 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Preserving Aging of Face Images via Latent Diffusion Models
Paper and Code
Jul 17, 2023
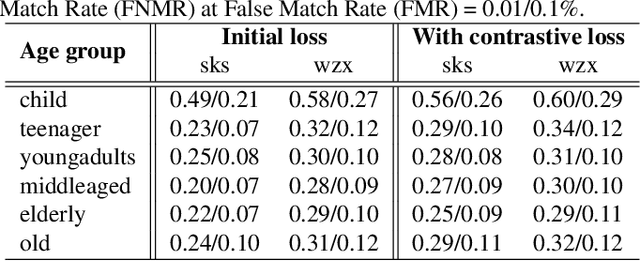


The performance of automated face recognition systems is inevitably impacted by the facial aging process. However, high quality datasets of individuals collected over several years are typically small in scale. In this work, we propose, train, and validate the use of latent text-to-image diffusion models for synthetically aging and de-aging face images. Our models succeed with few-shot training, and have the added benefit of being controllable via intuitive textual prompting. We observe high degrees of visual realism in the generated images while maintaining biometric fidelity measured by commonly used metrics. We evaluate our method on two benchmark datasets (CelebA and AgeDB) and observe significant reduction (~44%) in the False Non-Match Rate compared to existing state-of the-art baselines.