 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Hyperspectral Pansharpening Using Hysteresis-Based Tuning for Spectral Quality Control
May 22, 2025Hyperspectral pansharpening has received much attention in recent years due to technological and methodological advances that open the door to new application scenarios. However, research on this topic is only now gaining momentum. The most popular methods are still borrowed from the more mature field of multispectral pansharpening and often overlook the unique challenges posed by hyperspectral data fusion, such as i) the very large number of bands, ii) the overwhelming noise in selected spectral ranges, iii) the significant spectral mismatch between panchromatic and hyperspectral components, iv) a typically high resolution ratio. Imprecise data modeling especially affects spectral fidelity. Even state-of-the-art methods perform well in certain spectral ranges and much worse in others, failing to ensure consistent quality across all bands, with the risk of generating unreliable results. Here, we propose a hyperspectral pansharpening method that explicitly addresses this problem and ensures uniform spectral quality. To this end, a single lightweight neural network is used, with weights that adapt on the fly to each band. During fine-tuning, the spatial loss is turned on and off to ensure a fast convergence of the spectral loss to the desired level, according to a hysteresis-like dynamic. Furthermore, the spatial loss itself is appropriately redefined to account for nonlinear dependencies between panchromatic and spectral bands. Overall, the proposed method is fully unsupervised, with no prior training on external data, flexible, and low-complexity. Experiments on a recently published benchmarking toolbox show that it ensures excellent sharpening quality, competitive with the state-of-the-art, consistently across all bands. The software code and the full set of results are shared online on https://github.com/giu-guarino/rho-PNN.
Zero-Shot Detection of AI-Generated Images
Sep 24, 2024Detecting AI-generated images has become an extraordinarily difficult challenge as new generative architectures emerge on a daily basis with more and more capabilities and unprecedented realism. New versions of many commercial tools, such as DALLE, Midjourney, and Stable Diffusion, have been released recently, and it is impractical to continually update and retrain supervised forensic detectors to handle such a large variety of models. To address this challenge, we propose a zero-shot entropy-based detector (ZED) that neither needs AI-generated training data nor relies on knowledge of generative architectures to artificially synthesize their artifacts. Inspired by recent works on machine-generated text detection, our idea is to measure how surprising the image under analysis is compared to a model of real images. To this end, we rely on a lossless image encoder that estimates the probability distribution of each pixel given its context. To ensure computational efficiency, the encoder has a multi-resolution architecture and contexts comprise mostly pixels of the lower-resolution version of the image.Since only real images are needed to learn the model, the detector is independent of generator architectures and synthetic training data. Using a single discriminative feature, the proposed detector achieves state-of-the-art performance. On a wide variety of generative models it achieves an average improvement of more than 3% over the SoTA in terms of accuracy. Code is available at https://grip-unina.github.io/ZED/.
Exploring the Adversarial Robustness of CLIP for AI-generated Image Detection
Jul 28, 2024In recent years, many forensic detectors have been proposed to detect AI-generated images and prevent their use for malicious purposes. Convolutional neural networks (CNNs) have long been the dominant architecture in this field and have been the subject of intense study. However, recently proposed Transformer-based detectors have been shown to match or even outperform CNN-based detectors, especially in terms of generalization. In this paper, we study the adversarial robustness of AI-generated image detectors, focusing on Contrastive Language-Image Pretraining (CLIP)-based methods that rely on Visual Transformer backbones and comparing their performance with CNN-based methods. We study the robustness to different adversarial attacks under a variety of conditions and analyze both numerical results and frequency-domain patterns. CLIP-based detectors are found to be vulnerable to white-box attacks just like CNN-based detectors. However, attacks do not easily transfer between CNN-based and CLIP-based methods. This is also confirmed by the different distribution of the adversarial noise patterns in the frequency domain. Overall, this analysis provides new insights into the properties of forensic detectors that can help to develop more effective strategies.
Hyperspectral Pansharpening: Critical Review, Tools and Future Perspectives
Jul 01, 2024Hyperspectral pansharpening consists of fusing a high-resolution panchromatic band and a low-resolution hyperspectral image to obtain a new image with high resolution in both the spatial and spectral domains. These remote sensing products are valuable for a wide range of applications, driving ever growing research efforts. Nonetheless, results still do not meet application demands. In part, this comes from the technical complexity of the task: compared to multispectral pansharpening, many more bands are involved, in a spectral range only partially covered by the panchromatic component and with overwhelming noise. However, another major limiting factor is the absence of a comprehensive framework for the rapid development and accurate evaluation of new methods. This paper attempts to address this issue. We started by designing a dataset large and diverse enough to allow reliable training (for data-driven methods) and testing of new methods. Then, we selected a set of state-of-the-art methods, following different approaches, characterized by promising performance, and reimplemented them in a single PyTorch framework. Finally, we carried out a critical comparative analysis of all methods, using the most accredited quality indicators. The analysis highlights the main limitations of current solutions in terms of spectral/spatial quality and computational efficiency, and suggests promising research directions. To ensure full reproducibility of the results and support future research, the framework (including codes, evaluation procedures and links to the dataset) is shared on https://github.com/matciotola/hyperspectral_pansharpening_toolbox, as a single Python-based reference benchmark toolbox.
Training-Free Deepfake Voice Recognition by Leveraging Large-Scale Pre-Trained Models
May 06, 2024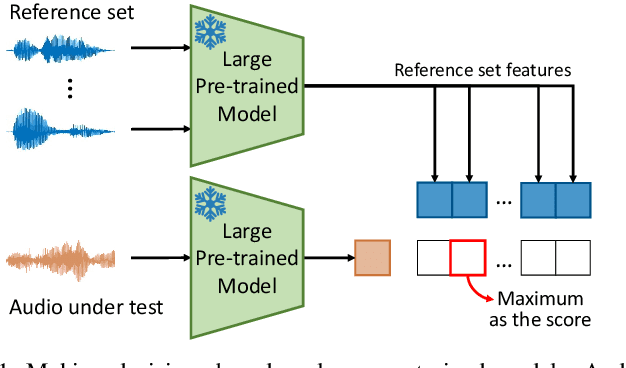
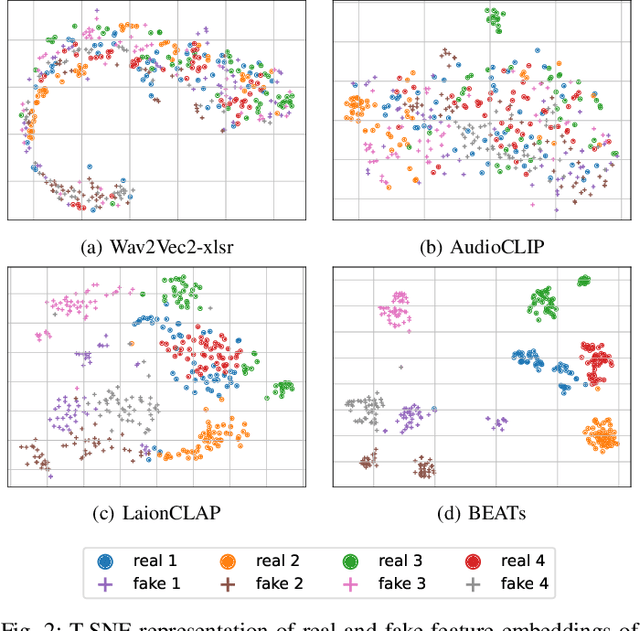

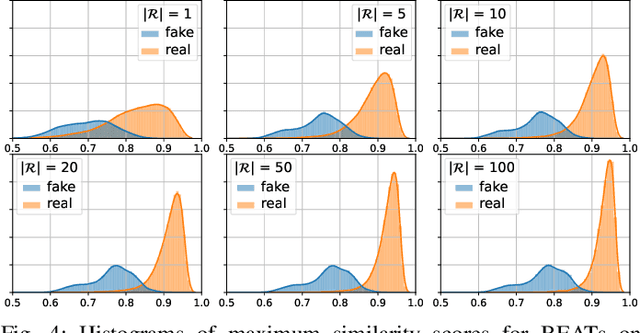
Generalization is a main issue for current audio deepfake detectors, which struggle to provide reliable results on out-of-distribution data. Given the speed at which more and more accurate synthesis methods are developed, it is very important to design techniques that work well also on data they were not trained for. In this paper we study the potential of large-scale pre-trained models for audio deepfake detection, with special focus on generalization ability. To this end, the detection problem is reformulated in a speaker verification framework and fake audios are exposed by the mismatch between the voice sample under test and the voice of the claimed identity. With this paradigm, no fake speech sample is necessary in training, cutting off any link with the generation method at the root, and ensuring full generalization ability. Features are extracted by general-purpose large pre-trained models, with no need for training or fine-tuning on specific fake detection or speaker verification datasets. At detection time only a limited set of voice fragments of the identity under test is required. Experiments on several datasets widespread in the community show that detectors based on pre-trained models achieve excellent performance and show strong generalization ability, rivaling supervised methods on in-distribution data and largely overcoming them on out-of-distribution data.
Synthetic Image Verification in the Era of Generative AI: What Works and What Isn't There Yet
Apr 30, 2024

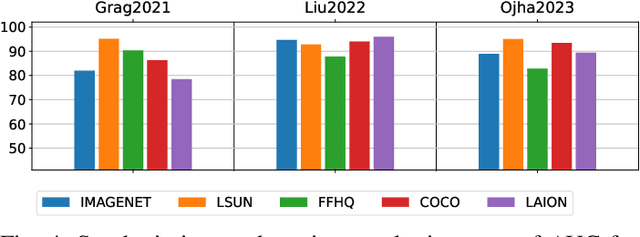
In this work we present an overview of approaches for the detection and attribution of synthetic images and highlight their strengths and weaknesses. We also point out and discuss hot topics in this field and outline promising directions for future research.
Raising the Bar of AI-generated Image Detection with CLIP
Nov 30, 2023



Aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, unlike previous belief, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits a surprising generalization ability and high robustness across several different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the SoTA on in-distribution data, and improve largely above it in terms of generalization to out-of-distribution data (+6% in terms of AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
M3Dsynth: A dataset of medical 3D images with AI-generated local manipulations
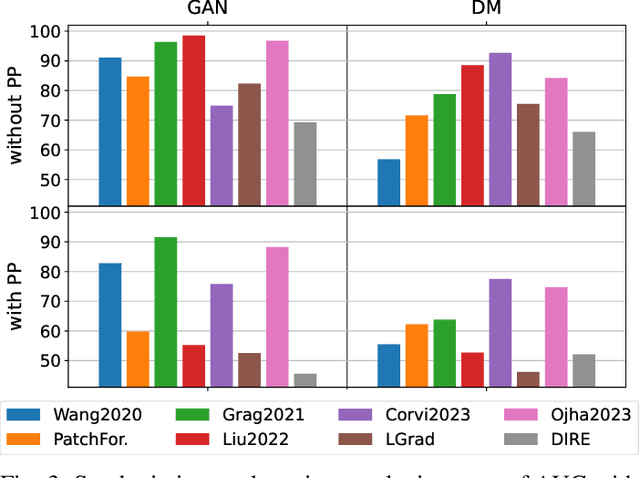
Sep 14, 2023The ability to detect manipulated visual content is becoming increasingly important in many application fields, given the rapid advances in image synthesis methods. Of particular concern is the possibility of modifying the content of medical images, altering the resulting diagnoses. Despite its relevance, this issue has received limited attention from the research community. One reason is the lack of large and curated datasets to use for development and benchmarking purposes. Here, we investigate this issue and propose M3Dsynth, a large dataset of manipulated Computed Tomography (CT) lung images. We create manipulated images by injecting or removing lung cancer nodules in real CT scans, using three different methods based on Generative Adversarial Networks (GAN) or Diffusion Models (DM), for a total of 8,577 manipulated samples. Experiments show that these images easily fool automated diagnostic tools. We also tested several state-of-the-art forensic detectors and demonstrated that, once trained on the proposed dataset, they are able to accurately detect and localize manipulated synthetic content, including when training and test sets are not aligned, showing good generalization ability. Dataset and code will be publicly available at https://grip-unina.github.io/M3Dsynth/.
A full-resolution training framework for Sentinel-2 image fusion
Jul 27, 2023

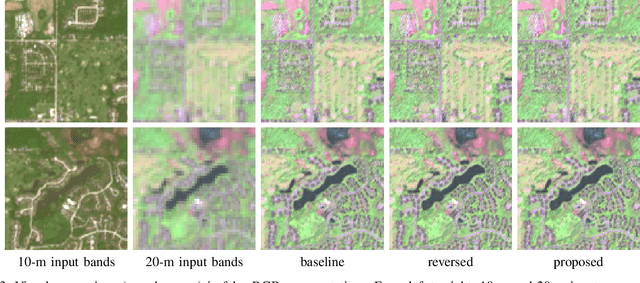
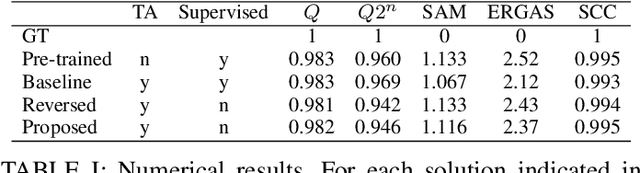
This work presents a new unsupervised framework for training deep learning models for super-resolution of Sentinel-2 images by fusion of its 10-m and 20-m bands. The proposed scheme avoids the resolution downgrade process needed to generate training data in the supervised case. On the other hand, a proper loss that accounts for cycle-consistency between the network prediction and the input components to be fused is proposed. Despite its unsupervised nature, in our preliminary experiments the proposed scheme has shown promising results in comparison to the supervised approach. Besides, by construction of the proposed loss, the resulting trained network can be ascribed to the class of multi-resolution analysis methods.
Unsupervised Deep Learning-based Pansharpening with Jointly-Enhanced Spectral and Spatial Fidelity
Jul 26, 2023In latest years, deep learning has gained a leading role in the pansharpening of multiresolution images. Given the lack of ground truth data, most deep learning-based methods carry out supervised training in a reduced-resolution domain. However, models trained on downsized images tend to perform poorly on high-resolution target images. For this reason, several research groups are now turning to unsupervised training in the full-resolution domain, through the definition of appropriate loss functions and training paradigms. In this context, we have recently proposed a full-resolution training framework which can be applied to many existing architectures. Here, we propose a new deep learning-based pansharpening model that fully exploits the potential of this approach and provides cutting-edge performance. Besides architectural improvements with respect to previous work, such as the use of residual attention modules, the proposed model features a novel loss function that jointly promotes the spectral and spatial quality of the pansharpened data. In addition, thanks to a new fine-tuning strategy, it improves inference-time adaptation to target images. Experiments on a large variety of test images, performed in challenging scenarios, demonstrate that the proposed method compares favorably with the state of the art both in terms of numerical results and visual output. Code is available online at https://github.com/matciotola/Lambda-PNN.