 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Image Verification in the Era of Generative AI: What Works and What Isn't There Yet
Apr 30, 2024

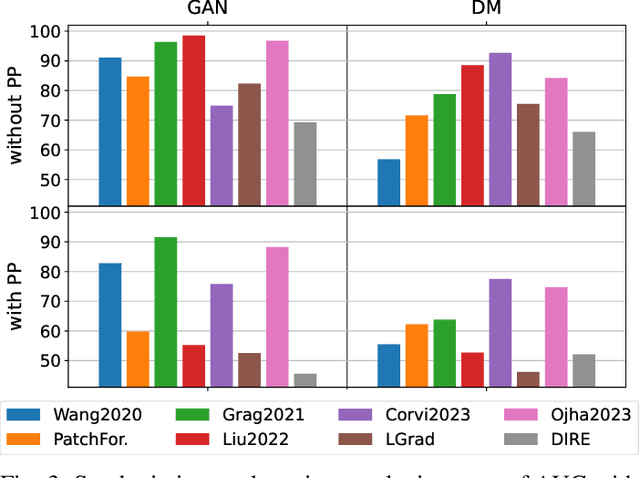
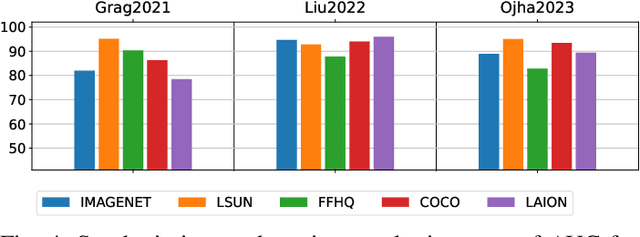
In this work we present an overview of approaches for the detection and attribution of synthetic images and highlight their strengths and weaknesses. We also point out and discuss hot topics in this field and outline promising directions for future research.
Raising the Bar of AI-generated Image Detection with CLIP
Nov 30, 2023



Aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, unlike previous belief, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits a surprising generalization ability and high robustness across several different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the SoTA on in-distribution data, and improve largely above it in terms of generalization to out-of-distribution data (+6% in terms of AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
M3Dsynth: A dataset of medical 3D images with AI-generated local manipulations
Sep 14, 2023The ability to detect manipulated visual content is becoming increasingly important in many application fields, given the rapid advances in image synthesis methods. Of particular concern is the possibility of modifying the content of medical images, altering the resulting diagnoses. Despite its relevance, this issue has received limited attention from the research community. One reason is the lack of large and curated datasets to use for development and benchmarking purposes. Here, we investigate this issue and propose M3Dsynth, a large dataset of manipulated Computed Tomography (CT) lung images. We create manipulated images by injecting or removing lung cancer nodules in real CT scans, using three different methods based on Generative Adversarial Networks (GAN) or Diffusion Models (DM), for a total of 8,577 manipulated samples. Experiments show that these images easily fool automated diagnostic tools. We also tested several state-of-the-art forensic detectors and demonstrated that, once trained on the proposed dataset, they are able to accurately detect and localize manipulated synthetic content, including when training and test sets are not aligned, showing good generalization ability. Dataset and code will be publicly available at https://grip-unina.github.io/M3Dsynth/.
Intriguing properties of synthetic images: from generative adversarial networks to diffusion models
Apr 13, 2023



Detecting fake images is becoming a major goal of computer vision. This need is becoming more and more pressing with the continuous improvement of synthesis methods based on Generative Adversarial Networks (GAN), and even more with the appearance of powerful methods based on Diffusion Models (DM). Towards this end, it is important to gain insight into which image features better discriminate fake images from real ones. In this paper we report on our systematic study of a large number of image generators of different families, aimed at discovering the most forensically relevant characteristics of real and generated images. Our experiments provide a number of interesting observations and shed light on some intriguing properties of synthetic images: (1) not only the GAN models but also the DM and VQ-GAN (Vector Quantized Generative Adversarial Networks) models give rise to visible artifacts in the Fourier domain and exhibit anomalous regular patterns in the autocorrelation; (2) when the dataset used to train the model lacks sufficient variety, its biases can be transferred to the generated images; (3) synthetic and real images exhibit significant differences in the mid-high frequency signal content, observable in their radial and angular spectral power distributions.
On the detection of synthetic images generated by diffusion models
Nov 01, 2022



Over the past decade, there has been tremendous progress in creating synthetic media, mainly thanks to the development of powerful methods based on generative adversarial networks (GAN). Very recently, methods based on diffusion models (DM) have been gaining the spotlight. In addition to providing an impressive level of photorealism, they enable the creation of text-based visual content, opening up new and exciting opportunities in many different application fields, from arts to video games. On the other hand, this property is an additional asset in the hands of malicious users, who can generate and distribute fake media perfectly adapted to their attacks, posing new challenges to the media forensic community. With this work, we seek to understand how difficult it is to distinguish synthetic images generated by diffusion models from pristine ones and whether current state-of-the-art detectors are suitable for the task. To this end, first we expose the forensics traces left by diffusion models, then study how current detectors, developed for GAN-generated images, perform on these new synthetic images, especially in challenging social-networks scenarios involving image compression and resizing. Datasets and code are available at github.com/grip-unina/DMimageDetection.