 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Hyperspectral Pansharpening Using Hysteresis-Based Tuning for Spectral Quality Control
May 22, 2025Hyperspectral pansharpening has received much attention in recent years due to technological and methodological advances that open the door to new application scenarios. However, research on this topic is only now gaining momentum. The most popular methods are still borrowed from the more mature field of multispectral pansharpening and often overlook the unique challenges posed by hyperspectral data fusion, such as i) the very large number of bands, ii) the overwhelming noise in selected spectral ranges, iii) the significant spectral mismatch between panchromatic and hyperspectral components, iv) a typically high resolution ratio. Imprecise data modeling especially affects spectral fidelity. Even state-of-the-art methods perform well in certain spectral ranges and much worse in others, failing to ensure consistent quality across all bands, with the risk of generating unreliable results. Here, we propose a hyperspectral pansharpening method that explicitly addresses this problem and ensures uniform spectral quality. To this end, a single lightweight neural network is used, with weights that adapt on the fly to each band. During fine-tuning, the spatial loss is turned on and off to ensure a fast convergence of the spectral loss to the desired level, according to a hysteresis-like dynamic. Furthermore, the spatial loss itself is appropriately redefined to account for nonlinear dependencies between panchromatic and spectral bands. Overall, the proposed method is fully unsupervised, with no prior training on external data, flexible, and low-complexity. Experiments on a recently published benchmarking toolbox show that it ensures excellent sharpening quality, competitive with the state-of-the-art, consistently across all bands. The software code and the full set of results are shared online on https://github.com/giu-guarino/rho-PNN.
Hyperspectral Pansharpening: Critical Review, Tools and Future Perspectives
Jul 01, 2024Hyperspectral pansharpening consists of fusing a high-resolution panchromatic band and a low-resolution hyperspectral image to obtain a new image with high resolution in both the spatial and spectral domains. These remote sensing products are valuable for a wide range of applications, driving ever growing research efforts. Nonetheless, results still do not meet application demands. In part, this comes from the technical complexity of the task: compared to multispectral pansharpening, many more bands are involved, in a spectral range only partially covered by the panchromatic component and with overwhelming noise. However, another major limiting factor is the absence of a comprehensive framework for the rapid development and accurate evaluation of new methods. This paper attempts to address this issue. We started by designing a dataset large and diverse enough to allow reliable training (for data-driven methods) and testing of new methods. Then, we selected a set of state-of-the-art methods, following different approaches, characterized by promising performance, and reimplemented them in a single PyTorch framework. Finally, we carried out a critical comparative analysis of all methods, using the most accredited quality indicators. The analysis highlights the main limitations of current solutions in terms of spectral/spatial quality and computational efficiency, and suggests promising research directions. To ensure full reproducibility of the results and support future research, the framework (including codes, evaluation procedures and links to the dataset) is shared on https://github.com/matciotola/hyperspectral_pansharpening_toolbox, as a single Python-based reference benchmark toolbox.
Band-wise Hyperspectral Image Pansharpening using CNN Model Propagation
Nov 11, 2023



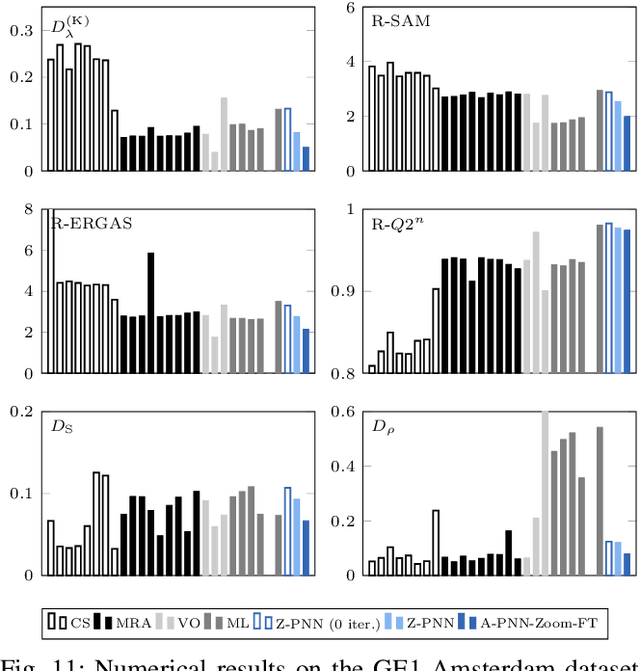
Hyperspectral pansharpening is receiving a growing interest since the last few years as testified by a large number of research papers and challenges. It consists in a pixel-level fusion between a lower-resolution hyperspectral datacube and a higher-resolution single-band image, the panchromatic image, with the goal of providing a hyperspectral datacube at panchromatic resolution. Thanks to their powerful representational capabilities, deep learning models have succeeded to provide unprecedented results on many general purpose image processing tasks. However, when moving to domain specific problems, as in this case, the advantages with respect to traditional model-based approaches are much lesser clear-cut due to several contextual reasons. Scarcity of training data, lack of ground-truth, data shape variability, are some such factors that limit the generalization capacity of the state-of-the-art deep learning networks for hyperspectral pansharpening. To cope with these limitations, in this work we propose a new deep learning method which inherits a simple single-band unsupervised pansharpening model nested in a sequential band-wise adaptive scheme, where each band is pansharpened refining the model tuned on the preceding one. By doing so, a simple model is propagated along the wavelength dimension, adaptively and flexibly, with no need to have a fixed number of spectral bands, and, with no need to dispose of large, expensive and labeled training datasets. The proposed method achieves very good results on our datasets, outperforming both traditional and deep learning reference methods. The implementation of the proposed method can be found on https://github.com/giu-guarino/R-PNN
A full-resolution training framework for Sentinel-2 image fusion
Jul 27, 2023

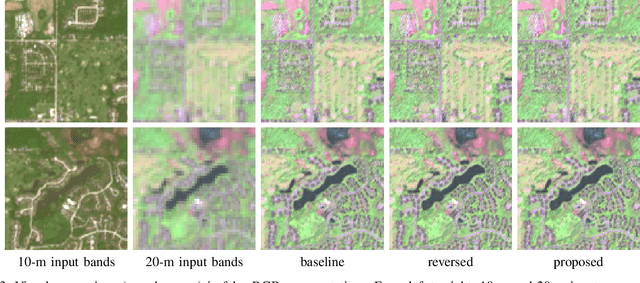
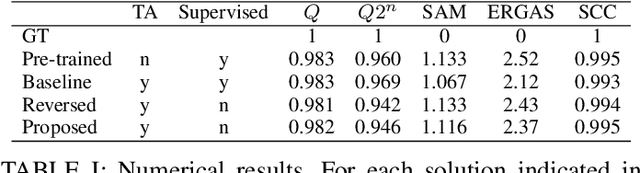
This work presents a new unsupervised framework for training deep learning models for super-resolution of Sentinel-2 images by fusion of its 10-m and 20-m bands. The proposed scheme avoids the resolution downgrade process needed to generate training data in the supervised case. On the other hand, a proper loss that accounts for cycle-consistency between the network prediction and the input components to be fused is proposed. Despite its unsupervised nature, in our preliminary experiments the proposed scheme has shown promising results in comparison to the supervised approach. Besides, by construction of the proposed loss, the resulting trained network can be ascribed to the class of multi-resolution analysis methods.
Unsupervised Deep Learning-based Pansharpening with Jointly-Enhanced Spectral and Spatial Fidelity
Jul 26, 2023In latest years, deep learning has gained a leading role in the pansharpening of multiresolution images. Given the lack of ground truth data, most deep learning-based methods carry out supervised training in a reduced-resolution domain. However, models trained on downsized images tend to perform poorly on high-resolution target images. For this reason, several research groups are now turning to unsupervised training in the full-resolution domain, through the definition of appropriate loss functions and training paradigms. In this context, we have recently proposed a full-resolution training framework which can be applied to many existing architectures. Here, we propose a new deep learning-based pansharpening model that fully exploits the potential of this approach and provides cutting-edge performance. Besides architectural improvements with respect to previous work, such as the use of residual attention modules, the proposed model features a novel loss function that jointly promotes the spectral and spatial quality of the pansharpened data. In addition, thanks to a new fine-tuning strategy, it improves inference-time adaptation to target images. Experiments on a large variety of test images, performed in challenging scenarios, demonstrate that the proposed method compares favorably with the state of the art both in terms of numerical results and visual output. Code is available online at https://github.com/matciotola/Lambda-PNN.
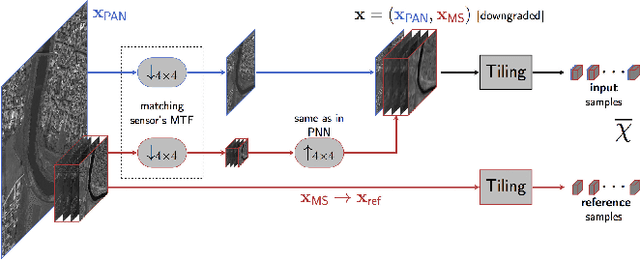
Pansharpening by convolutional neural networks in the full resolution framework
Nov 16, 2021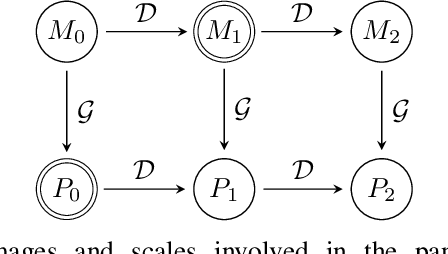

In recent years, there has been a growing interest on deep learning-based pansharpening. Research has mainly focused on architectures. However, lacking a ground truth, model training is also a major issue. A popular approach is to train networks in a reduced resolution domain, using the original data as ground truths. The trained networks are then used on full resolution data, relying on an implicit scale invariance hypothesis. Results are generally good at reduced resolution, but more questionable at full resolution. Here, we propose a full-resolution training framework for deep learning-based pansharpening. Training takes place in the high resolution domain, relying only on the original data, with no loss of information. To ensure spectral and spatial fidelity, suitable losses are defined, which force the pansharpened output to be consistent with the available panchromatic and multispectral input. Experiments carried out on WorldView-3, WorldView-2, and GeoEye-1 images show that methods trained with the proposed framework guarantee an excellent performance in terms of both full-resolution numerical indexes and visual quality. The framework is fully general, and can be used to train and fine-tune any deep learning-based pansharpening network.
Full-resolution quality assessment for pansharpening
Aug 13, 2021
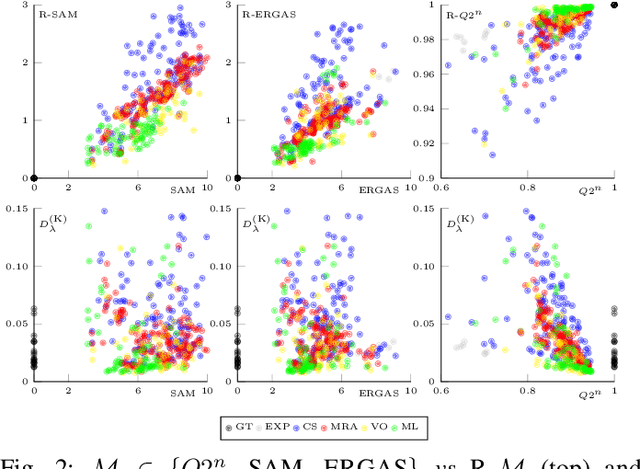
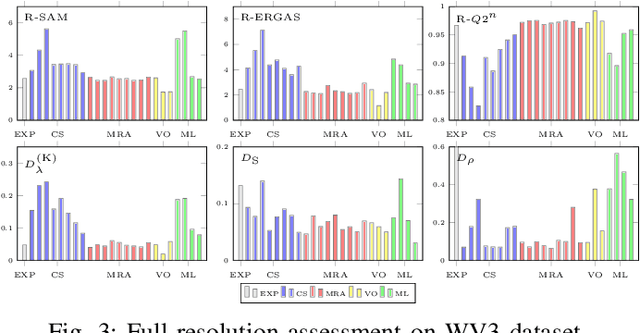

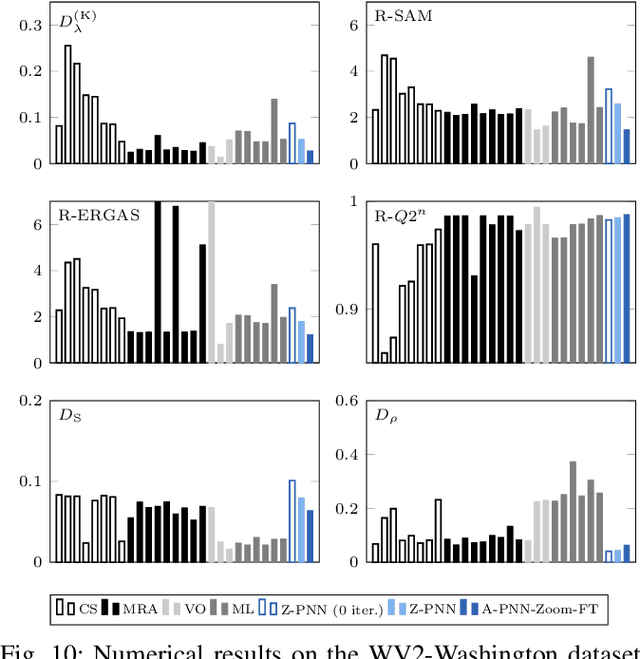
A reliable quality assessment procedure for pansharpening methods is of critical importance for the development of the related solutions. Unfortunately, the lack of ground-truths to be used as guidance for an objective evaluation has pushed the community to resort to either reference-based reduced-resolution indexes or to no-reference subjective quality indexes that can be applied on full-resolution datasets. In particular, the reference-based approach leverages on Wald's protocol, a resolution degradation process that allows one to synthesize data with related ground truth. Both solutions, however, present critical shortcomings that we aim to mitigate in this work by means of an alternative no-reference full-resolution framework. On one side we introduce a protocol, namely the reprojection protocol, which allows to handle the spectral fidelity problem. On the other side, a new index of the spatial consistency between the pansharpened image and the panchromatic band at full resolution is proposed. The experimental results show the effectiveness of the proposed approach which is confirmed also by visual inspection.
Deep learning methods for SAR image despeckling: trends and perspectives
Dec 10, 2020
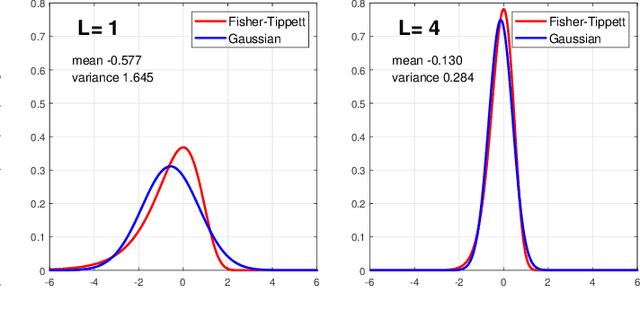


Synthetic aperture radar (SAR) images are affected by a spatially-correlated and signal-dependent noise called speckle, which is very severe and may hinder image exploitation. Despeckling is an important task that aims at removing such noise, so as to improve the accuracy of all downstream image processing tasks. The first despeckling methods date back to the 1970's, and several model-based algorithms have been developed in the subsequent years. The field has received growing attention, sparkled by the availability of powerful deep learning models that have yielded excellent performance for inverse problems in image processing. This paper surveys the literature on deep learning methods applied to SAR despeckling, covering both the supervised and the more recent self-supervised approaches. We provide a critical analysis of existing methods with the objective to recognize the most promising research lines, to identify the factors that have limited the success of deep models, and to propose ways forward in an attempt to fully exploit the potential of deep learning for SAR despeckling.
Guided patch-wise nonlocal SAR despeckling
Nov 28, 2018



We propose a new method for SAR image despeckling which leverages information drawn from co-registered optical imagery. Filtering is performed by plain patch-wise nonlocal means, operating exclusively on SAR data. However, the filtering weights are computed by taking into account also the optical guide, which is much cleaner than the SAR data, and hence more discriminative. To avoid injecting optical-domain information into the filtered image, a SAR-domain statistical test is preliminarily performed to reject right away any risky predictor. Experiments on two SAR-optical datasets prove the proposed method to suppress very effectively the speckle, preserving structural details, and without introducing visible filtering artifacts. Overall, the proposed method compares favourably with all state-of-the-art despeckling filters, and also with our own previous optical-guided filter.
Target-adaptive CNN-based pansharpening
Feb 23, 2018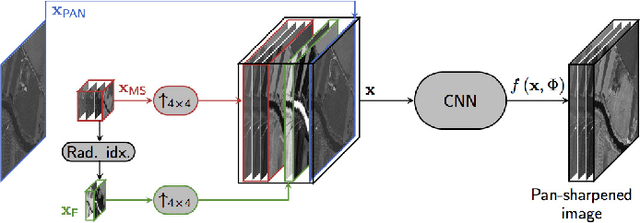


We recently proposed a convolutional neural network (CNN) for remote sensing image pansharpening obtaining a significant performance gain over the state of the art. In this paper, we explore a number of architectural and training variations to this baseline, achieving further performance gains with a lightweight network which trains very fast. Leveraging on this latter property, we propose a target-adaptive usage modality which ensures a very good performance also in the presence of a mismatch w.r.t. the training set, and even across different sensors. The proposed method, published online as an off-the-shelf software tool, allows users to perform fast and high-quality CNN-based pansharpening of their own target images on general-purpose hardware.