 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying the Lottery With Concave Regularizers for Sparse Trainable Neural Networks
Jan 19, 2025The design of sparse neural networks, i.e., of networks with a reduced number of parameters, has been attracting increasing research attention in the last few years. The use of sparse models may significantly reduce the computational and storage footprint in the inference phase. In this context, the lottery ticket hypothesis (LTH) constitutes a breakthrough result, that addresses not only the performance of the inference phase, but also of the training phase. It states that it is possible to extract effective sparse subnetworks, called winning tickets, that can be trained in isolation. The development of effective methods to play the lottery, i.e., to find winning tickets, is still an open problem. In this article, we propose a novel class of methods to play the lottery. The key point is the use of concave regularization to promote the sparsity of a relaxed binary mask, which represents the network topology. We theoretically analyze the effectiveness of the proposed method in the convex framework. Then, we propose extended numerical tests on various datasets and architectures, that show that the proposed method can improve the performance of state-of-the-art algorithms.
Deep 3D World Models for Multi-Image Super-Resolution Beyond Optical Flow
Jan 30, 2024



Multi-image super-resolution (MISR) allows to increase the spatial resolution of a low-resolution (LR) acquisition by combining multiple images carrying complementary information in the form of sub-pixel offsets in the scene sampling, and can be significantly more effective than its single-image counterpart. Its main difficulty lies in accurately registering and fusing the multi-image information. Currently studied settings, such as burst photography, typically involve assumptions of small geometric disparity between the LR images and rely on optical flow for image registration. We study a MISR method that can increase the resolution of sets of images acquired with arbitrary, and potentially wildly different, camera positions and orientations, generalizing the currently studied MISR settings. Our proposed model, called EpiMISR, moves away from optical flow and explicitly uses the epipolar geometry of the acquisition process, together with transformer-based processing of radiance feature fields to substantially improve over state-of-the-art MISR methods in presence of large disparities in the LR images.
Self-supervised learning for joint SAR and multispectral land cover classification
Aug 20, 2021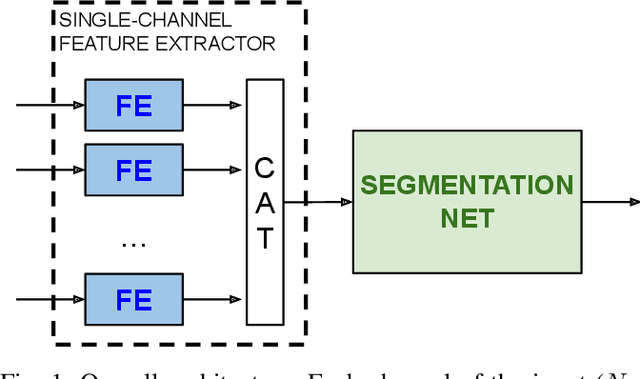
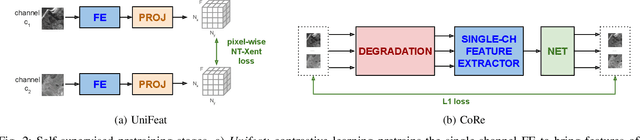
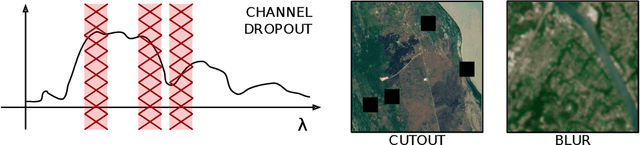
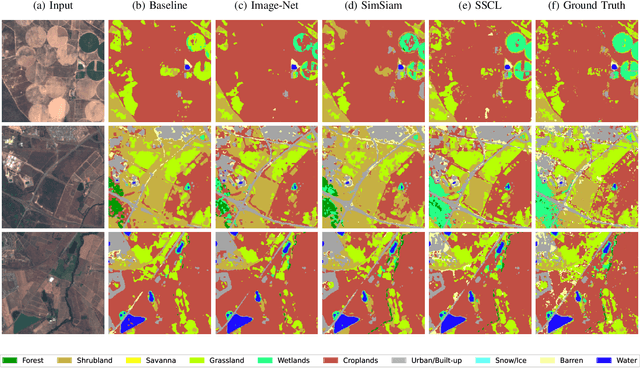
Self-supervised learning techniques are gaining popularity due to their capability of building models that are effective, even when scarce amounts of labeled data are available. In this paper, we present a framework and specific tasks for self-supervised training of multichannel models, such as the fusion of multispectral and synthetic aperture radar images. We show that the proposed self-supervised approach is highly effective at learning features that correlate with the labels for land cover classification. This is enabled by an explicit design of pretraining tasks which promotes bridging the gaps between sensing modalities and exploiting the spectral characteristics of the input. When limited labels are available, using the proposed self-supervised pretraining and supervised finetuning for land cover classification with SAR and multispectral data outperforms conventional approaches such as purely supervised learning, initialization from training on Imagenet and recent self-supervised approaches for computer vision tasks.
COVID-19 case data for Italy stratified by age class
Apr 13, 2021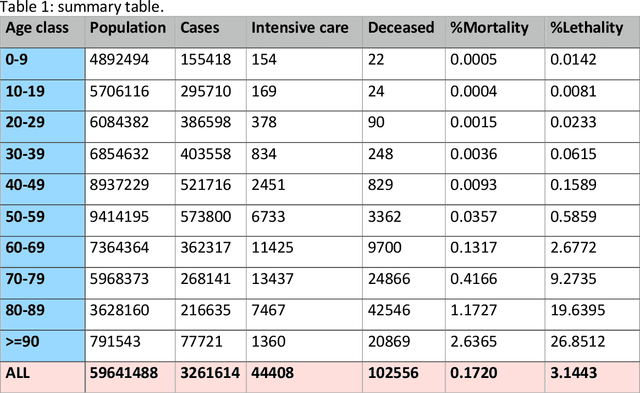
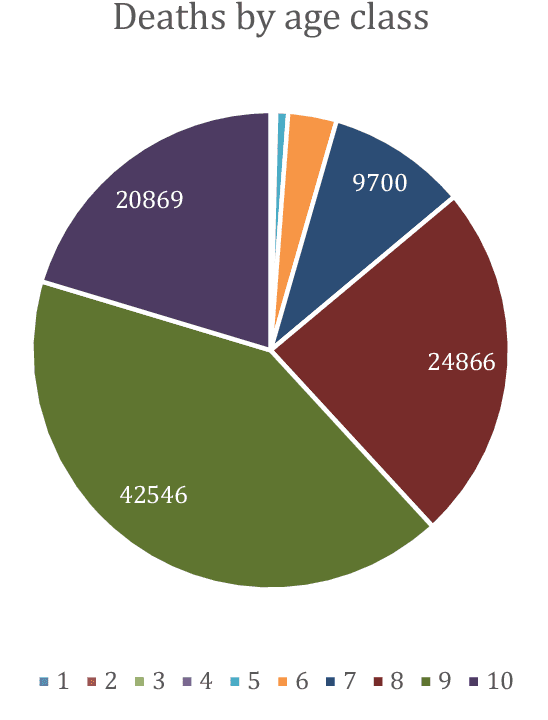
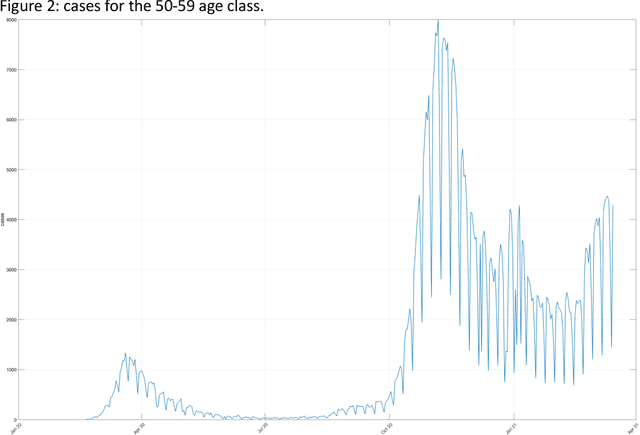
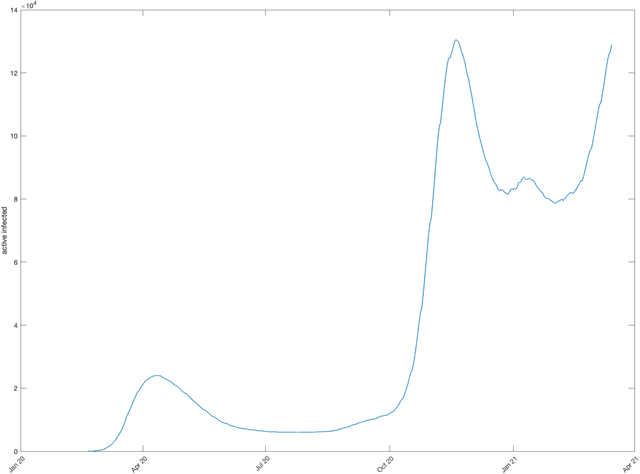
The dataset described in this paper contains daily data about COVID-19 cases that occurred in Italy over the period from Jan. 28, 2020 to March 20, 2021, divided into ten age classes of the population, the first class being 0-9 years, the tenth class being 90 years and over. The dataset contains eight columns, namely: date (day), age class, number of new cases, number of newly hospitalized patients, number of patients entering intensive care, number of deceased patients, number of recovered patients, number of active infected patients. This data has been officially released for research purposes by the Italian authority for COVID-19 epidemiologic surveillance (Istituto Superiore di Sanit\`a - ISS), upon formal request by the authors, in accordance with the Ordonnance of the Chief of the Civil Protection Department n. 691 dated Aug. 4 2020. A separate file contains the numerosity of the population in each age class, according to the National Institute of Statistics (ISTAT) data of the resident population of Italy as of Jan. 2020. This data has potential use, for instance, in epidemiologic studies of the effects of the COVID-19 contagion in Italy, in mortality analysis by age class, and in the development and testing of dynamical models of the contagion.
Denoise and Contrast for Category Agnostic Shape Completion
Mar 30, 2021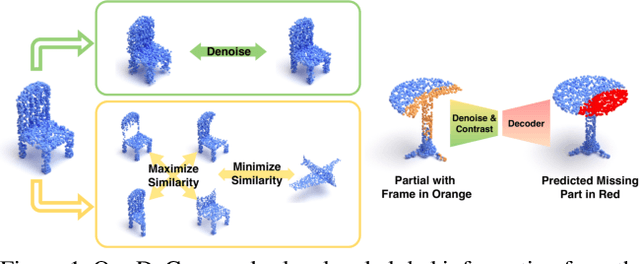
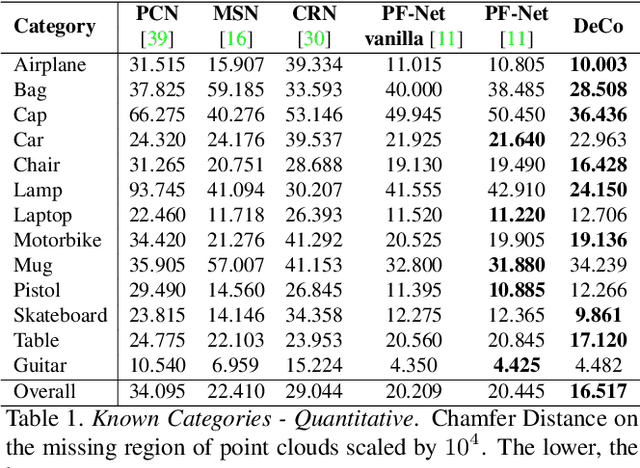
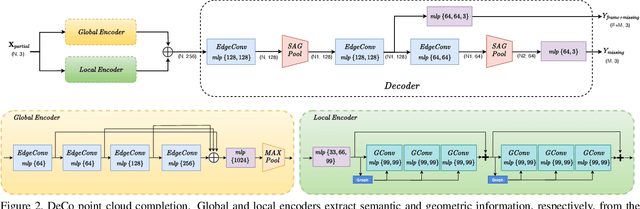
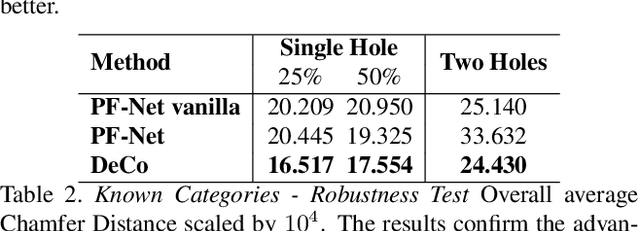
In this paper, we present a deep learning model that exploits the power of self-supervision to perform 3D point cloud completion, estimating the missing part and a context region around it. Local and global information are encoded in a combined embedding. A denoising pretext task provides the network with the needed local cues, decoupled from the high-level semantics and naturally shared over multiple classes. On the other hand, contrastive learning maximizes the agreement between variants of the same shape with different missing portions, thus producing a representation which captures the global appearance of the shape. The combined embedding inherits category-agnostic properties from the chosen pretext tasks. Differently from existing approaches, this allows to better generalize the completion properties to new categories unseen at training time. Moreover, while decoding the obtained joint representation, we better blend the reconstructed missing part with the partial shape by paying attention to its known surrounding region and reconstructing this frame as auxiliary objective. Our extensive experiments and detailed ablation on the ShapeNet dataset show the effectiveness of each part of the method with new state of the art results. Our quantitative and qualitative analysis confirms how our approach is able to work on novel categories without relying neither on classification and shape symmetry priors, nor on adversarial training procedures.
RAN-GNNs: breaking the capacity limits of graph neural networks
Mar 29, 2021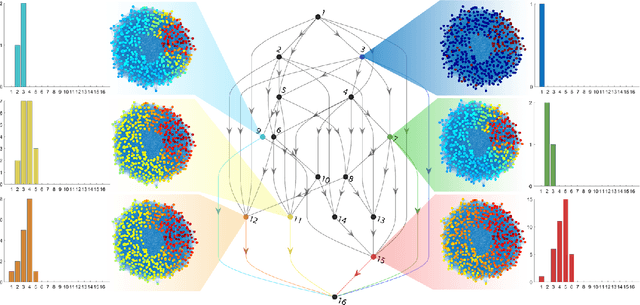
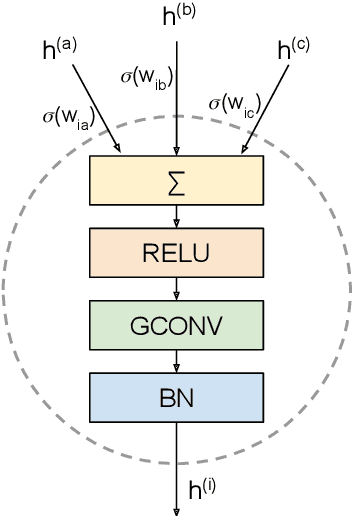
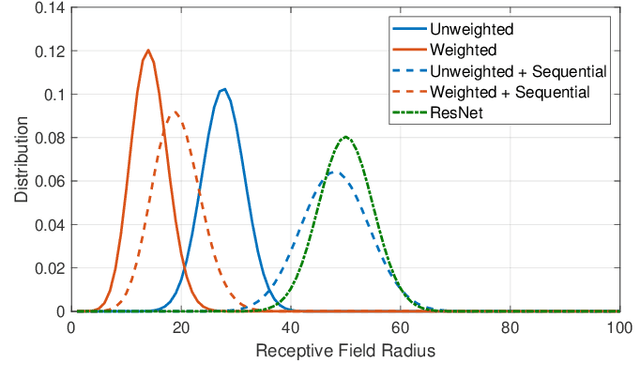
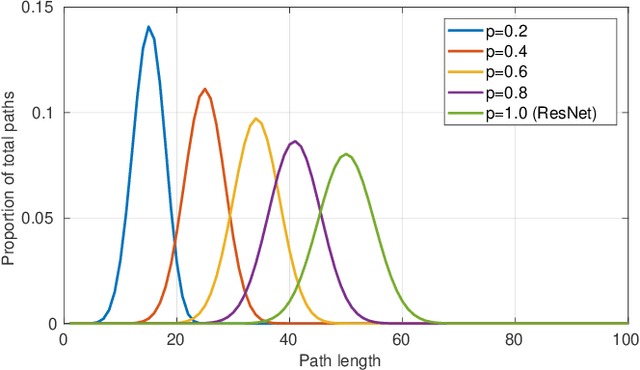
Graph neural networks have become a staple in problems addressing learning and analysis of data defined over graphs. However, several results suggest an inherent difficulty in extracting better performance by increasing the number of layers. Recent works attribute this to a phenomenon peculiar to the extraction of node features in graph-based tasks, i.e., the need to consider multiple neighborhood sizes at the same time and adaptively tune them. In this paper, we investigate the recently proposed randomly wired architectures in the context of graph neural networks. Instead of building deeper networks by stacking many layers, we prove that employing a randomly-wired architecture can be a more effective way to increase the capacity of the network and obtain richer representations. We show that such architectures behave like an ensemble of paths, which are able to merge contributions from receptive fields of varied size. Moreover, these receptive fields can also be modulated to be wider or narrower through the trainable weights over the paths. We also provide extensive experimental evidence of the superior performance of randomly wired architectures over multiple tasks and four graph convolution definitions, using recent benchmarking frameworks that addresses the reliability of previous testing methodologies.
Deep learning methods for SAR image despeckling: trends and perspectives
Dec 10, 2020
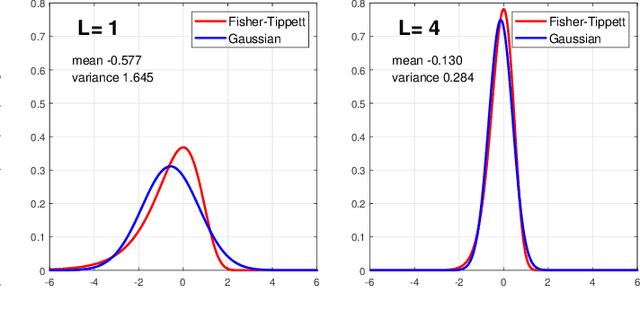


Synthetic aperture radar (SAR) images are affected by a spatially-correlated and signal-dependent noise called speckle, which is very severe and may hinder image exploitation. Despeckling is an important task that aims at removing such noise, so as to improve the accuracy of all downstream image processing tasks. The first despeckling methods date back to the 1970's, and several model-based algorithms have been developed in the subsequent years. The field has received growing attention, sparkled by the availability of powerful deep learning models that have yielded excellent performance for inverse problems in image processing. This paper surveys the literature on deep learning methods applied to SAR despeckling, covering both the supervised and the more recent self-supervised approaches. We provide a critical analysis of existing methods with the objective to recognize the most promising research lines, to identify the factors that have limited the success of deep models, and to propose ways forward in an attempt to fully exploit the potential of deep learning for SAR despeckling.
Learning Graph-Convolutional Representations for Point Cloud Denoising
Jul 06, 2020
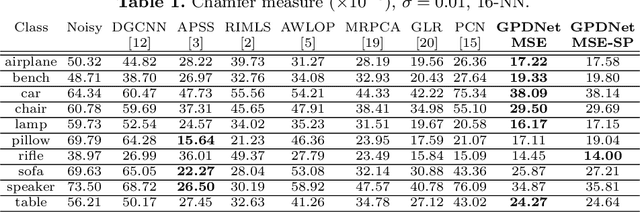
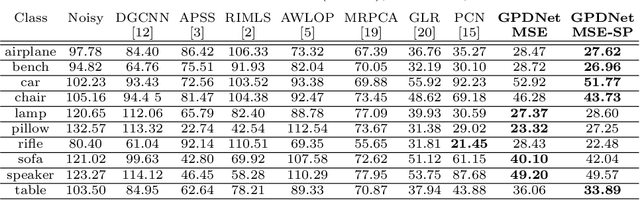

Point clouds are an increasingly relevant data type but they are often corrupted by noise. We propose a deep neural network based on graph-convolutional layers that can elegantly deal with the permutation-invariance problem encountered by learning-based point cloud processing methods. The network is fully-convolutional and can build complex hierarchies of features by dynamically constructing neighborhood graphs from similarity among the high-dimensional feature representations of the points. When coupled with a loss promoting proximity to the ideal surface, the proposed approach significantly outperforms state-of-the-art methods on a variety of metrics. In particular, it is able to improve in terms of Chamfer measure and of quality of the surface normals that can be estimated from the denoised data. We also show that it is especially robust both at high noise levels and in presence of structured noise such as the one encountered in real LiDAR scans.
Speckle2Void: Deep Self-Supervised SAR Despeckling with Blind-Spot Convolutional Neural Networks
Jul 04, 2020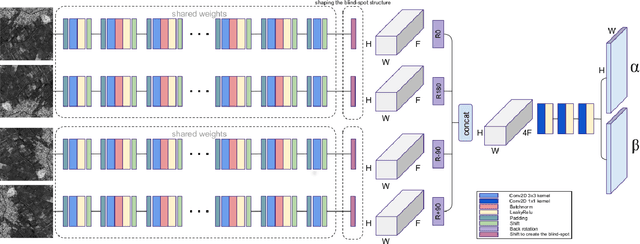



Information extraction from synthetic aperture radar (SAR) images is heavily impaired by speckle noise, hence despeckling is a crucial preliminary step in scene analysis algorithms. The recent success of deep learning envisions a new generation of despeckling techniques that could outperform classical model-based methods. However, current deep learning approaches to despeckling require supervision for training, whereas clean SAR images are impossible to obtain. In the literature, this issue is tackled by resorting to either synthetically speckled optical images, which exhibit different properties with respect to true SAR images, or multi-temporal SAR images, which are difficult to acquire or fuse accurately. In this paper, inspired by recent works on blind-spot denoising networks, we propose a self-supervised Bayesian despeckling method. The proposed method is trained employing only noisy SAR images and can therefore learn features of real SAR images rather than synthetic data. Experiments show that the performance of the proposed approach is very close to the supervised training approach on synthetic data and superior on real data in both quantitative and visual assessments.
Towards Deep Unsupervised SAR Despeckling with Blind-Spot Convolutional Neural Networks
Jan 15, 2020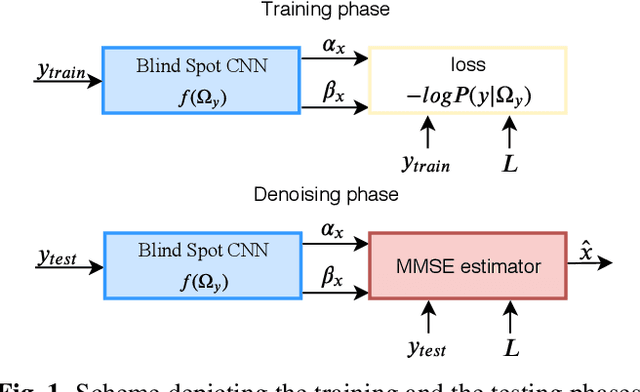
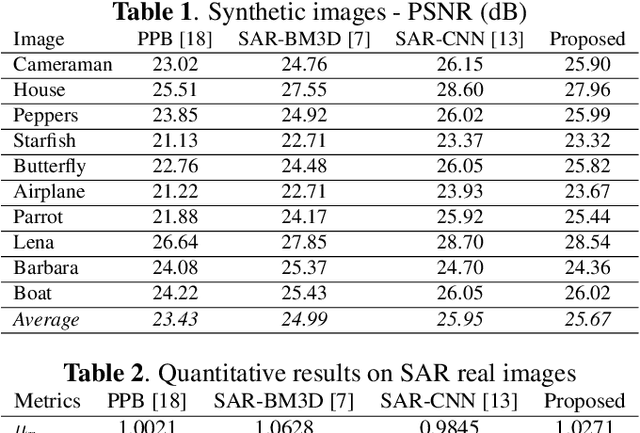
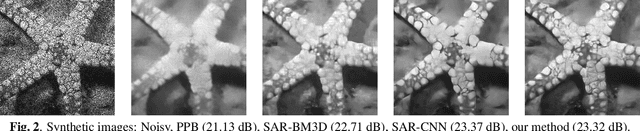

SAR despeckling is a problem of paramount importance in remote sensing, since it represents the first step of many scene analysis algorithms. Recently, deep learning techniques have outperformed classical model-based despeckling algorithms. However, such methods require clean ground truth images for training, thus resorting to synthetically speckled optical images since clean SAR images cannot be acquired. In this paper, inspired by recent works on blind-spot denoising networks, we propose a self-supervised Bayesian despeckling method. The proposed method is trained employing only noisy images and can therefore learn features of real SAR images rather than synthetic data. We show that the performance of the proposed network is very close to the supervised training approach on synthetic data and competitive on real data.