 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Structured Seed-Mediated Gold Nanorod Growth Procedures from Literature with GPT-3
Apr 26, 2023Although gold nanorods have been the subject of much research, the pathways for controlling their shape and thereby their optical properties remain largely heuristically understood. Although it is apparent that the simultaneous presence of and interaction between various reagents during synthesis control these properties, computational and experimental approaches for exploring the synthesis space can be either intractable or too time-consuming in practice. This motivates an alternative approach leveraging the wealth of synthesis information already embedded in the body of scientific literature by developing tools to extract relevant structured data in an automated, high-throughput manner. To that end, we present an approach using the powerful GPT-3 language model to extract structured multi-step seed-mediated growth procedures and outcomes for gold nanorods from unstructured scientific text. GPT-3 prompt completions are fine-tuned to predict synthesis templates in the form of JSON documents from unstructured text input with an overall accuracy of $86\%$. The performance is notable, considering the model is performing simultaneous entity recognition and relation extraction. We present a dataset of 11,644 entities extracted from 1,137 papers, resulting in 268 papers with at least one complete seed-mediated gold nanorod growth procedure and outcome for a total of 332 complete procedures.
Inorganic synthesis recommendation by machine learning materials similarity from scientific literature
Feb 05, 2023Synthesis prediction is a key accelerator for the rapid design of advanced materials. However, determining synthesis variables such as the choice of precursor materials, operations, and conditions is challenging for inorganic materials because the sequence of reactions during heating is not well understood. In this work, we use a knowledge base of 29,900 solid-state synthesis recipes, text-mined from the scientific literature, to automatically learn which precursors to recommend for the synthesis of a novel target material. The data-driven approach learns chemical similarity of materials and refers the synthesis of a new target to precedent synthesis procedures of similar materials, mimicking human synthesis design. When proposing five precursor sets for each of 2,654 unseen test target materials, the recommendation strategy achieves a success rate of at least 82%. Our approach captures decades of heuristic synthesis data in a mathematical form, making it accessible for use in recommendation engines and autonomous laboratories.
ULSA: Unified Language of Synthesis Actions for Representation of Synthesis Protocols
Jan 23, 2022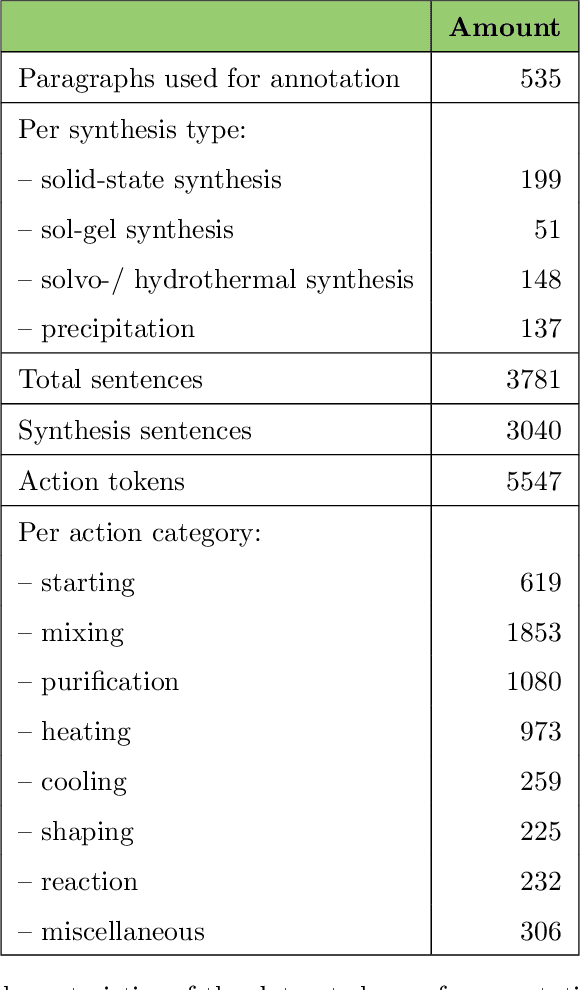
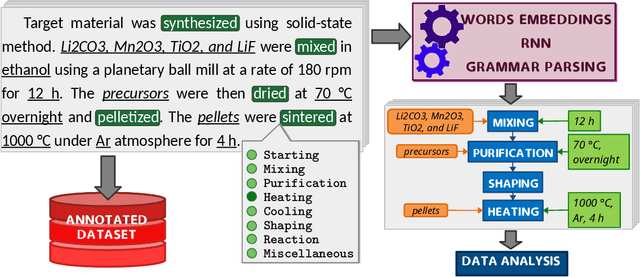
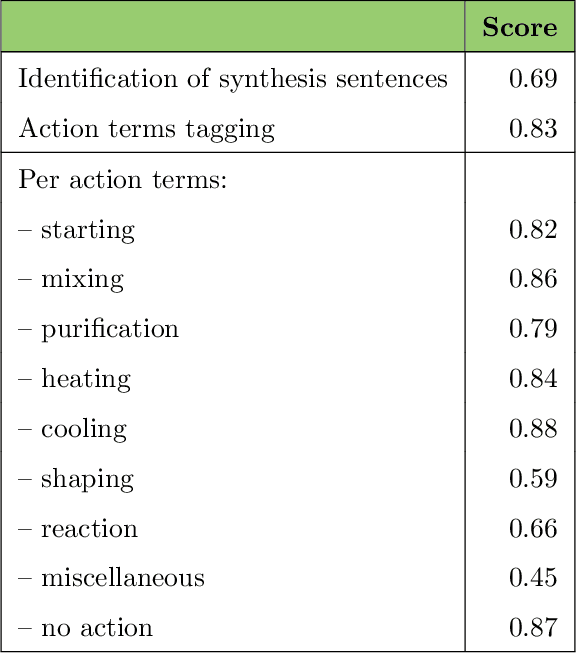
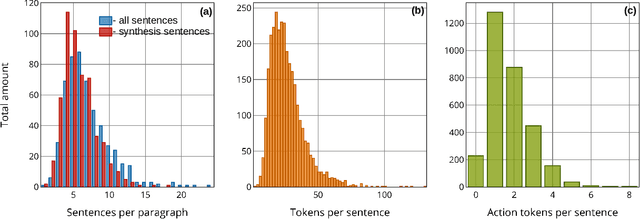
Applying AI power to predict syntheses of novel materials requires high-quality, large-scale datasets. Extraction of synthesis information from scientific publications is still challenging, especially for extracting synthesis actions, because of the lack of a comprehensive labeled dataset using a solid, robust, and well-established ontology for describing synthesis procedures. In this work, we propose the first Unified Language of Synthesis Actions (ULSA) for describing ceramics synthesis procedures. We created a dataset of 3,040 synthesis procedures annotated by domain experts according to the proposed ULSA scheme. To demonstrate the capabilities of ULSA, we built a neural network-based model to map arbitrary ceramics synthesis paragraphs into ULSA and used it to construct synthesis flowcharts for synthesis procedures. Analysis for the flowcharts showed that (a) ULSA covers essential vocabulary used by researchers when describing synthesis procedures and (b) it can capture important features of synthesis protocols. This work is an important step towards creating a synthesis ontology and a solid foundation for autonomous robotic synthesis.
COVIDScholar: An automated COVID-19 research aggregation and analysis platform
Dec 07, 2020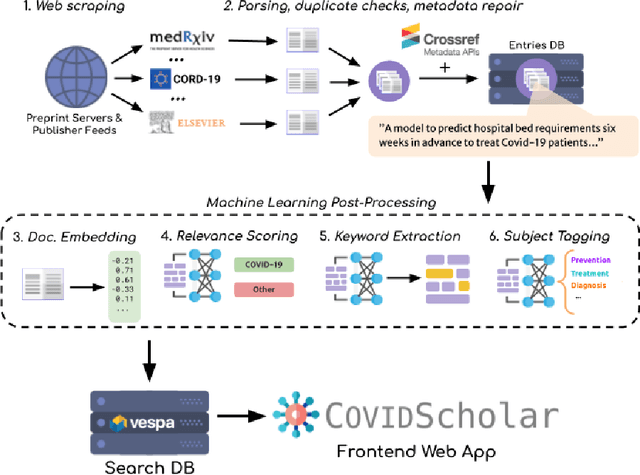
The ongoing COVID-19 pandemic has had far-reaching effects throughout society, and science is no exception. The scale, speed, and breadth of the scientific community's COVID-19 response has lead to the emergence of new research literature on a remarkable scale -- as of October 2020, over 81,000 COVID-19 related scientific papers have been released, at a rate of over 250 per day. This has created a challenge to traditional methods of engagement with the research literature; the volume of new research is far beyond the ability of any human to read, and the urgency of response has lead to an increasingly prominent role for pre-print servers and a diffusion of relevant research across sources. These factors have created a need for new tools to change the way scientific literature is disseminated. COVIDScholar is a knowledge portal designed with the unique needs of the COVID-19 research community in mind, utilizing NLP to aid researchers in synthesizing the information spread across thousands of emergent research articles, patents, and clinical trials into actionable insights and new knowledge. The search interface for this corpus, https://covidscholar.org, now serves over 2000 unique users weekly. We present also an analysis of trends in COVID-19 research over the course of 2020.