 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Aware Calibration for AI-Generated Image Detection in the Wild
Apr 16, 2026Significant progress has been made in detecting synthetic images, however most existing approaches operate on a single image instance and overlook a key characteristic of real-world dissemination: as viral images circulate on the web, multiple near-duplicate versions appear and lose quality due to repeated operations like recompression, resizing and cropping. As a consequence, the same image may yield inconsistent forensic predictions based on which version has been analyzed. In this work, to address this issue we propose QuAD (Quality-Aware calibration with near-Duplicates) a novel framework that makes decisions based on all available near-duplicates of the same image. Given a query, we retrieve its online near-duplicates and feed them to a detector: the resulting scores are then aggregated based on the estimated quality of the corresponding instance. By doing so, we take advantage of all pieces of information while accounting for the reduced reliability of images impaired by multiple processing steps. To support large-scale evaluation, we introduce two datasets: AncesTree, an in-lab dataset of 136k images organized in stochastic degradation trees that simulate online reposting dynamics, and ReWIND, a real-world dataset of nearly 10k near-duplicate images collected from viral web content. Experiments on several state-of-the-art detectors show that our quality-aware fusion improves their performance consistently, with an average gain of around 8% in terms of balanced accuracy compared to plain average. Our results highlight the importance of jointly processing all the images available online to achieve reliable detection of AI-generated content in real-world applications. Code and data are publicly available at https://grip-unina.github.io/QuAD/
Don't Guess, Escalate: Towards Explainable Uncertainty-Calibrated AI Forensic Agents
Dec 18, 2025AI is reshaping the landscape of multimedia forensics. We propose AI forensic agents: reliable orchestrators that select and combine forensic detectors, identify provenance and context, and provide uncertainty-aware assessments. We highlight pitfalls in current solutions and introduce a unified framework to improve the authenticity verification process.
AI-GenBench: A New Ongoing Benchmark for AI-Generated Image Detection
Apr 29, 2025



The rapid advancement of generative AI has revolutionized image creation, enabling high-quality synthesis from text prompts while raising critical challenges for media authenticity. We present Ai-GenBench, a novel benchmark designed to address the urgent need for robust detection of AI-generated images in real-world scenarios. Unlike existing solutions that evaluate models on static datasets, Ai-GenBench introduces a temporal evaluation framework where detection methods are incrementally trained on synthetic images, historically ordered by their generative models, to test their ability to generalize to new generative models, such as the transition from GANs to diffusion models. Our benchmark focuses on high-quality, diverse visual content and overcomes key limitations of current approaches, including arbitrary dataset splits, unfair comparisons, and excessive computational demands. Ai-GenBench provides a comprehensive dataset, a standardized evaluation protocol, and accessible tools for both researchers and non-experts (e.g., journalists, fact-checkers), ensuring reproducibility while maintaining practical training requirements. By establishing clear evaluation rules and controlled augmentation strategies, Ai-GenBench enables meaningful comparison of detection methods and scalable solutions. Code and data are publicly available to ensure reproducibility and to support the development of robust forensic detectors to keep pace with the rise of new synthetic generators.
A Bias-Free Training Paradigm for More General AI-generated Image Detection
Dec 23, 2024Successful forensic detectors can produce excellent results in supervised learning benchmarks but struggle to transfer to real-world applications. We believe this limitation is largely due to inadequate training data quality. While most research focuses on developing new algorithms, less attention is given to training data selection, despite evidence that performance can be strongly impacted by spurious correlations such as content, format, or resolution. A well-designed forensic detector should detect generator specific artifacts rather than reflect data biases. To this end, we propose B-Free, a bias-free training paradigm, where fake images are generated from real ones using the conditioning procedure of stable diffusion models. This ensures semantic alignment between real and fake images, allowing any differences to stem solely from the subtle artifacts introduced by AI generation. Through content-based augmentation, we show significant improvements in both generalization and robustness over state-of-the-art detectors and more calibrated results across 27 different generative models, including recent releases, like FLUX and Stable Diffusion 3.5. Our findings emphasize the importance of a careful dataset curation, highlighting the need for further research in dataset design. Code and data will be publicly available at https://grip-unina.github.io/B-Free/
Zero-Shot Detection of AI-Generated Images
Sep 24, 2024Detecting AI-generated images has become an extraordinarily difficult challenge as new generative architectures emerge on a daily basis with more and more capabilities and unprecedented realism. New versions of many commercial tools, such as DALLE, Midjourney, and Stable Diffusion, have been released recently, and it is impractical to continually update and retrain supervised forensic detectors to handle such a large variety of models. To address this challenge, we propose a zero-shot entropy-based detector (ZED) that neither needs AI-generated training data nor relies on knowledge of generative architectures to artificially synthesize their artifacts. Inspired by recent works on machine-generated text detection, our idea is to measure how surprising the image under analysis is compared to a model of real images. To this end, we rely on a lossless image encoder that estimates the probability distribution of each pixel given its context. To ensure computational efficiency, the encoder has a multi-resolution architecture and contexts comprise mostly pixels of the lower-resolution version of the image.Since only real images are needed to learn the model, the detector is independent of generator architectures and synthetic training data. Using a single discriminative feature, the proposed detector achieves state-of-the-art performance. On a wide variety of generative models it achieves an average improvement of more than 3% over the SoTA in terms of accuracy. Code is available at https://grip-unina.github.io/ZED/.
Exploring the Adversarial Robustness of CLIP for AI-generated Image Detection
Jul 28, 2024In recent years, many forensic detectors have been proposed to detect AI-generated images and prevent their use for malicious purposes. Convolutional neural networks (CNNs) have long been the dominant architecture in this field and have been the subject of intense study. However, recently proposed Transformer-based detectors have been shown to match or even outperform CNN-based detectors, especially in terms of generalization. In this paper, we study the adversarial robustness of AI-generated image detectors, focusing on Contrastive Language-Image Pretraining (CLIP)-based methods that rely on Visual Transformer backbones and comparing their performance with CNN-based methods. We study the robustness to different adversarial attacks under a variety of conditions and analyze both numerical results and frequency-domain patterns. CLIP-based detectors are found to be vulnerable to white-box attacks just like CNN-based detectors. However, attacks do not easily transfer between CNN-based and CLIP-based methods. This is also confirmed by the different distribution of the adversarial noise patterns in the frequency domain. Overall, this analysis provides new insights into the properties of forensic detectors that can help to develop more effective strategies.
Training-Free Deepfake Voice Recognition by Leveraging Large-Scale Pre-Trained Models
May 06, 2024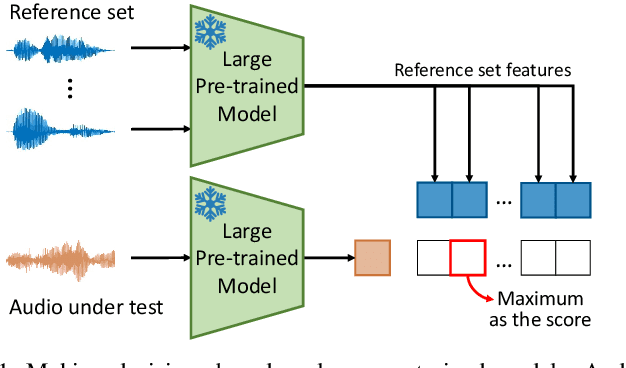
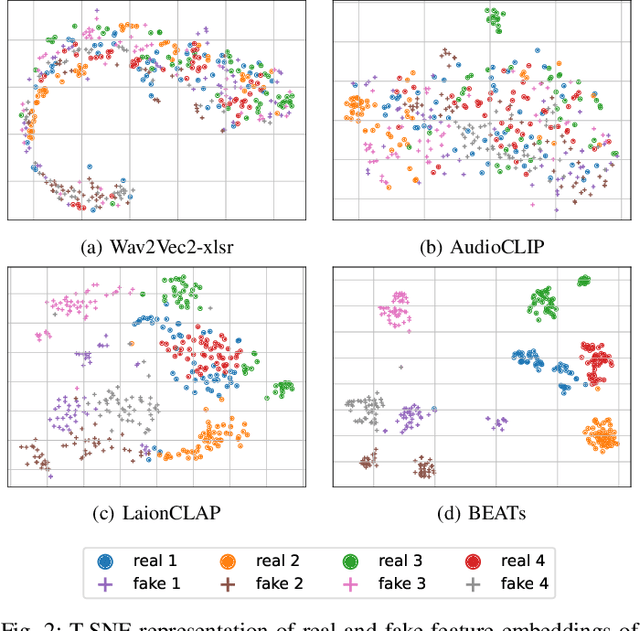

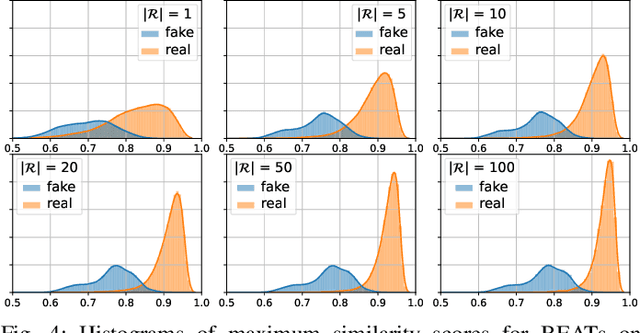
Generalization is a main issue for current audio deepfake detectors, which struggle to provide reliable results on out-of-distribution data. Given the speed at which more and more accurate synthesis methods are developed, it is very important to design techniques that work well also on data they were not trained for. In this paper we study the potential of large-scale pre-trained models for audio deepfake detection, with special focus on generalization ability. To this end, the detection problem is reformulated in a speaker verification framework and fake audios are exposed by the mismatch between the voice sample under test and the voice of the claimed identity. With this paradigm, no fake speech sample is necessary in training, cutting off any link with the generation method at the root, and ensuring full generalization ability. Features are extracted by general-purpose large pre-trained models, with no need for training or fine-tuning on specific fake detection or speaker verification datasets. At detection time only a limited set of voice fragments of the identity under test is required. Experiments on several datasets widespread in the community show that detectors based on pre-trained models achieve excellent performance and show strong generalization ability, rivaling supervised methods on in-distribution data and largely overcoming them on out-of-distribution data.
Synthetic Image Verification in the Era of Generative AI: What Works and What Isn't There Yet
Apr 30, 2024

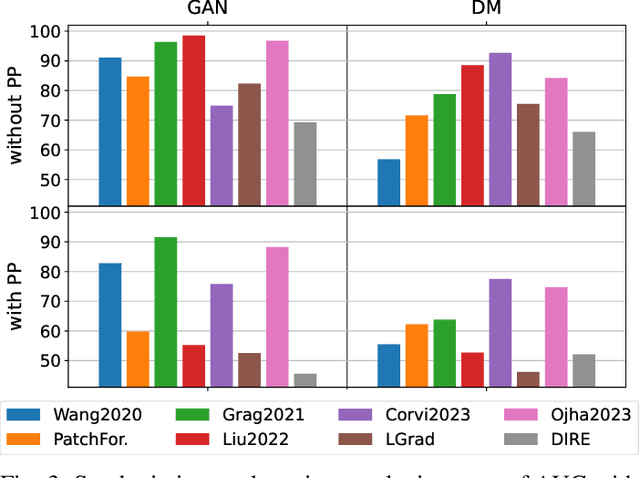
In this work we present an overview of approaches for the detection and attribution of synthetic images and highlight their strengths and weaknesses. We also point out and discuss hot topics in this field and outline promising directions for future research.
Detecting Multimedia Generated by Large AI Models: A Survey
Feb 07, 2024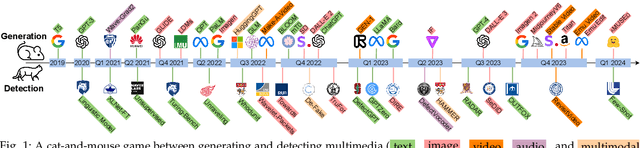
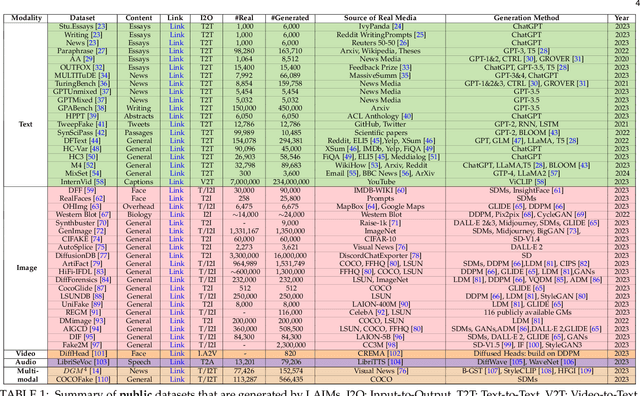
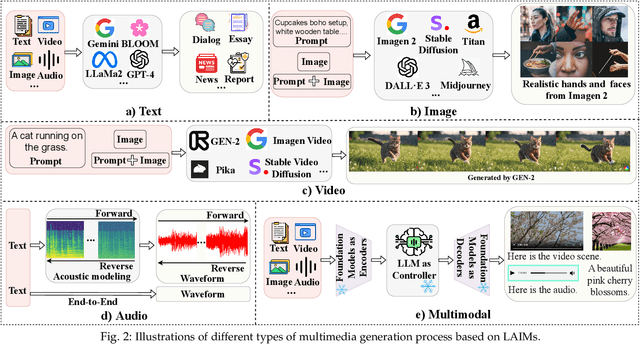
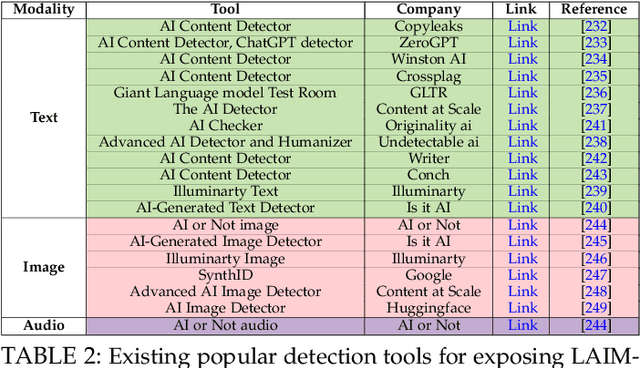
The rapid advancement of Large AI Models (LAIMs), particularly diffusion models and large language models, has marked a new era where AI-generated multimedia is increasingly integrated into various aspects of daily life. Although beneficial in numerous fields, this content presents significant risks, including potential misuse, societal disruptions, and ethical concerns. Consequently, detecting multimedia generated by LAIMs has become crucial, with a marked rise in related research. Despite this, there remains a notable gap in systematic surveys that focus specifically on detecting LAIM-generated multimedia. Addressing this, we provide the first survey to comprehensively cover existing research on detecting multimedia (such as text, images, videos, audio, and multimodal content) created by LAIMs. Specifically, we introduce a novel taxonomy for detection methods, categorized by media modality, and aligned with two perspectives: pure detection (aiming to enhance detection performance) and beyond detection (adding attributes like generalizability, robustness, and interpretability to detectors). Additionally, we have presented a brief overview of generation mechanisms, public datasets, and online detection tools to provide a valuable resource for researchers and practitioners in this field. Furthermore, we identify current challenges in detection and propose directions for future research that address unexplored, ongoing, and emerging issues in detecting multimedia generated by LAIMs. Our aim for this survey is to fill an academic gap and contribute to global AI security efforts, helping to ensure the integrity of information in the digital realm. The project link is https://github.com/Purdue-M2/Detect-LAIM-generated-Multimedia-Survey.
HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Dec 21, 2023Current advances in human head modeling allow to generate plausible-looking 3D head models via neural representations. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g. coming from a depth sensor, while preserving details is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM which allows explicit animation and high-detail preservation at the same time. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model in order to generalize over the UV maps of displacements. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify it semantically. We demonstrate the results of unconditional generation and fitting to the full or partial observation. The project page is available at https://seva100.github.io/headcraft.