 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Deepfake Voice Recognition by Leveraging Large-Scale Pre-Trained Models
May 06, 2024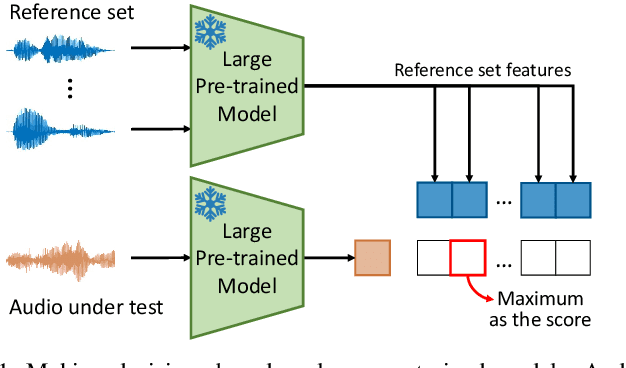
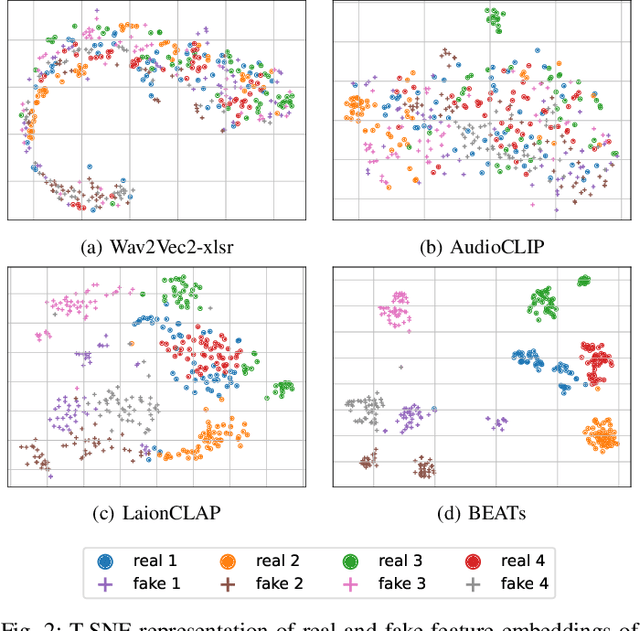

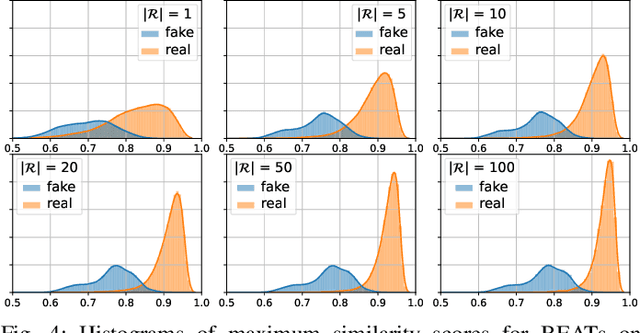
Generalization is a main issue for current audio deepfake detectors, which struggle to provide reliable results on out-of-distribution data. Given the speed at which more and more accurate synthesis methods are developed, it is very important to design techniques that work well also on data they were not trained for. In this paper we study the potential of large-scale pre-trained models for audio deepfake detection, with special focus on generalization ability. To this end, the detection problem is reformulated in a speaker verification framework and fake audios are exposed by the mismatch between the voice sample under test and the voice of the claimed identity. With this paradigm, no fake speech sample is necessary in training, cutting off any link with the generation method at the root, and ensuring full generalization ability. Features are extracted by general-purpose large pre-trained models, with no need for training or fine-tuning on specific fake detection or speaker verification datasets. At detection time only a limited set of voice fragments of the identity under test is required. Experiments on several datasets widespread in the community show that detectors based on pre-trained models achieve excellent performance and show strong generalization ability, rivaling supervised methods on in-distribution data and largely overcoming them on out-of-distribution data.
Deepfake audio detection by speaker verification
Sep 28, 2022

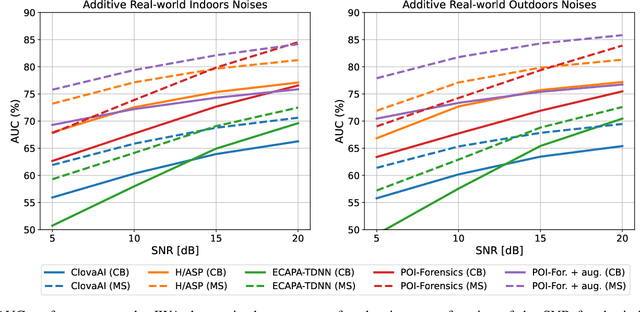

Thanks to recent advances in deep learning, sophisticated generation tools exist, nowadays, that produce extremely realistic synthetic speech. However, malicious uses of such tools are possible and likely, posing a serious threat to our society. Hence, synthetic voice detection has become a pressing research topic, and a large variety of detection methods have been recently proposed. Unfortunately, they hardly generalize to synthetic audios generated by tools never seen in the training phase, which makes them unfit to face real-world scenarios. In this work, we aim at overcoming this issue by proposing a new detection approach that leverages only the biometric characteristics of the speaker, with no reference to specific manipulations. Since the detector is trained only on real data, generalization is automatically ensured. The proposed approach can be implemented based on off-the-shelf speaker verification tools. We test several such solutions on three popular test sets, obtaining good performance, high generalization ability, and high robustness to audio impairment.