal shifts, viewpoint differences, and complex urban layouts. Existing methods rely primarily on low-level visual features, limiting their ability to accurately identify changed objects amid the visual complexity of urban scenes. In this paper, we propose LangSCD, a vision-language framework for scene change detection that overcomes this single-modal limitation by incorporating semantic reasoning through language. Our approach introduces a modular language component that leverages vision-language models (VLMs) to generate textual descriptions of scene changes, which are fused with visual features through a cross-modal feature enhancer. We further introduce a geometric-semantic matching module that refines the predicted masks by enforcing semantic consistency and spatial completeness. Existing real-world scene change detection benchmarks provide only binary change annotations, which are insufficient for downstream applications requiring fine-grained understanding of scene dynamics. To address this limitation, we introduce NYC-CD, a large-scale dataset of 8,122 real-world image pairs collected in New York City with multiclass change annotations generated through a semi-automatic pipeline. Extensive experiments across multiple street-view benchmarks demonstrate that our language and matching modules consistently improve existing change-detection architectures, achieving state-of-the-art performance and highlighting the value of integrating linguistic reasoning with visual representations for robust scene change detection.
SolidGS: Consolidating Gaussian Surfel Splatting for Sparse-View Surface Reconstruction
Dec 19, 2024



Gaussian splatting has achieved impressive improvements for both novel-view synthesis and surface reconstruction from multi-view images. However, current methods still struggle to reconstruct high-quality surfaces from only sparse view input images using Gaussian splatting. In this paper, we propose a novel method called SolidGS to address this problem. We observed that the reconstructed geometry can be severely inconsistent across multi-views, due to the property of Gaussian function in geometry rendering. This motivates us to consolidate all Gaussians by adopting a more solid kernel function, which effectively improves the surface reconstruction quality. With the additional help of geometrical regularization and monocular normal estimation, our method achieves superior performance on the sparse view surface reconstruction than all the Gaussian splatting methods and neural field methods on the widely used DTU, Tanks-and-Temples, and LLFF datasets.
AURORA: Automated Unleash of 3D Room Outlines for VR Applications
Dec 15, 2024Creating realistic VR experiences is challenging due to the labor-intensive process of accurately replicating real-world details into virtual scenes, highlighting the need for automated methods that maintain spatial accuracy and provide design flexibility. In this paper, we propose AURORA, a novel method that leverages RGB-D images to automatically generate both purely virtual reality (VR) scenes and VR scenes combined with real-world elements. This approach can benefit designers by streamlining the process of converting real-world details into virtual scenes. AURORA integrates advanced techniques in image processing, segmentation, and 3D reconstruction to efficiently create realistic and detailed interior designs from real-world environments. The design of this integration ensures optimal performance and precision, addressing key challenges in automated indoor design generation by uniquely combining and leveraging the strengths of foundation models. We demonstrate the effectiveness of our approach through experiments, both on self-captured data and public datasets, showcasing its potential to enhance virtual reality (VR) applications by providing interior designs that conform to real-world positioning.
CLAP: Concave Linear APproximation for Quadratic Graph Matching
Oct 22, 2024Solving point-wise feature correspondence in visual data is a fundamental problem in computer vision. A powerful model that addresses this challenge is to formulate it as graph matching, which entails solving a Quadratic Assignment Problem (QAP) with node-wise and edge-wise constraints. However, solving such a QAP can be both expensive and difficult due to numerous local extreme points. In this work, we introduce a novel linear model and solver designed to accelerate the computation of graph matching. Specifically, we employ a positive semi-definite matrix approximation to establish the structural attribute constraint.We then transform the original QAP into a linear model that is concave for maximization. This model can subsequently be solved using the Sinkhorn optimal transport algorithm, known for its enhanced efficiency and numerical stability compared to existing approaches. Experimental results on the widely used benchmark PascalVOC showcase that our algorithm achieves state-of-the-art performance with significantly improved efficiency. Source code: https://github.com/xmlyqing00/clap
A Survey on Computational Solutions for Reconstructing Complete Objects by Reassembling Their Fractured Parts
Oct 18, 2024Reconstructing a complete object from its parts is a fundamental problem in many scientific domains. The purpose of this article is to provide a systematic survey on this topic. The reassembly problem requires understanding the attributes of individual pieces and establishing matches between different pieces. Many approaches also model priors of the underlying complete object. Existing approaches are tightly connected problems of shape segmentation, shape matching, and learning shape priors. We provide existing algorithms in this context and emphasize their similarities and differences to general-purpose approaches. We also survey the trends from early non-deep learning approaches to more recent deep learning approaches. In addition to algorithms, this survey will also describe existing datasets, open-source software packages, and applications. To the best of our knowledge, this is the first comprehensive survey on this topic in computer graphics.
Deep video representation learning: a survey
May 10, 2024This paper provides a review on representation learning for videos. We classify recent spatiotemporal feature learning methods for sequential visual data and compare their pros and cons for general video analysis. Building effective features for videos is a fundamental problem in computer vision tasks involving video analysis and understanding. Existing features can be generally categorized into spatial and temporal features. Their effectiveness under variations of illumination, occlusion, view and background are discussed. Finally, we discuss the remaining challenges in existing deep video representation learning studies.
Enhancing Weakly Supervised Semantic Segmentation with Multi-modal Foundation Models: An End-to-End Approach
May 10, 2024



Semantic segmentation is a core computer vision problem, but the high costs of data annotation have hindered its wide application. Weakly-Supervised Semantic Segmentation (WSSS) offers a cost-efficient workaround to extensive labeling in comparison to fully-supervised methods by using partial or incomplete labels. Existing WSSS methods have difficulties in learning the boundaries of objects leading to poor segmentation results. We propose a novel and effective framework that addresses these issues by leveraging visual foundation models inside the bounding box. Adopting a two-stage WSSS framework, our proposed network consists of a pseudo-label generation module and a segmentation module. The first stage leverages Segment Anything Model (SAM) to generate high-quality pseudo-labels. To alleviate the problem of delineating precise boundaries, we adopt SAM inside the bounding box with the help of another pre-trained foundation model (e.g., Grounding-DINO). Furthermore, we eliminate the necessity of using the supervision of image labels, by employing CLIP in classification. Then in the second stage, the generated high-quality pseudo-labels are used to train an off-the-shelf segmenter that achieves the state-of-the-art performance on PASCAL VOC 2012 and MS COCO 2014.
Skull-to-Face: Anatomy-Guided 3D Facial Reconstruction and Editing
Mar 24, 2024Deducing the 3D face from a skull is an essential but challenging task in forensic science and archaeology. Existing methods for automated facial reconstruction yield inaccurate results, suffering from the non-determinative nature of the problem that a skull with a sparse set of tissue depth cannot fully determine the skinned face. Additionally, their texture-less results require further post-processing stages to achieve a photo-realistic appearance. This paper proposes an end-to-end 3D face reconstruction and exploration tool, providing textured 3D faces for reference. With the help of state-of-the-art text-to-image diffusion models and image-based facial reconstruction techniques, we generate an initial reference 3D face, whose biological profile aligns with the given skull. We then adapt these initial faces to meet the statistical expectations of extruded anatomical landmarks on the skull through an optimization process. The joint statistical distribution of tissue depths is learned on a small set of anatomical landmarks on the skull. To support further adjustment, we propose an efficient face adaptation tool to assist users in tuning tissue depths, either globally or at local regions, while observing plausible visual feedback. Experiments conducted on a real skull-face dataset demonstrated the effectiveness of our proposed pipeline in terms of reconstruction accuracy, diversity, and stability.
Disentangled Clothed Avatar Generation from Text Descriptions
Dec 08, 2023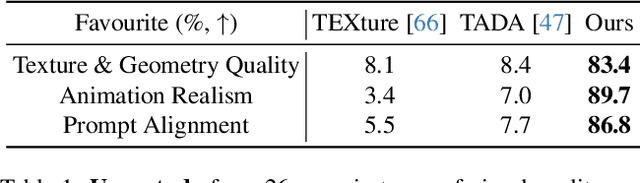
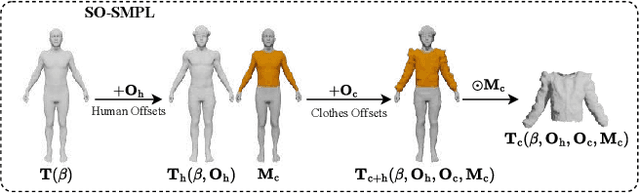
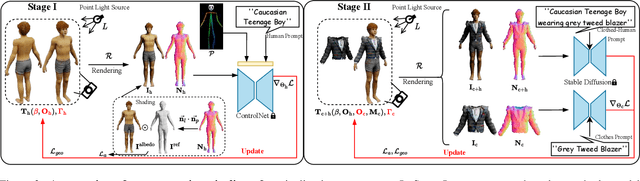

In this paper, we introduced a novel text-to-avatar generation method that separately generates the human body and the clothes and allows high-quality animation on the generated avatar. While recent advancements in text-to-avatar generation have yielded diverse human avatars from text prompts, these methods typically combine all elements-clothes, hair, and body-into a single 3D representation. Such an entangled approach poses challenges for downstream tasks like editing or animation. To overcome these limitations, we propose a novel disentangled 3D avatar representation named Sequentially Offset-SMPL (SO-SMPL), building upon the SMPL model. SO-SMPL represents the human body and clothes with two separate meshes, but associates them with offsets to ensure the physical alignment between the body and the clothes. Then, we design an Score Distillation Sampling(SDS)-based distillation framework to generate the proposed SO-SMPL representation from text prompts. In comparison with existing text-to-avatar methods, our approach not only achieves higher exture and geometry quality and better semantic alignment with text prompts, but also significantly improves the visual quality of character animation, virtual try-on, and avatar editing. Our project page is at https://shanemankiw.github.io/SO-SMPL/.
Video Object Segmentation with Adaptive Feature Bank and Uncertain-Region Refinement
Oct 15, 2020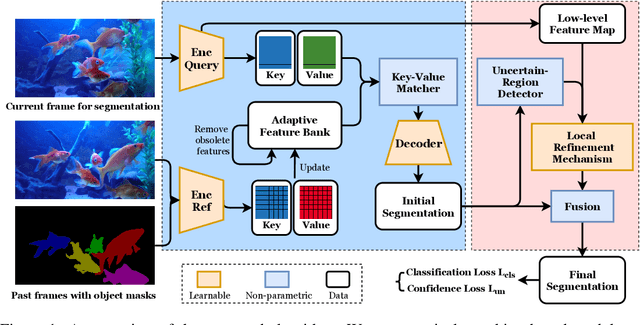
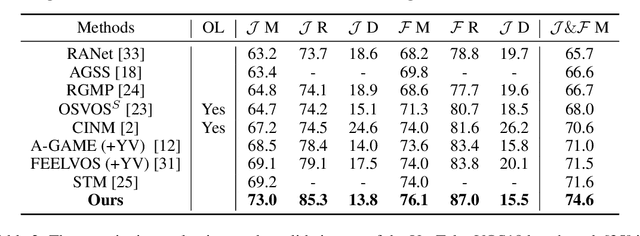
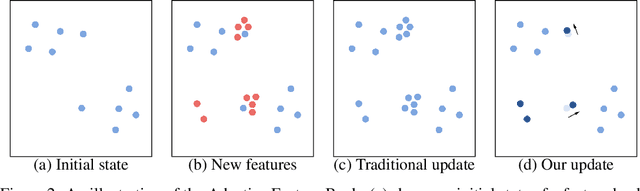
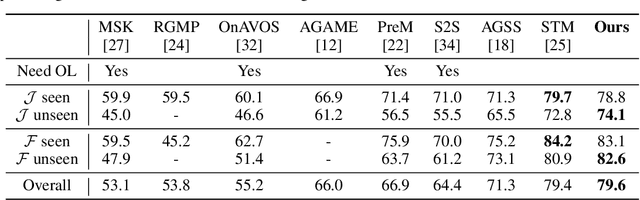
We propose a new matching-based framework for semi-supervised video object segmentation (VOS). Recently, state-of-the-art VOS performance has been achieved by matching-based algorithms, in which feature banks are created to store features for region matching and classification. However, how to effectively organize information in the continuously growing feature bank remains under-explored, and this leads to inefficient design of the bank. We introduce an adaptive feature bank update scheme to dynamically absorb new features and discard obsolete features. We also design a new confidence loss and a fine-grained segmentation module to enhance the segmentation accuracy in uncertain regions. On public benchmarks, our algorithm outperforms existing state-of-the-arts.
* Preprint version. Accepted by NeurIPS 2020