 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavePulse: Real-time Content Analytics of Radio Livestreams
Dec 23, 2024Radio remains a pervasive medium for mass information dissemination, with AM/FM stations reaching more Americans than either smartphone-based social networking or live television. Increasingly, radio broadcasts are also streamed online and accessed over the Internet. We present WavePulse, a framework that records, documents, and analyzes radio content in real-time. While our framework is generally applicable, we showcase the efficacy of WavePulse in a collaborative project with a team of political scientists focusing on the 2024 Presidential Elections. We use WavePulse to monitor livestreams of 396 news radio stations over a period of three months, processing close to 500,000 hours of audio streams. These streams were converted into time-stamped, diarized transcripts and analyzed to track answer key political science questions at both the national and state levels. Our analysis revealed how local issues interacted with national trends, providing insights into information flow. Our results demonstrate WavePulse's efficacy in capturing and analyzing content from radio livestreams sourced from the Web. Code and dataset can be accessed at \url{https://wave-pulse.io}.
Evaluating Synthetic Command Attacks on Smart Voice Assistants
Nov 13, 2024Recent advances in voice synthesis, coupled with the ease with which speech can be harvested for millions of people, introduce new threats to applications that are enabled by devices such as voice assistants (e.g., Amazon Alexa, Google Home etc.). We explore if unrelated and limited amount of speech from a target can be used to synthesize commands for a voice assistant like Amazon Alexa. More specifically, we investigate attacks on voice assistants with synthetic commands when they match command sources to authorized users, and applications (e.g., Alexa Skills) process commands only when their source is an authorized user with a chosen confidence level. We demonstrate that even simple concatenative speech synthesis can be used by an attacker to command voice assistants to perform sensitive operations. We also show that such attacks, when launched by exploiting compromised devices in the vicinity of voice assistants, can have relatively small host and network footprint. Our results demonstrate the need for better defenses against synthetic malicious commands that could target voice assistants.
Reinforcement Learning-based Counter-Misinformation Response Generation: A Case Study of COVID-19 Vaccine Misinformation
Mar 11, 2023The spread of online misinformation threatens public health, democracy, and the broader society. While professional fact-checkers form the first line of defense by fact-checking popular false claims, they do not engage directly in conversations with misinformation spreaders. On the other hand, non-expert ordinary users act as eyes-on-the-ground who proactively counter misinformation -- recent research has shown that 96% counter-misinformation responses are made by ordinary users. However, research also found that 2/3 times, these responses are rude and lack evidence. This work seeks to create a counter-misinformation response generation model to empower users to effectively correct misinformation. This objective is challenging due to the absence of datasets containing ground-truth of ideal counter-misinformation responses, and the lack of models that can generate responses backed by communication theories. In this work, we create two novel datasets of misinformation and counter-misinformation response pairs from in-the-wild social media and crowdsourcing from college-educated students. We annotate the collected data to distinguish poor from ideal responses that are factual, polite, and refute misinformation. We propose MisinfoCorrect, a reinforcement learning-based framework that learns to generate counter-misinformation responses for an input misinformation post. The model rewards the generator to increase the politeness, factuality, and refutation attitude while retaining text fluency and relevancy. Quantitative and qualitative evaluation shows that our model outperforms several baselines by generating high-quality counter-responses. This work illustrates the promise of generative text models for social good -- here, to help create a safe and reliable information ecosystem. The code and data is accessible on https://github.com/claws-lab/MisinfoCorrect.
PETGEN: Personalized Text Generation Attack on Deep Sequence Embedding-based Classification Models
Sep 14, 2021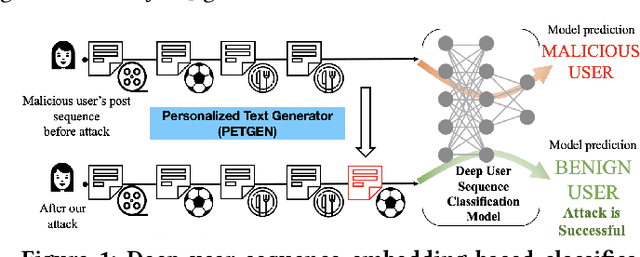

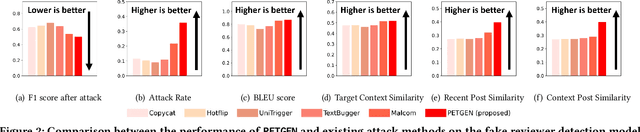
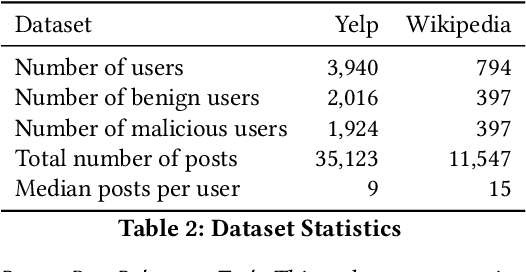
\textit{What should a malicious user write next to fool a detection model?} Identifying malicious users is critical to ensure the safety and integrity of internet platforms. Several deep learning based detection models have been created. However, malicious users can evade deep detection models by manipulating their behavior, rendering these models of little use. The vulnerability of such deep detection models against adversarial attacks is unknown. Here we create a novel adversarial attack model against deep user sequence embedding-based classification models, which use the sequence of user posts to generate user embeddings and detect malicious users. In the attack, the adversary generates a new post to fool the classifier. We propose a novel end-to-end Personalized Text Generation Attack model, called \texttt{PETGEN}, that simultaneously reduces the efficacy of the detection model and generates posts that have several key desirable properties. Specifically, \texttt{PETGEN} generates posts that are personalized to the user's writing style, have knowledge about a given target context, are aware of the user's historical posts on the target context, and encapsulate the user's recent topical interests. We conduct extensive experiments on two real-world datasets (Yelp and Wikipedia, both with ground-truth of malicious users) to show that \texttt{PETGEN} significantly reduces the performance of popular deep user sequence embedding-based classification models. \texttt{PETGEN} outperforms five attack baselines in terms of text quality and attack efficacy in both white-box and black-box classifier settings. Overall, this work paves the path towards the next generation of adversary-aware sequence classification models.
The Role of the Crowd in Countering Misinformation: A Case Study of the COVID-19 Infodemic
Nov 12, 2020

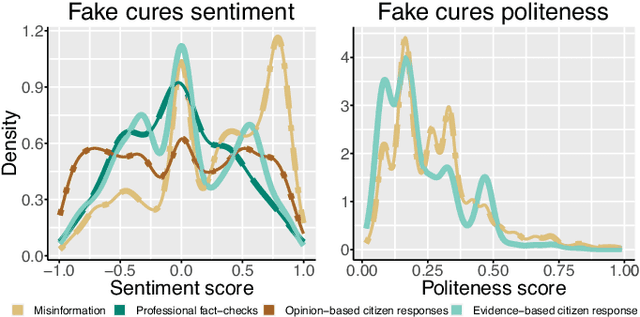

Fact checking by professionals is viewed as a vital defense in the fight against misinformation.While fact checking is important and its impact has been significant, fact checks could have limited visibility and may not reach the intended audience, such as those deeply embedded in polarized communities. Concerned citizens (i.e., the crowd), who are users of the platforms where misinformation appears, can play a crucial role in disseminating fact-checking information and in countering the spread of misinformation. To explore if this is the case, we conduct a data-driven study of misinformation on the Twitter platform, focusing on tweets related to the COVID-19 pandemic, analyzing the spread of misinformation, professional fact checks, and the crowd response to popular misleading claims about COVID-19. In this work, we curate a dataset of false claims and statements that seek to challenge or refute them. We train a classifier to create a novel dataset of 155,468 COVID-19-related tweets, containing 33,237 false claims and 33,413 refuting arguments.Our findings show that professional fact-checking tweets have limited volume and reach. In contrast, we observe that the surge in misinformation tweets results in a quick response and a corresponding increase in tweets that refute such misinformation. More importantly, we find contrasting differences in the way the crowd refutes tweets, some tweets appear to be opinions, while others contain concrete evidence, such as a link to a reputed source. Our work provides insights into how misinformation is organically countered in social platforms by some of their users and the role they play in amplifying professional fact checks.These insights could lead to development of tools and mechanisms that can empower concerned citizens in combating misinformation. The code and data can be found in http://claws.cc.gatech.edu/covid_counter_misinformation.html.