 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPBench: A Comprehensive Benchmark of Multimodal Large Language Models for Fingerprint Analysis
Dec 19, 2025Multimodal LLMs (MLLMs) have gained significant traction in complex data analysis, visual question answering, generation, and reasoning. Recently, they have been used for analyzing the biometric utility of iris and face images. However, their capabilities in fingerprint understanding are yet unexplored. In this work, we design a comprehensive benchmark, \textsc{FPBench} that evaluates the performance of 20 MLLMs (open-source and proprietary) across 7 real and synthetic datasets on 8 biometric and forensic tasks using zero-shot and chain-of-thought prompting strategies. We discuss our findings in terms of performance, explainability and share our insights into the challenges and limitations. We establish \textsc{FPBench} as the first comprehensive benchmark for fingerprint domain understanding with MLLMs paving the path for foundation models for fingerprints.
DiffClean: Diffusion-based Makeup Removal for Accurate Age Estimation
Jul 17, 2025Accurate age verification can protect underage users from unauthorized access to online platforms and e-commerce sites that provide age-restricted services. However, accurate age estimation can be confounded by several factors, including facial makeup that can induce changes to alter perceived identity and age to fool both humans and machines. In this work, we propose DiffClean which erases makeup traces using a text-guided diffusion model to defend against makeup attacks. DiffClean improves age estimation (minor vs. adult accuracy by 4.8%) and face verification (TMR by 8.9% at FMR=0.01%) over competing baselines on digitally simulated and real makeup images.
Forging and Removing Latent-Noise Diffusion Watermarks Using a Single Image
Apr 27, 2025Watermarking techniques are vital for protecting intellectual property and preventing fraudulent use of media. Most previous watermarking schemes designed for diffusion models embed a secret key in the initial noise. The resulting pattern is often considered hard to remove and forge into unrelated images. In this paper, we propose a black-box adversarial attack without presuming access to the diffusion model weights. Our attack uses only a single watermarked example and is based on a simple observation: there is a many-to-one mapping between images and initial noises. There are regions in the clean image latent space pertaining to each watermark that get mapped to the same initial noise when inverted. Based on this intuition, we propose an adversarial attack to forge the watermark by introducing perturbations to the images such that we can enter the region of watermarked images. We show that we can also apply a similar approach for watermark removal by learning perturbations to exit this region. We report results on multiple watermarking schemes (Tree-Ring, RingID, WIND, and Gaussian Shading) across two diffusion models (SDv1.4 and SDv2.0). Our results demonstrate the effectiveness of the attack and expose vulnerabilities in the watermarking methods, motivating future research on improving them.
FaceCloak: Learning to Protect Face Templates
Apr 08, 2025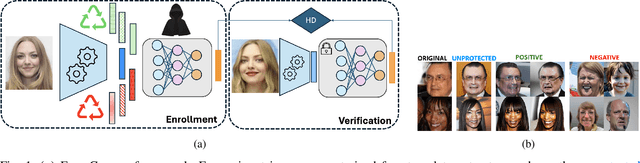
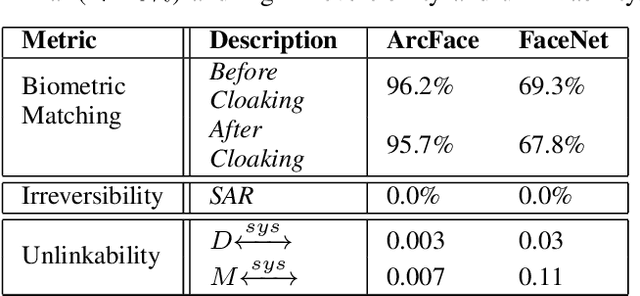
Generative models can reconstruct face images from encoded representations (templates) bearing remarkable likeness to the original face raising security and privacy concerns. We present FaceCloak, a neural network framework that protects face templates by generating smart, renewable binary cloaks. Our method proactively thwarts inversion attacks by cloaking face templates with unique disruptors synthesized from a single face template on the fly while provably retaining biometric utility and unlinkability. Our cloaked templates can suppress sensitive attributes while generalizing to novel feature extraction schemes and outperforms leading baselines in terms of biometric matching and resiliency to reconstruction attacks. FaceCloak-based matching is extremely fast (inference time cost=0.28ms) and light-weight (0.57MB).
WavePulse: Real-time Content Analytics of Radio Livestreams
Dec 23, 2024Radio remains a pervasive medium for mass information dissemination, with AM/FM stations reaching more Americans than either smartphone-based social networking or live television. Increasingly, radio broadcasts are also streamed online and accessed over the Internet. We present WavePulse, a framework that records, documents, and analyzes radio content in real-time. While our framework is generally applicable, we showcase the efficacy of WavePulse in a collaborative project with a team of political scientists focusing on the 2024 Presidential Elections. We use WavePulse to monitor livestreams of 396 news radio stations over a period of three months, processing close to 500,000 hours of audio streams. These streams were converted into time-stamped, diarized transcripts and analyzed to track answer key political science questions at both the national and state levels. Our analysis revealed how local issues interacted with national trends, providing insights into information flow. Our results demonstrate WavePulse's efficacy in capturing and analyzing content from radio livestreams sourced from the Web. Code and dataset can be accessed at \url{https://wave-pulse.io}.
TraSCE: Trajectory Steering for Concept Erasure
Dec 10, 2024
Recent advancements in text-to-image diffusion models have brought them to the public spotlight, becoming widely accessible and embraced by everyday users. However, these models have been shown to generate harmful content such as not-safe-for-work (NSFW) images. While approaches have been proposed to erase such abstract concepts from the models, jail-breaking techniques have succeeded in bypassing such safety measures. In this paper, we propose TraSCE, an approach to guide the diffusion trajectory away from generating harmful content. Our approach is based on negative prompting, but as we show in this paper, conventional negative prompting is not a complete solution and can easily be bypassed in some corner cases. To address this issue, we first propose a modification of conventional negative prompting. Furthermore, we introduce a localized loss-based guidance that enhances the modified negative prompting technique by steering the diffusion trajectory. We demonstrate that our proposed method achieves state-of-the-art results on various benchmarks in removing harmful content including ones proposed by red teams; and erasing artistic styles and objects. Our proposed approach does not require any training, weight modifications, or training data (both image or prompt), making it easier for model owners to erase new concepts.
Classifier-Free Guidance inside the Attraction Basin May Cause Memorization
Nov 23, 2024Diffusion models are prone to exactly reproduce images from the training data. This exact reproduction of the training data is concerning as it can lead to copyright infringement and/or leakage of privacy-sensitive information. In this paper, we present a novel way to understand the memorization phenomenon, and propose a simple yet effective approach to mitigate it. We argue that memorization occurs because of an attraction basin in the denoising process which steers the diffusion trajectory towards a memorized image. However, this can be mitigated by guiding the diffusion trajectory away from the attraction basin by not applying classifier-free guidance until an ideal transition point occurs from which classifier-free guidance is applied. This leads to the generation of non-memorized images that are high in image quality and well-aligned with the conditioning mechanism. To further improve on this, we present a new guidance technique, \emph{opposite guidance}, that escapes the attraction basin sooner in the denoising process. We demonstrate the existence of attraction basins in various scenarios in which memorization occurs, and we show that our proposed approach successfully mitigates memorization.
Mitigating the Impact of Attribute Editing on Face Recognition
Mar 12, 2024Facial attribute editing using generative models can impair automated face recognition. This degradation persists even with recent identity-preserving models such as InstantID. To mitigate this issue, we propose two techniques that perform local and global attribute editing. Local editing operates on the finer details via a regularization-free method based on ControlNet conditioned on depth maps and auxiliary semantic segmentation masks. Global editing operates on coarser details via a regularization-based method guided by custom loss and regularization set. In this work, we empirically ablate twenty-six facial semantic, demographic and expression-based attributes altered using state-of-the-art generative models and evaluate them using ArcFace and AdaFace matchers on CelebA, CelebAMaskHQ and LFW datasets. Finally, we use LLaVA, a vision-language framework for attribute prediction to validate our editing techniques. Our methods outperform SoTA (BLIP, InstantID) at facial editing while retaining identity.
AI-assisted Tagging of Deepfake Audio Calls using Challenge-Response
Feb 28, 2024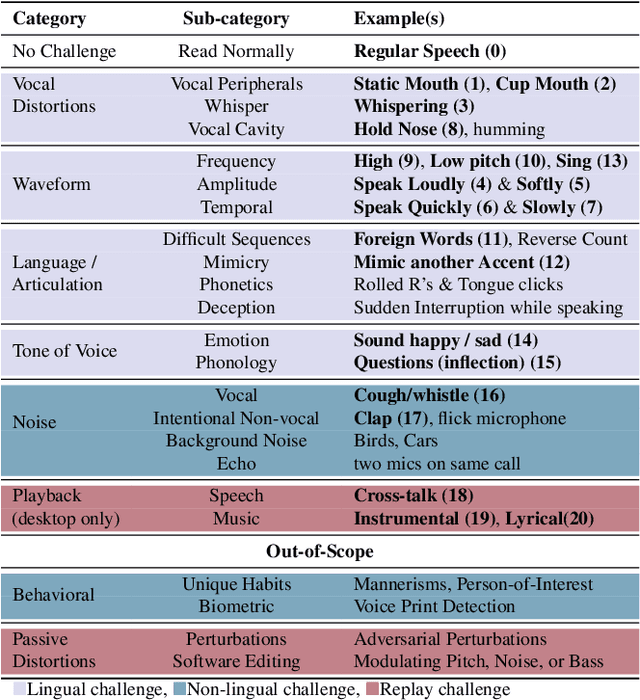
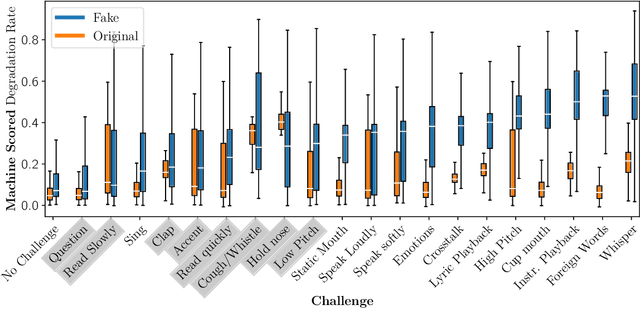
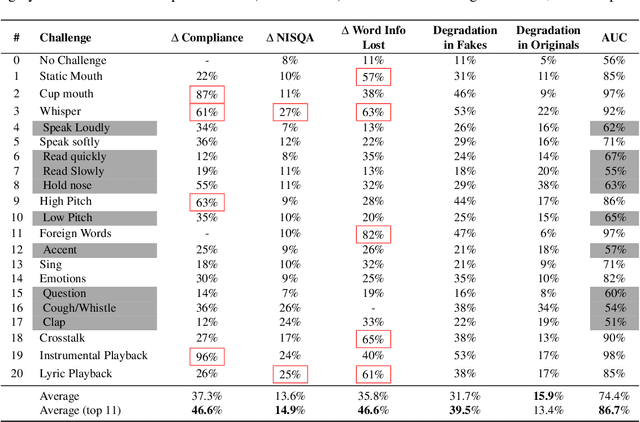
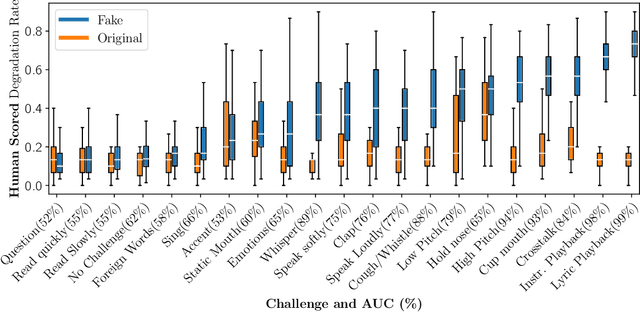
Scammers are aggressively leveraging AI voice-cloning technology for social engineering attacks, a situation significantly worsened by the advent of audio Real-time Deepfakes (RTDFs). RTDFs can clone a target's voice in real-time over phone calls, making these interactions highly interactive and thus far more convincing. Our research confidently addresses the gap in the existing literature on deepfake detection, which has largely been ineffective against RTDF threats. We introduce a robust challenge-response-based method to detect deepfake audio calls, pioneering a comprehensive taxonomy of audio challenges. Our evaluation pitches 20 prospective challenges against a leading voice-cloning system. We have compiled a novel open-source challenge dataset with contributions from 100 smartphone and desktop users, yielding 18,600 original and 1.6 million deepfake samples. Through rigorous machine and human evaluations of this dataset, we achieved a deepfake detection rate of 86% and an 80% AUC score, respectively. Notably, utilizing a set of 11 challenges significantly enhances detection capabilities. Our findings reveal that combining human intuition with machine precision offers complementary advantages. Consequently, we have developed an innovative human-AI collaborative system that melds human discernment with algorithmic accuracy, boosting final joint accuracy to 82.9%. This system highlights the significant advantage of AI-assisted pre-screening in call verification processes. Samples can be heard at https://mittalgovind.github.io/autch-samples/
Information Forensics and Security: A quarter-century-long journey
Sep 21, 2023Information Forensics and Security (IFS) is an active R&D area whose goal is to ensure that people use devices, data, and intellectual properties for authorized purposes and to facilitate the gathering of solid evidence to hold perpetrators accountable. For over a quarter century since the 1990s, the IFS research area has grown tremendously to address the societal needs of the digital information era. The IEEE Signal Processing Society (SPS) has emerged as an important hub and leader in this area, and the article below celebrates some landmark technical contributions. In particular, we highlight the major technological advances on some selected focus areas in the field developed in the last 25 years from the research community and present future trends.