 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePETGEN: Personalized Text Generation Attack on Deep Sequence Embedding-based Classification Models
Paper and Code
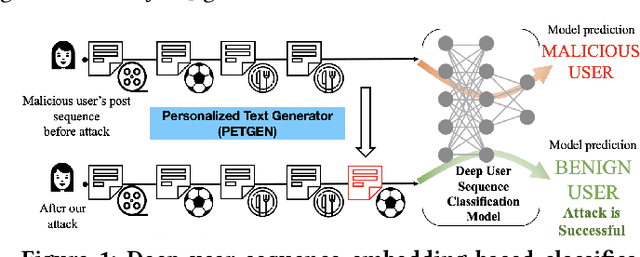

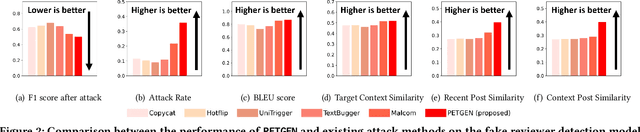
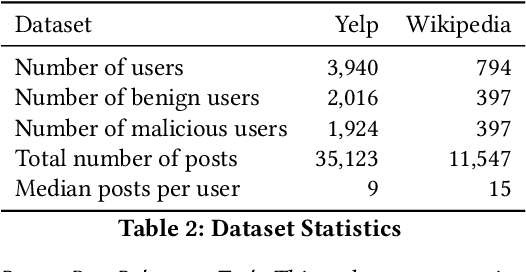
\textit{What should a malicious user write next to fool a detection model?} Identifying malicious users is critical to ensure the safety and integrity of internet platforms. Several deep learning based detection models have been created. However, malicious users can evade deep detection models by manipulating their behavior, rendering these models of little use. The vulnerability of such deep detection models against adversarial attacks is unknown. Here we create a novel adversarial attack model against deep user sequence embedding-based classification models, which use the sequence of user posts to generate user embeddings and detect malicious users. In the attack, the adversary generates a new post to fool the classifier. We propose a novel end-to-end Personalized Text Generation Attack model, called \texttt{PETGEN}, that simultaneously reduces the efficacy of the detection model and generates posts that have several key desirable properties. Specifically, \texttt{PETGEN} generates posts that are personalized to the user's writing style, have knowledge about a given target context, are aware of the user's historical posts on the target context, and encapsulate the user's recent topical interests. We conduct extensive experiments on two real-world datasets (Yelp and Wikipedia, both with ground-truth of malicious users) to show that \texttt{PETGEN} significantly reduces the performance of popular deep user sequence embedding-based classification models. \texttt{PETGEN} outperforms five attack baselines in terms of text quality and attack efficacy in both white-box and black-box classifier settings. Overall, this work paves the path towards the next generation of adversary-aware sequence classification models.