 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Clothed Avatar Generation from Text Descriptions
Paper and Code
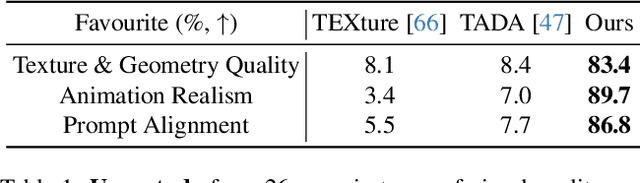
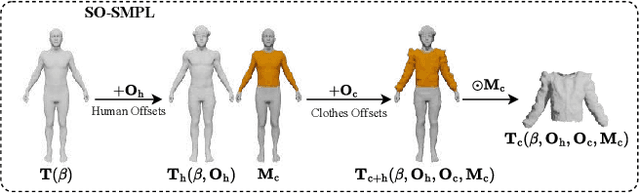
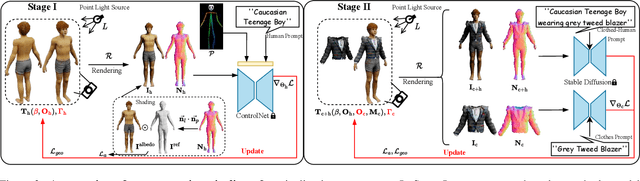

In this paper, we introduced a novel text-to-avatar generation method that separately generates the human body and the clothes and allows high-quality animation on the generated avatar. While recent advancements in text-to-avatar generation have yielded diverse human avatars from text prompts, these methods typically combine all elements-clothes, hair, and body-into a single 3D representation. Such an entangled approach poses challenges for downstream tasks like editing or animation. To overcome these limitations, we propose a novel disentangled 3D avatar representation named Sequentially Offset-SMPL (SO-SMPL), building upon the SMPL model. SO-SMPL represents the human body and clothes with two separate meshes, but associates them with offsets to ensure the physical alignment between the body and the clothes. Then, we design an Score Distillation Sampling(SDS)-based distillation framework to generate the proposed SO-SMPL representation from text prompts. In comparison with existing text-to-avatar methods, our approach not only achieves higher exture and geometry quality and better semantic alignment with text prompts, but also significantly improves the visual quality of character animation, virtual try-on, and avatar editing. Our project page is at https://shanemankiw.github.io/SO-SMPL/.