 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZatom-1: A Multimodal Flow Foundation Model for 3D Molecules and Materials
Feb 24, 2026General-purpose 3D chemical modeling encompasses molecules and materials, requiring both generative and predictive capabilities. However, most existing AI approaches are optimized for a single domain (molecules or materials) and a single task (generation or prediction), which limits representation sharing and transfer. We introduce Zatom-1, the first foundation model that unifies generative and predictive learning of 3D molecules and materials. Zatom-1 is a Transformer trained with a multimodal flow matching objective that jointly models discrete atom types and continuous 3D geometries. This approach supports scalable pretraining with predictable gains as model capacity increases, while enabling fast and stable sampling. We use joint generative pretraining as a universal initialization for downstream multi-task prediction of properties, energies, and forces. Empirically, Zatom-1 matches or outperforms specialized baselines on both generative and predictive benchmarks, while reducing the generative inference time by more than an order of magnitude. Our experiments demonstrate positive predictive transfer between chemical domains from joint generative pretraining: modeling materials during pretraining improves molecular property prediction accuracy.
Forging and Removing Latent-Noise Diffusion Watermarks Using a Single Image
Apr 27, 2025Watermarking techniques are vital for protecting intellectual property and preventing fraudulent use of media. Most previous watermarking schemes designed for diffusion models embed a secret key in the initial noise. The resulting pattern is often considered hard to remove and forge into unrelated images. In this paper, we propose a black-box adversarial attack without presuming access to the diffusion model weights. Our attack uses only a single watermarked example and is based on a simple observation: there is a many-to-one mapping between images and initial noises. There are regions in the clean image latent space pertaining to each watermark that get mapped to the same initial noise when inverted. Based on this intuition, we propose an adversarial attack to forge the watermark by introducing perturbations to the images such that we can enter the region of watermarked images. We show that we can also apply a similar approach for watermark removal by learning perturbations to exit this region. We report results on multiple watermarking schemes (Tree-Ring, RingID, WIND, and Gaussian Shading) across two diffusion models (SDv1.4 and SDv2.0). Our results demonstrate the effectiveness of the attack and expose vulnerabilities in the watermarking methods, motivating future research on improving them.
FaceCloak: Learning to Protect Face Templates
Apr 08, 2025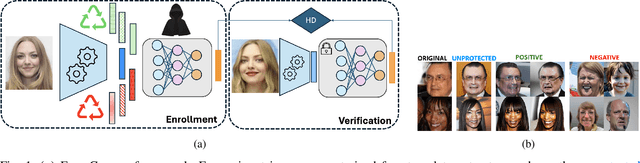
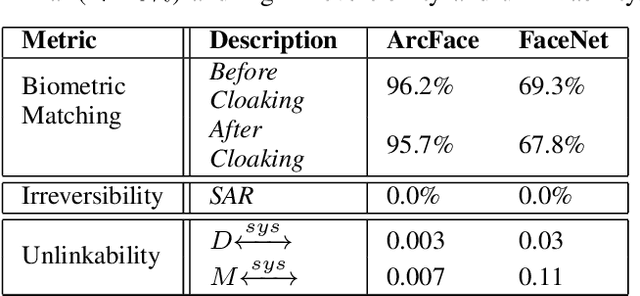
Generative models can reconstruct face images from encoded representations (templates) bearing remarkable likeness to the original face raising security and privacy concerns. We present FaceCloak, a neural network framework that protects face templates by generating smart, renewable binary cloaks. Our method proactively thwarts inversion attacks by cloaking face templates with unique disruptors synthesized from a single face template on the fly while provably retaining biometric utility and unlinkability. Our cloaked templates can suppress sensitive attributes while generalizing to novel feature extraction schemes and outperforms leading baselines in terms of biometric matching and resiliency to reconstruction attacks. FaceCloak-based matching is extremely fast (inference time cost=0.28ms) and light-weight (0.57MB).
TraSCE: Trajectory Steering for Concept Erasure
Dec 10, 2024
Recent advancements in text-to-image diffusion models have brought them to the public spotlight, becoming widely accessible and embraced by everyday users. However, these models have been shown to generate harmful content such as not-safe-for-work (NSFW) images. While approaches have been proposed to erase such abstract concepts from the models, jail-breaking techniques have succeeded in bypassing such safety measures. In this paper, we propose TraSCE, an approach to guide the diffusion trajectory away from generating harmful content. Our approach is based on negative prompting, but as we show in this paper, conventional negative prompting is not a complete solution and can easily be bypassed in some corner cases. To address this issue, we first propose a modification of conventional negative prompting. Furthermore, we introduce a localized loss-based guidance that enhances the modified negative prompting technique by steering the diffusion trajectory. We demonstrate that our proposed method achieves state-of-the-art results on various benchmarks in removing harmful content including ones proposed by red teams; and erasing artistic styles and objects. Our proposed approach does not require any training, weight modifications, or training data (both image or prompt), making it easier for model owners to erase new concepts.
Classifier-Free Guidance inside the Attraction Basin May Cause Memorization
Nov 23, 2024Diffusion models are prone to exactly reproduce images from the training data. This exact reproduction of the training data is concerning as it can lead to copyright infringement and/or leakage of privacy-sensitive information. In this paper, we present a novel way to understand the memorization phenomenon, and propose a simple yet effective approach to mitigate it. We argue that memorization occurs because of an attraction basin in the denoising process which steers the diffusion trajectory towards a memorized image. However, this can be mitigated by guiding the diffusion trajectory away from the attraction basin by not applying classifier-free guidance until an ideal transition point occurs from which classifier-free guidance is applied. This leads to the generation of non-memorized images that are high in image quality and well-aligned with the conditioning mechanism. To further improve on this, we present a new guidance technique, \emph{opposite guidance}, that escapes the attraction basin sooner in the denoising process. We demonstrate the existence of attraction basins in various scenarios in which memorization occurs, and we show that our proposed approach successfully mitigates memorization.
AlabOS: A Python-based Reconfigurable Workflow Management Framework for Autonomous Laboratories
May 22, 2024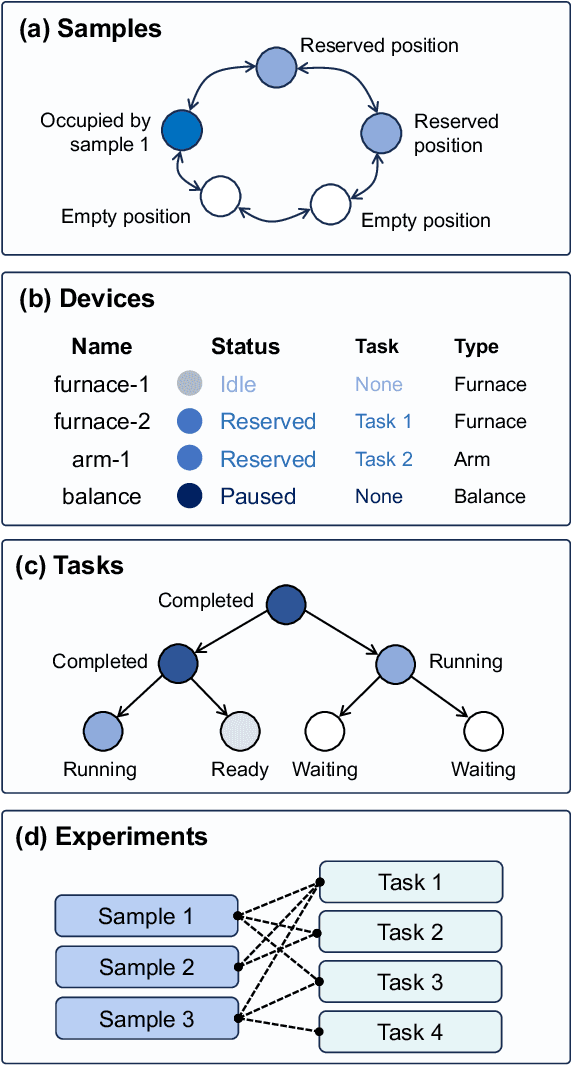
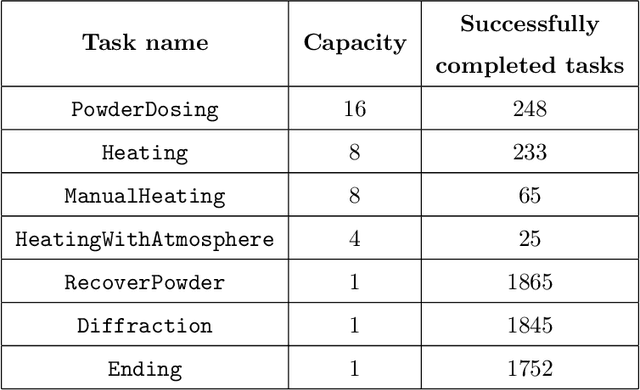
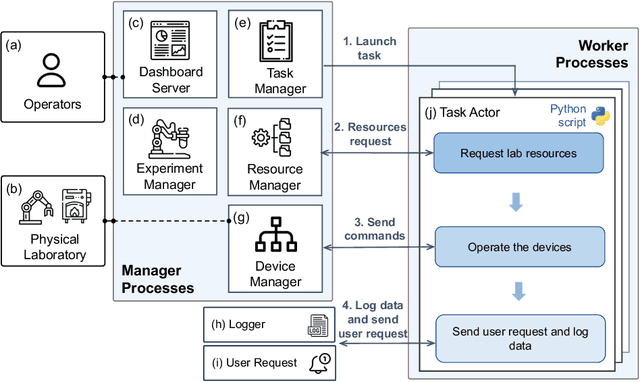
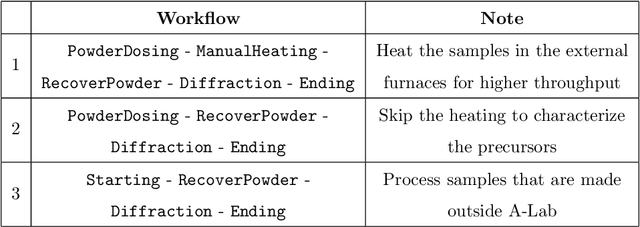
The recent advent of autonomous laboratories, coupled with algorithms for high-throughput screening and active learning, promises to accelerate materials discovery and innovation. As these autonomous systems grow in complexity, the demand for robust and efficient workflow management software becomes increasingly critical. In this paper, we introduce AlabOS, a general-purpose software framework for orchestrating experiments and managing resources, with an emphasis on automated laboratories for materials synthesis and characterization. We demonstrate the implementation of AlabOS in a prototype autonomous materials laboratory. AlabOS features a reconfigurable experiment workflow model, enabling the simultaneous execution of varied workflows composed of modular tasks. Therefore, AlabOS is well-suited to handle the rapidly changing experimental protocols defining the progress of self-driving laboratory development for materials research.
Matbench Discovery -- An evaluation framework for machine learning crystal stability prediction
Aug 28, 2023Matbench Discovery simulates the deployment of machine learning (ML) energy models in a high-throughput search for stable inorganic crystals. We address the disconnect between (i) thermodynamic stability and formation energy and (ii) in-domain vs out-of-distribution performance. Alongside this paper, we publish a Python package to aid with future model submissions and a growing online leaderboard with further insights into trade-offs between various performance metrics. To answer the question which ML methodology performs best at materials discovery, our initial release explores a variety of models including random forests, graph neural networks (GNN), one-shot predictors, iterative Bayesian optimizers and universal interatomic potentials (UIP). Ranked best-to-worst by their test set F1 score on thermodynamic stability prediction, we find CHGNet > M3GNet > MACE > ALIGNN > MEGNet > CGCNN > CGCNN+P > Wrenformer > BOWSR > Voronoi tessellation fingerprints with random forest. The top 3 models are UIPs, the winning methodology for ML-guided materials discovery, achieving F1 scores of ~0.6 for crystal stability classification and discovery acceleration factors (DAF) of up to 5x on the first 10k most stable predictions compared to dummy selection from our test set. We also highlight a sharp disconnect between commonly used global regression metrics and more task-relevant classification metrics. Accurate regressors are susceptible to unexpectedly high false-positive rates if those accurate predictions lie close to the decision boundary at 0 eV/atom above the convex hull where most materials are. Our results highlight the need to focus on classification metrics that actually correlate with improved stability hit rate.
Fair GANs through model rebalancing with synthetic data
Aug 16, 2023Deep generative models require large amounts of training data. This often poses a problem as the collection of datasets can be expensive and difficult, in particular datasets that are representative of the appropriate underlying distribution (e.g. demographic). This introduces biases in datasets which are further propagated in the models. We present an approach to mitigate biases in an existing generative adversarial network by rebalancing the model distribution. We do so by generating balanced data from an existing unbalanced deep generative model using latent space exploration and using this data to train a balanced generative model. Further, we propose a bias mitigation loss function that shows improvements in the fairness metric even when trained with unbalanced datasets. We show results for the Stylegan2 models while training on the FFHQ dataset for racial fairness and see that the proposed approach improves on the fairness metric by almost 5 times, whilst maintaining image quality. We further validate our approach by applying it to an imbalanced Cifar-10 dataset. Lastly, we argue that the traditionally used image quality metrics such as Frechet inception distance (FID) are unsuitable for bias mitigation problems.
Zero-shot racially balanced dataset generation using an existing biased StyleGAN2
May 12, 2023Facial recognition systems have made significant strides thanks to data-heavy deep learning models, but these models rely on large privacy-sensitive datasets. Unfortunately, many of these datasets lack diversity in terms of ethnicity and demographics, which can lead to biased models that can have serious societal and security implications. To address these issues, we propose a methodology that leverages the biased generative model StyleGAN2 to create demographically diverse images of synthetic individuals. The synthetic dataset is created using a novel evolutionary search algorithm that targets specific demographic groups. By training face recognition models with the resulting balanced dataset containing 50,000 identities per race (13.5 million images in total), we can improve their performance and minimize biases that might have been present in a model trained on a real dataset.
Extracting Structured Seed-Mediated Gold Nanorod Growth Procedures from Literature with GPT-3
Apr 26, 2023Although gold nanorods have been the subject of much research, the pathways for controlling their shape and thereby their optical properties remain largely heuristically understood. Although it is apparent that the simultaneous presence of and interaction between various reagents during synthesis control these properties, computational and experimental approaches for exploring the synthesis space can be either intractable or too time-consuming in practice. This motivates an alternative approach leveraging the wealth of synthesis information already embedded in the body of scientific literature by developing tools to extract relevant structured data in an automated, high-throughput manner. To that end, we present an approach using the powerful GPT-3 language model to extract structured multi-step seed-mediated growth procedures and outcomes for gold nanorods from unstructured scientific text. GPT-3 prompt completions are fine-tuned to predict synthesis templates in the form of JSON documents from unstructured text input with an overall accuracy of $86\%$. The performance is notable, considering the model is performing simultaneous entity recognition and relation extraction. We present a dataset of 11,644 entities extracted from 1,137 papers, resulting in 268 papers with at least one complete seed-mediated gold nanorod growth procedure and outcome for a total of 332 complete procedures.