 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Degradation-Aware Arbitrary-Scale Super-Resolution for Variable-Rate Extreme Image Compression
Mar 18, 2026Recent diffusion-based extreme image compression methods have demonstrated remarkable performance at ultra-low bitrates. However, most approaches require training separate diffusion models for each target bitrate, resulting in substantial computational overhead and hindering practical deployment. Meanwhile, recent studies have shown that joint super-resolution can serve as an effective approach for enhancing low-bitrate reconstruction. However, when moving toward ultra-low bitrate regimes, these methods struggle due to severe information loss, and their reliance on fixed super-resolution scales prevents flexible adaptation across diverse bitrates. To address these limitations, we propose ASSR-EIC, a novel image compression framework that leverages arbitrary-scale super-resolution (ASSR) to support variable-rate extreme image compression (EIC). An arbitrary-scale downsampling module is introduced at the encoder side to provide controllable rate reduction, while a diffusion-based, joint degradation-aware ASSR decoder enables rate-adaptive reconstruction within a single model. We exploit the compression- and rescaling-aware diffusion prior to guide the reconstruction, yielding high fidelity and high realism restoration across diverse compression and rescaling settings. Specifically, we design a global compression-rescaling adaptor that offers holistic guidance for rate adaptation, and a local compression-rescaling modulator that dynamically balances generative and fidelity-oriented behaviors to achieve fine-grained, bitrate-adaptive detail restoration. To further enhance reconstruction quality, we introduce a dual semantic-enhanced design. Extensive experiments demonstrate that ASSR-EIC delivers state-of-the-art performance in extreme image compression while simultaneously supporting flexible bitrate control and adaptive rate-dependent reconstruction.
PA-HOI: A Physics-Aware Human and Object Interaction Dataset
Aug 08, 2025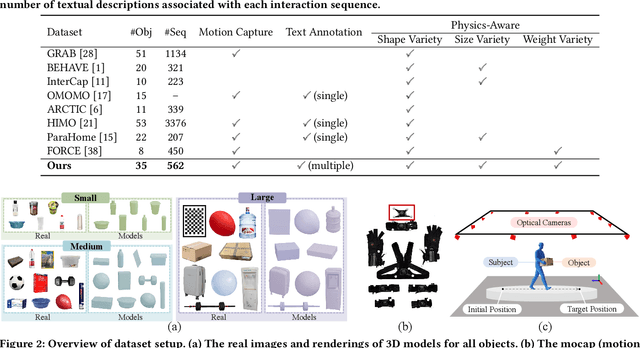
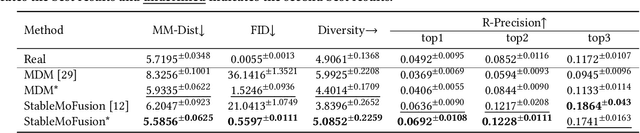
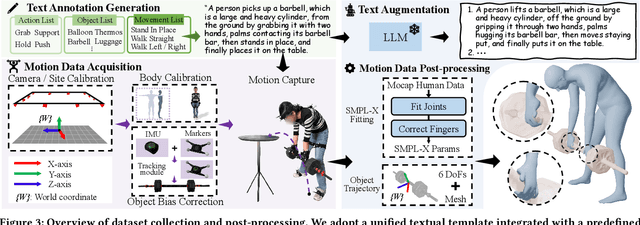
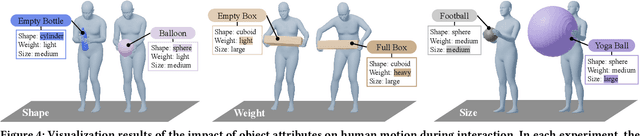
The Human-Object Interaction (HOI) task explores the dynamic interactions between humans and objects in physical environments, providing essential biomechanical and cognitive-behavioral foundations for fields such as robotics, virtual reality, and human-computer interaction. However, existing HOI data sets focus on details of affordance, often neglecting the influence of physical properties of objects on human long-term motion. To bridge this gap, we introduce the PA-HOI Motion Capture dataset, which highlights the impact of objects' physical attributes on human motion dynamics, including human posture, moving velocity, and other motion characteristics. The dataset comprises 562 motion sequences of human-object interactions, with each sequence performed by subjects of different genders interacting with 35 3D objects that vary in size, shape, and weight. This dataset stands out by significantly extending the scope of existing ones for understanding how the physical attributes of different objects influence human posture, speed, motion scale, and interacting strategies. We further demonstrate the applicability of the PA-HOI dataset by integrating it with existing motion generation methods, validating its capacity to transfer realistic physical awareness.
Enhanced Semantic Extraction and Guidance for UGC Image Super Resolution
Apr 14, 2025Due to the disparity between real-world degradations in user-generated content(UGC) images and synthetic degradations, traditional super-resolution methods struggle to generalize effectively, necessitating a more robust approach to model real-world distortions. In this paper, we propose a novel approach to UGC image super-resolution by integrating semantic guidance into a diffusion framework. Our method addresses the inconsistency between degradations in wild and synthetic datasets by separately simulating the degradation processes on the LSDIR dataset and combining them with the official paired training set. Furthermore, we enhance degradation removal and detail generation by incorporating a pretrained semantic extraction model (SAM2) and fine-tuning key hyperparameters for improved perceptual fidelity. Extensive experiments demonstrate the superiority of our approach against state-of-the-art methods. Additionally, the proposed model won second place in the CVPR NTIRE 2025 Short-form UGC Image Super-Resolution Challenge, further validating its effectiveness. The code is available at https://github.c10pom/Moonsofang/NTIRE-2025-SRlab.
Face De-identification: State-of-the-art Methods and Comparative Studies
Nov 15, 2024



The widespread use of image acquisition technologies, along with advances in facial recognition, has raised serious privacy concerns. Face de-identification usually refers to the process of concealing or replacing personal identifiers, which is regarded as an effective means to protect the privacy of facial images. A significant number of methods for face de-identification have been proposed in recent years. In this survey, we provide a comprehensive review of state-of-the-art face de-identification methods, categorized into three levels: pixel-level, representation-level, and semantic-level techniques. We systematically evaluate these methods based on two key criteria, the effectiveness of privacy protection and preservation of image utility, highlighting their advantages and limitations. Our analysis includes qualitative and quantitative comparisons of the main algorithms, demonstrating that deep learning-based approaches, particularly those using Generative Adversarial Networks (GANs) and diffusion models, have achieved significant advancements in balancing privacy and utility. Experimental results reveal that while recent methods demonstrate strong privacy protection, trade-offs remain in visual fidelity and computational complexity. This survey not only summarizes the current landscape but also identifies key challenges and future research directions in face de-identification.
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation
Sep 04, 2024
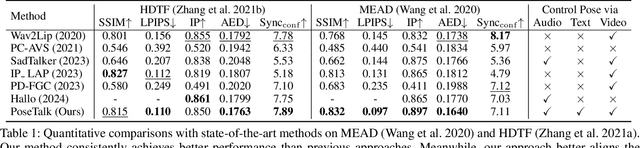
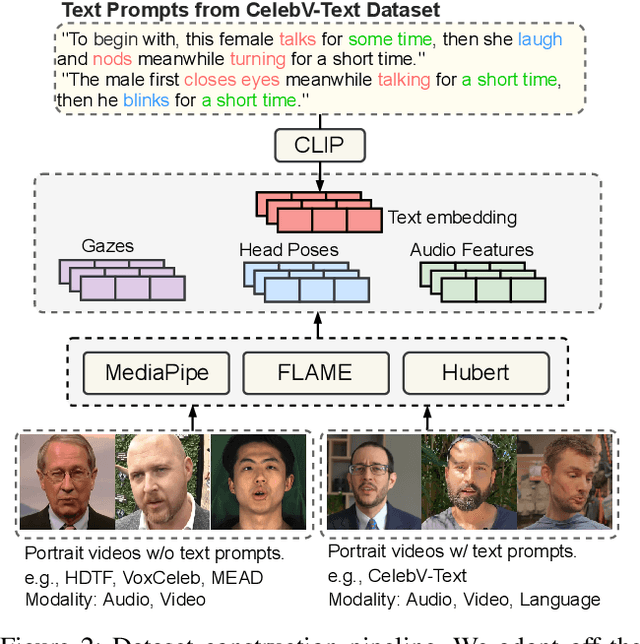
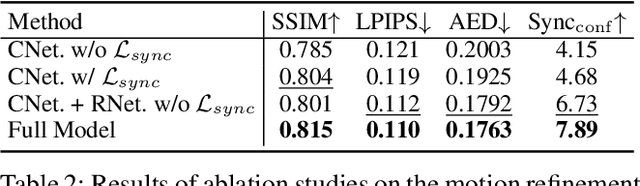
While previous audio-driven talking head generation (THG) methods generate head poses from driving audio, the generated poses or lips cannot match the audio well or are not editable. In this study, we propose \textbf{PoseTalk}, a THG system that can freely generate lip-synchronized talking head videos with free head poses conditioned on text prompts and audio. The core insight of our method is using head pose to connect visual, linguistic, and audio signals. First, we propose to generate poses from both audio and text prompts, where the audio offers short-term variations and rhythm correspondence of the head movements and the text prompts describe the long-term semantics of head motions. To achieve this goal, we devise a Pose Latent Diffusion (PLD) model to generate motion latent from text prompts and audio cues in a pose latent space. Second, we observe a loss-imbalance problem: the loss for the lip region contributes less than 4\% of the total reconstruction loss caused by both pose and lip, making optimization lean towards head movements rather than lip shapes. To address this issue, we propose a refinement-based learning strategy to synthesize natural talking videos using two cascaded networks, i.e., CoarseNet, and RefineNet. The CoarseNet estimates coarse motions to produce animated images in novel poses and the RefineNet focuses on learning finer lip motions by progressively estimating lip motions from low-to-high resolutions, yielding improved lip-synchronization performance. Experiments demonstrate our pose prediction strategy achieves better pose diversity and realness compared to text-only or audio-only, and our video generator model outperforms state-of-the-art methods in synthesizing talking videos with natural head motions. Project: https://junleen.github.io/projects/posetalk.
MRIR: Integrating Multimodal Insights for Diffusion-based Realistic Image Restoration
Jul 04, 2024



Realistic image restoration is a crucial task in computer vision, and the use of diffusion-based models for image restoration has garnered significant attention due to their ability to produce realistic results. However, the quality of the generated images is still a significant challenge due to the severity of image degradation and the uncontrollability of the diffusion model. In this work, we delve into the potential of utilizing pre-trained stable diffusion for image restoration and propose MRIR, a diffusion-based restoration method with multimodal insights. Specifically, we explore the problem from two perspectives: textual level and visual level. For the textual level, we harness the power of the pre-trained multimodal large language model to infer meaningful semantic information from low-quality images. Furthermore, we employ the CLIP image encoder with a designed Refine Layer to capture image details as a supplement. For the visual level, we mainly focus on the pixel level control. Thus, we utilize a Pixel-level Processor and ControlNet to control spatial structures. Finally, we integrate the aforementioned control information into the denoising U-Net using multi-level attention mechanisms and realize controllable image restoration with multimodal insights. The qualitative and quantitative results demonstrate our method's superiority over other state-of-the-art methods on both synthetic and real-world datasets.
Diff-Restorer: Unleashing Visual Prompts for Diffusion-based Universal Image Restoration
Jul 04, 2024



Image restoration is a classic low-level problem aimed at recovering high-quality images from low-quality images with various degradations such as blur, noise, rain, haze, etc. However, due to the inherent complexity and non-uniqueness of degradation in real-world images, it is challenging for a model trained for single tasks to handle real-world restoration problems effectively. Moreover, existing methods often suffer from over-smoothing and lack of realism in the restored results. To address these issues, we propose Diff-Restorer, a universal image restoration method based on the diffusion model, aiming to leverage the prior knowledge of Stable Diffusion to remove degradation while generating high perceptual quality restoration results. Specifically, we utilize the pre-trained visual language model to extract visual prompts from degraded images, including semantic and degradation embeddings. The semantic embeddings serve as content prompts to guide the diffusion model for generation. In contrast, the degradation embeddings modulate the Image-guided Control Module to generate spatial priors for controlling the spatial structure of the diffusion process, ensuring faithfulness to the original image. Additionally, we design a Degradation-aware Decoder to perform structural correction and convert the latent code to the pixel domain. We conducted comprehensive qualitative and quantitative analysis on restoration tasks with different degradations, demonstrating the effectiveness and superiority of our approach.
Multimodal Semantic-Aware Automatic Colorization with Diffusion Prior
Apr 25, 2024
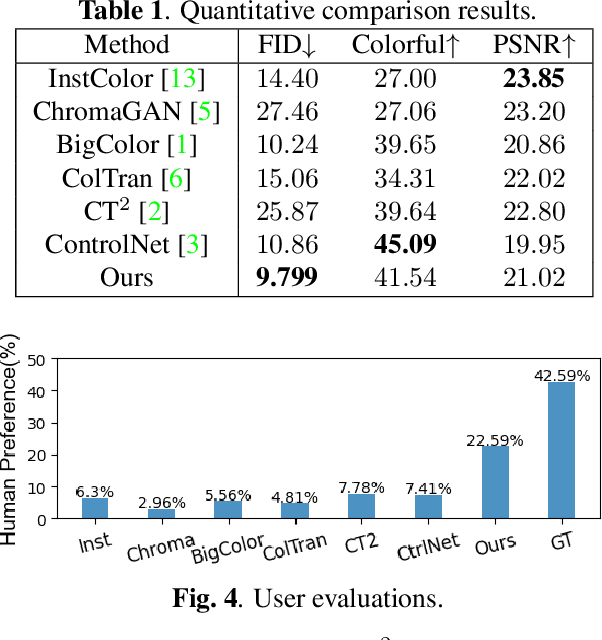
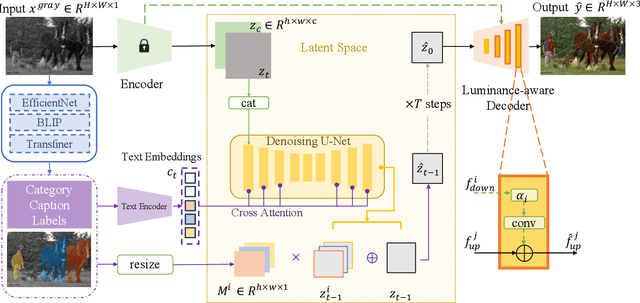
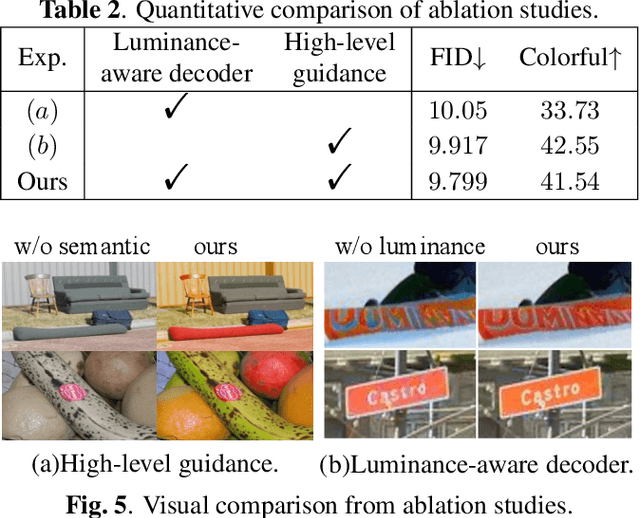
Colorizing grayscale images offers an engaging visual experience. Existing automatic colorization methods often fail to generate satisfactory results due to incorrect semantic colors and unsaturated colors. In this work, we propose an automatic colorization pipeline to overcome these challenges. We leverage the extraordinary generative ability of the diffusion prior to synthesize color with plausible semantics. To overcome the artifacts introduced by the diffusion prior, we apply the luminance conditional guidance. Moreover, we adopt multimodal high-level semantic priors to help the model understand the image content and deliver saturated colors. Besides, a luminance-aware decoder is designed to restore details and enhance overall visual quality. The proposed pipeline synthesizes saturated colors while maintaining plausible semantics. Experiments indicate that our proposed method considers both diversity and fidelity, surpassing previous methods in terms of perceptual realism and gain most human preference.
Depth-Guided Robust and Fast Point Cloud Fusion NeRF for Sparse Input Views
Mar 04, 2024



Novel-view synthesis with sparse input views is important for real-world applications like AR/VR and autonomous driving. Recent methods have integrated depth information into NeRFs for sparse input synthesis, leveraging depth prior for geometric and spatial understanding. However, most existing works tend to overlook inaccuracies within depth maps and have low time efficiency. To address these issues, we propose a depth-guided robust and fast point cloud fusion NeRF for sparse inputs. We perceive radiance fields as an explicit voxel grid of features. A point cloud is constructed for each input view, characterized within the voxel grid using matrices and vectors. We accumulate the point cloud of each input view to construct the fused point cloud of the entire scene. Each voxel determines its density and appearance by referring to the point cloud of the entire scene. Through point cloud fusion and voxel grid fine-tuning, inaccuracies in depth values are refined or substituted by those from other views. Moreover, our method can achieve faster reconstruction and greater compactness through effective vector-matrix decomposition. Experimental results underline the superior performance and time efficiency of our approach compared to state-of-the-art baselines.
Disentangled Clothed Avatar Generation from Text Descriptions
Dec 08, 2023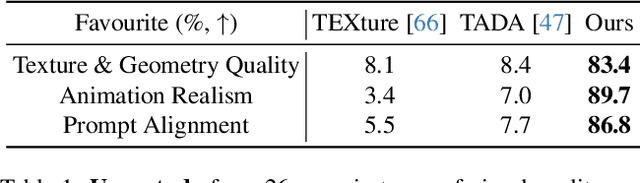
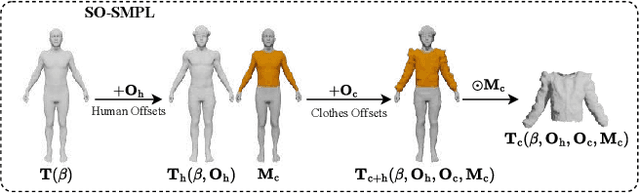
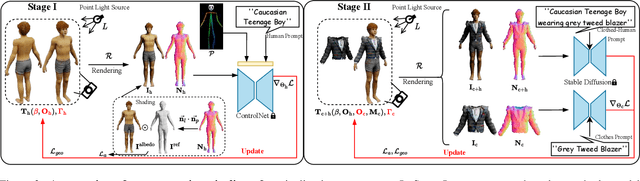

In this paper, we introduced a novel text-to-avatar generation method that separately generates the human body and the clothes and allows high-quality animation on the generated avatar. While recent advancements in text-to-avatar generation have yielded diverse human avatars from text prompts, these methods typically combine all elements-clothes, hair, and body-into a single 3D representation. Such an entangled approach poses challenges for downstream tasks like editing or animation. To overcome these limitations, we propose a novel disentangled 3D avatar representation named Sequentially Offset-SMPL (SO-SMPL), building upon the SMPL model. SO-SMPL represents the human body and clothes with two separate meshes, but associates them with offsets to ensure the physical alignment between the body and the clothes. Then, we design an Score Distillation Sampling(SDS)-based distillation framework to generate the proposed SO-SMPL representation from text prompts. In comparison with existing text-to-avatar methods, our approach not only achieves higher exture and geometry quality and better semantic alignment with text prompts, but also significantly improves the visual quality of character animation, virtual try-on, and avatar editing. Our project page is at https://shanemankiw.github.io/SO-SMPL/.