 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams
Jun 01, 2026Auto-harness systems such as A-Evolve, GEPA, and Meta-Harness improve LLM agents by optimizing prompts, skills, tools, memories, and supporting infrastructure from execution feedback, but they are typically evaluated on fixed offline benchmarks. Real deployments instead present open-ended task streams: histories grow without a fixed endpoint, heterogeneous tasks require different harnesses, and problem distributions shift over time. These challenges make a single repeatedly and densely updated harness brittle, causing performance degradation as accuracy peaks early and then declines. This motivates sustained harness construction with task-wise adaptation. We introduce Adaptive Auto-Harness, a framework and system for such streams. The framework decomposes the gap to an oracle harness into evolution loss and adaptation loss. The system addresses these losses with a stateful multi-agent evolver, a harness tree with solve-time routing, and human-steering hooks for cases where history lacks the needed signal. Across prediction-market, security-competition, and event-forecasting streams, Adaptive Auto-Harness outperforms five existing auto-harness baselines and ablations attribute gains to better construction, routing, or targeted human steering. Code is available in https://github.com/A-EVO-Lab/AdaptiveHarness .
Harness Updating Is Not Harness Benefit: Disentangling Evolution Capabilities in Self-Evolving LLM Agents
May 28, 2026LLM agents are increasingly deployed as systems built around editable external harnesses, including prompts, skills, memories and tools, that shape task execution without changing model parameters. Harness self-evolution adapts such agents by updating these harnesses from execution evidence. Yet it remains unclear whether a model's base capability in task-solving predicts its capabilities in harness self-evolution: which models produce useful harness updates, and which actually benefit from them? We analyze two harness self-evolution capabilities: (i) harness-updating, the capability to produce useful persistent harness updates from execution evidence; (ii) harness-benefit, the capability to benefit from updated harnesses during task solving. Our analysis reveals two findings. First, harness-updating is flat in base capability: models from different capability tiers produce harness updates that lead to surprisingly similar gains; even Qwen3.5-9B's updates yield gains comparable to those of Claude Opus~4.6. Second, harness-benefit is non-monotonic in base capability: weak-tier models benefit little from updated harnesses, mid-tier models benefit most, and strong-tier models benefit less than mid-tier. We trace low gains at the weak tier to two failure modes: weak-tier models may fail to activate relevant harness artifacts, or activate them but fail to follow them faithfully. These findings suggest investing capability budget in the task-solving agent rather than the evolver, and targeting harness invocation and long-horizon instruction following in agent training. Our source code is publicly available at https://github.com/A-EVO-Lab/a-evolve/tree/release/harness-evolution.
Adaptive Learned Image Compression with Graph Neural Networks
Mar 26, 2026Efficient image compression relies on modeling both local and global redundancy. Most state-of-the-art (SOTA) learned image compression (LIC) methods are based on CNNs or Transformers, which are inherently rigid. Standard CNN kernels and window-based attention mechanisms impose fixed receptive fields and static connectivity patterns, which potentially couple non-redundant pixels simply due to their proximity in Euclidean space. This rigidity limits the model's ability to adaptively capture spatially varying redundancy across the image, particularly at the global level. To overcome these limitations, we propose a content-adaptive image compression framework based on Graph Neural Networks (GNNs). Specifically, our approach constructs dual-scale graphs that enable flexible, data-driven receptive fields. Furthermore, we introduce adaptive connectivity by dynamically adjusting the number of neighbors for each node based on local content complexity. These innovations empower our Graph-based Learned Image Compression (GLIC) model to effectively model diverse redundancy patterns across images, leading to more efficient and adaptive compression. Experiments demonstrate that GLIC achieves state-of-the-art performance, achieving BD-rate reductions of 19.29%, 21.69%, and 18.71% relative to VTM-9.1 on Kodak, Tecnick, and CLIC, respectively. Code will be released at https://github.com/UnoC-727/GLIC.
Next-Frame Decoding for Ultra-Low-Bitrate Image Compression with Video Diffusion Priors
Mar 16, 2026We present a novel paradigm for ultra-low-bitrate image compression (ULB-IC) that exploits the ``temporal'' evolution in generative image compression. Specifically, we define an explicit intermediate state during decoding: a compact anchor frame, which preserves the scene geometry and semantic layout while discarding high-frequency details. We then reinterpret generative decoding as a virtual temporal transition from this anchor to the final reconstructed image.To model this progression, we leverage a pretrained video diffusion model (VDM) as temporal priors: the anchor frame serves as the initial frame and the original image as the target frame, transforming the decoding process into a next-frame prediction task.In contrast to image diffusion-based ULB-IC models, our decoding proceeds from a visible, semantically faithful anchor, which improves both fidelity and realism for perceptual image compression. Extensive experiments demonstrate that our method achieves superior objective and subjective performance. On the CLIC2020 test set, our method achieves over \textbf{50\% bitrate savings} across LPIPS, DISTS, FID, and KID compared to DiffC, while also delivering a significant decoding speedup of up to $\times$5. Code will be released later.
How Do Latent Reasoning Methods Perform Under Weak and Strong Supervision?
Feb 25, 2026Latent reasoning has been recently proposed as a reasoning paradigm and performs multi-step reasoning through generating steps in the latent space instead of the textual space. This paradigm enables reasoning beyond discrete language tokens by performing multi-step computation in continuous latent spaces. Although there have been numerous studies focusing on improving the performance of latent reasoning, its internal mechanisms remain not fully investigated. In this work, we conduct a comprehensive analysis of latent reasoning methods to better understand the role and behavior of latent representation in the process. We identify two key issues across latent reasoning methods with different levels of supervision. First, we observe pervasive shortcut behavior, where they achieve high accuracy without relying on latent reasoning. Second, we examine the hypothesis that latent reasoning supports BFS-like exploration in latent space, and find that while latent representations can encode multiple possibilities, the reasoning process does not faithfully implement structured search, but instead exhibits implicit pruning and compression. Finally, our findings reveal a trade-off associated with supervision strength: stronger supervision mitigates shortcut behavior but restricts the ability of latent representations to maintain diverse hypotheses, whereas weaker supervision allows richer latent representations at the cost of increased shortcut behavior.
SurfSplat: Conquering Feedforward 2D Gaussian Splatting with Surface Continuity Priors
Feb 03, 2026Reconstructing 3D scenes from sparse images remains a challenging task due to the difficulty of recovering accurate geometry and texture without optimization. Recent approaches leverage generalizable models to generate 3D scenes using 3D Gaussian Splatting (3DGS) primitive. However, they often fail to produce continuous surfaces and instead yield discrete, color-biased point clouds that appear plausible at normal resolution but reveal severe artifacts under close-up views. To address this issue, we present SurfSplat, a feedforward framework based on 2D Gaussian Splatting (2DGS) primitive, which provides stronger anisotropy and higher geometric precision. By incorporating a surface continuity prior and a forced alpha blending strategy, SurfSplat reconstructs coherent geometry together with faithful textures. Furthermore, we introduce High-Resolution Rendering Consistency (HRRC), a new evaluation metric designed to evaluate high-resolution reconstruction quality. Extensive experiments on RealEstate10K, DL3DV, and ScanNet demonstrate that SurfSplat consistently outperforms prior methods on both standard metrics and HRRC, establishing a robust solution for high-fidelity 3D reconstruction from sparse inputs. Project page: https://hebing-sjtu.github.io/SurfSplat-website/
Position: Agentic Evolution is the Path to Evolving LLMs
Jan 30, 2026As Large Language Models (LLMs) move from curated training sets into open-ended real-world environments, a fundamental limitation emerges: static training cannot keep pace with continual deployment environment change. Scaling training-time and inference-time compute improves static capability but does not close this train-deploy gap. We argue that addressing this limitation requires a new scaling axis-evolution. Existing deployment-time adaptation methods, whether parametric fine-tuning or heuristic memory accumulation, lack the strategic agency needed to diagnose failures and produce durable improvements. Our position is that agentic evolution represents the inevitable future of LLM adaptation, elevating evolution itself from a fixed pipeline to an autonomous evolver agent. We instantiate this vision in a general framework, A-Evolve, which treats deployment-time improvement as a deliberate, goal-directed optimization process over persistent system state. We further propose the evolution-scaling hypothesis: the capacity for adaptation scales with the compute allocated to evolution, positioning agentic evolution as a scalable path toward sustained, open-ended adaptation in the real world.
TRAJECT-Bench:A Trajectory-Aware Benchmark for Evaluating Agentic Tool Use
Oct 06, 2025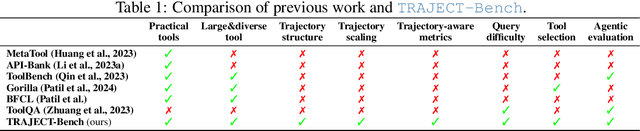

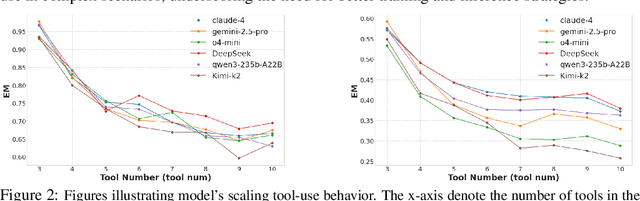
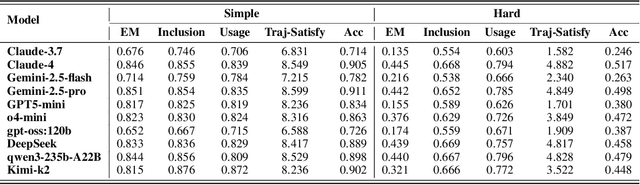
Large language model (LLM)-based agents increasingly rely on tool use to complete real-world tasks. While existing works evaluate the LLMs' tool use capability, they largely focus on the final answers yet overlook the detailed tool usage trajectory, i.e., whether tools are selected, parameterized, and ordered correctly. We introduce TRAJECT-Bench, a trajectory-aware benchmark to comprehensively evaluate LLMs' tool use capability through diverse tasks with fine-grained evaluation metrics. TRAJECT-Bench pairs high-fidelity, executable tools across practical domains with tasks grounded in production-style APIs, and synthesizes trajectories that vary in breadth (parallel calls) and depth (interdependent chains). Besides final accuracy, TRAJECT-Bench also reports trajectory-level diagnostics, including tool selection and argument correctness, and dependency/order satisfaction. Analyses reveal failure modes such as similar tool confusion and parameter-blind selection, and scaling behavior with tool diversity and trajectory length where the bottleneck of transiting from short to mid-length trajectories is revealed, offering actionable guidance for LLMs' tool use.
S4D: Streaming 4D Real-World Reconstruction with Gaussians and 3D Control Points
Aug 23, 2024Recently, the dynamic scene reconstruction using Gaussians has garnered increased interest. Mainstream approaches typically employ a global deformation field to warp a 3D scene in the canonical space. However, the inherently low-frequency nature of implicit neural fields often leads to ineffective representations of complex motions. Moreover, their structural rigidity can hinder adaptation to scenes with varying resolutions and durations. To overcome these challenges, we introduce a novel approach utilizing discrete 3D control points. This method models local rays physically and establishes a motion-decoupling coordinate system, which effectively merges traditional graphics with learnable pipelines for a robust and efficient local 6-degrees-of-freedom (6-DoF) motion representation. Additionally, we have developed a generalized framework that incorporates our control points with Gaussians. Starting from an initial 3D reconstruction, our workflow decomposes the streaming 4D real-world reconstruction into four independent submodules: 3D segmentation, 3D control points generation, object-wise motion manipulation, and residual compensation. Our experiments demonstrate that this method outperforms existing state-of-the-art 4D Gaussian Splatting techniques on both the Neu3DV and CMU-Panoptic datasets. Our approach also significantly accelerates training, with the optimization of our 3D control points achievable within just 2 seconds per frame on a single NVIDIA 4070 GPU.
Learning the irreversible progression trajectory of Alzheimer's disease
Mar 10, 2024



Alzheimer's disease (AD) is a progressive and irreversible brain disorder that unfolds over the course of 30 years. Therefore, it is critical to capture the disease progression in an early stage such that intervention can be applied before the onset of symptoms. Machine learning (ML) models have been shown effective in predicting the onset of AD. Yet for subjects with follow-up visits, existing techniques for AD classification only aim for accurate group assignment, where the monotonically increasing risk across follow-up visits is usually ignored. Resulted fluctuating risk scores across visits violate the irreversibility of AD, hampering the trustworthiness of models and also providing little value to understanding the disease progression. To address this issue, we propose a novel regularization approach to predict AD longitudinally. Our technique aims to maintain the expected monotonicity of increasing disease risk during progression while preserving expressiveness. Specifically, we introduce a monotonicity constraint that encourages the model to predict disease risk in a consistent and ordered manner across follow-up visits. We evaluate our method using the longitudinal structural MRI and amyloid-PET imaging data from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Our model outperforms existing techniques in capturing the progressiveness of disease risk, and at the same time preserves prediction accuracy.