 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable neural pushbroom architectures for real-time denoising of hyperspectral images onboard satellites
Jan 08, 2026The next generation of Earth observation satellites will seek to deploy intelligent models directly onboard the payload in order to minimize the latency incurred by the transmission and processing chain of the ground segment, for time-critical applications. Designing neural architectures for onboard execution, particularly for satellite-based hyperspectral imagers, poses novel challenges due to the unique constraints of this environment and imaging system that are largely unexplored by the traditional computer vision literature. In this paper, we show that this setting requires addressing three competing objectives, namely high-quality inference with low complexity, dynamic power scalability and fault tolerance. We focus on the problem of hyperspectral image denoising, which is a critical task to enable effective downstream inference, and highlights the constraints of the onboard processing scenario. We propose a neural network design that addresses the three aforementioned objectives with several novel contributions. In particular, we propose a mixture of denoisers that can be resilient to radiation-induced faults as well as allowing for time-varying power scaling. Moreover, each denoiser employs an innovative architecture where an image is processed line-by-line in a causal way, with a memory of past lines, in order to match the acquisition process of pushbroom hyperspectral sensors and greatly limit memory requirements. We show that the proposed architecture can run in real-time, i.e., process one line in the time it takes to acquire the next one, on low-power hardware and provide competitive denoising quality with respect to significantly more complex state-of-the-art models. We also show that the power scalability and fault tolerance objectives provide a design space with multiple tradeoffs between those properties and denoising quality.
A low-complexity method for efficient depth-guided image deblurring
Jan 07, 2026Image deblurring is a challenging problem in imaging due to its highly ill-posed nature. Deep learning models have shown great success in tackling this problem but the quest for the best image quality has brought their computational complexity up, making them impractical on anything but powerful servers. Meanwhile, recent works have shown that mobile Lidars can provide complementary information in the form of depth maps that enhance deblurring quality. In this paper, we introduce a novel low-complexity neural network for depth-guided image deblurring. We show that the use of the wavelet transform to separate structural details and reduce spatial redundancy as well as efficient feature conditioning on the depth information are essential ingredients in developing a low-complexity model. Experimental results show competitive image quality against recent state-of-the-art models while reducing complexity by up to two orders of magnitude.
A novel method and dataset for depth-guided image deblurring from smartphone Lidar
Sep 11, 2025Modern smartphones are equipped with Lidar sensors providing depth-sensing capabilities. Recent works have shown that this complementary sensor allows to improve various tasks in image processing, including deblurring. However, there is a current lack of datasets with realistic blurred images and paired mobile Lidar depth maps to further study the topic. At the same time, there is also a lack of blind zero-shot methods that can deblur a real image using the depth guidance without requiring extensive training sets of paired data. In this paper, we propose an image deblurring method based on denoising diffusion models that can leverage the Lidar depth guidance and does not require training data with paired Lidar depth maps. We also present the first dataset with real blurred images with corresponding Lidar depth maps and sharp ground truth images, acquired with an Apple iPhone 15 Pro, for the purpose of studying Lidar-guided deblurring. Experimental results on this novel dataset show that Lidar guidance is effective and the proposed method outperforms state-of-the-art deblurring methods in terms of perceptual quality.
Onboard Hyperspectral Super-Resolution with Deep Pushbroom Neural Network
Jul 28, 2025Hyperspectral imagers on satellites obtain the fine spectral signatures essential for distinguishing one material from another at the expense of limited spatial resolution. Enhancing the latter is thus a desirable preprocessing step in order to further improve the detection capabilities offered by hyperspectral images on downstream tasks. At the same time, there is a growing interest towards deploying inference methods directly onboard of satellites, which calls for lightweight image super-resolution methods that can be run on the payload in real time. In this paper, we present a novel neural network design, called Deep Pushbroom Super-Resolution (DPSR) that matches the pushbroom acquisition of hyperspectral sensors by processing an image line by line in the along-track direction with a causal memory mechanism to exploit previously acquired lines. This design greatly limits memory requirements and computational complexity, achieving onboard real-time performance, i.e., the ability to super-resolve a line in the time it takes to acquire the next one, on low-power hardware. Experiments show that the quality of the super-resolved images is competitive or even outperforms state-of-the-art methods that are significantly more complex.
Deep Lidar-guided Image Deblurring
Dec 10, 2024



The rise of portable Lidar instruments, including their adoption in smartphones, opens the door to novel computational imaging techniques. Being an active sensing instrument, Lidar can provide complementary data to passive optical sensors, particularly in situations like low-light imaging where motion blur can affect photos. In this paper, we study if the depth information provided by mobile Lidar sensors is useful for the task of image deblurring and how to integrate it with a general approach that transforms any state-of-the-art neural deblurring model into a depth-aware one. To achieve this, we developed a universal adapter structure that efficiently preprocesses the depth information to modulate image features with depth features. Additionally, we applied a continual learning strategy to pretrained encoder-decoder models, enabling them to incorporate depth information as an additional input with minimal extra data requirements. We demonstrate that utilizing true depth information can significantly boost the effectiveness of deblurring algorithms, as validated on a dataset with real-world depth data captured by a smartphone Lidar.
DreamCache: Finetuning-Free Lightweight Personalized Image Generation via Feature Caching
Nov 26, 2024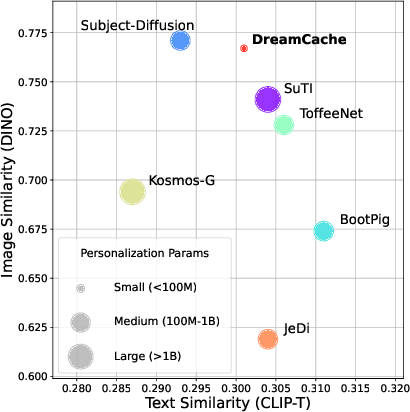
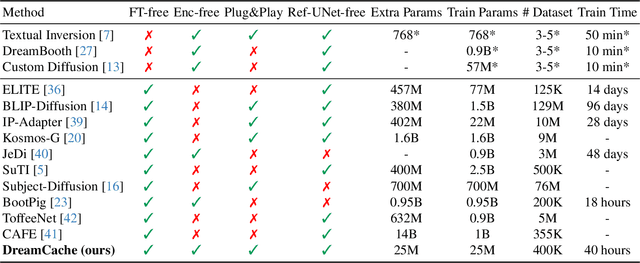

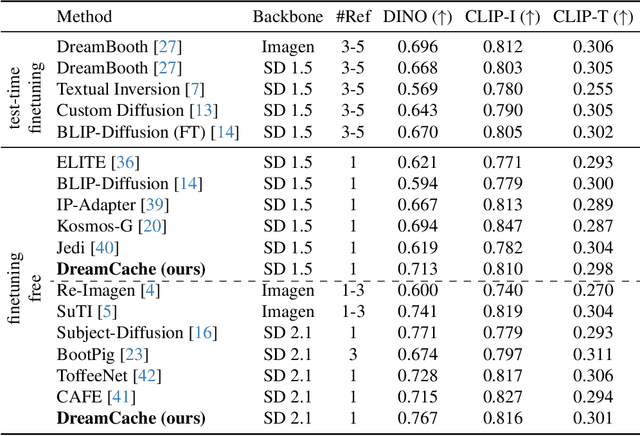
Personalized image generation requires text-to-image generative models that capture the core features of a reference subject to allow for controlled generation across different contexts. Existing methods face challenges due to complex training requirements, high inference costs, limited flexibility, or a combination of these issues. In this paper, we introduce DreamCache, a scalable approach for efficient and high-quality personalized image generation. By caching a small number of reference image features from a subset of layers and a single timestep of the pretrained diffusion denoiser, DreamCache enables dynamic modulation of the generated image features through lightweight, trained conditioning adapters. DreamCache achieves state-of-the-art image and text alignment, utilizing an order of magnitude fewer extra parameters, and is both more computationally effective and versatile than existing models.
Efficient onboard multi-task AI architecture based on self-supervised learning
Aug 19, 2024



There is growing interest towards the use of AI directly onboard satellites for quick analysis and rapid response to critical events such as natural disasters. This paper presents a blueprint to the mission designer for the development of a modular and efficient deep learning payload to address multiple onboard inference tasks. In particular, we design a self-supervised lightweight backbone that provides features to efficient task-specific heads. The latter can be developed independently and with reduced data labeling requirements thanks to the frozen backbone. Experiments on three sample tasks of cloud segmentation, flood detection, and marine debris classification on a 7W embedded system show competitive results with inference quality close to high-complexity state-of-the-art models and high throughput in excess of 8 Mpx/s.
MotionCraft: Physics-based Zero-Shot Video Generation
May 22, 2024Generating videos with realistic and physically plausible motion is one of the main recent challenges in computer vision. While diffusion models are achieving compelling results in image generation, video diffusion models are limited by heavy training and huge models, resulting in videos that are still biased to the training dataset. In this work we propose MotionCraft, a new zero-shot video generator to craft physics-based and realistic videos. MotionCraft is able to warp the noise latent space of an image diffusion model, such as Stable Diffusion, by applying an optical flow derived from a physics simulation. We show that warping the noise latent space results in coherent application of the desired motion while allowing the model to generate missing elements consistent with the scene evolution, which would otherwise result in artefacts or missing content if the flow was applied in the pixel space. We compare our method with the state-of-the-art Text2Video-Zero reporting qualitative and quantitative improvements, demonstrating the effectiveness of our approach to generate videos with finely-prescribed complex motion dynamics. Project page: https://mezzelfo.github.io/MotionCraft/
Modeling uncertainty for Gaussian Splatting
Mar 27, 2024



We present Stochastic Gaussian Splatting (SGS): the first framework for uncertainty estimation using Gaussian Splatting (GS). GS recently advanced the novel-view synthesis field by achieving impressive reconstruction quality at a fraction of the computational cost of Neural Radiance Fields (NeRF). However, contrary to the latter, it still lacks the ability to provide information about the confidence associated with their outputs. To address this limitation, in this paper, we introduce a Variational Inference-based approach that seamlessly integrates uncertainty prediction into the common rendering pipeline of GS. Additionally, we introduce the Area Under Sparsification Error (AUSE) as a new term in the loss function, enabling optimization of uncertainty estimation alongside image reconstruction. Experimental results on the LLFF dataset demonstrate that our method outperforms existing approaches in terms of both image rendering quality and uncertainty estimation accuracy. Overall, our framework equips practitioners with valuable insights into the reliability of synthesized views, facilitating safer decision-making in real-world applications.
Onboard deep lossless and near-lossless predictive coding of hyperspectral images with line-based attention
Mar 26, 2024Deep learning methods have traditionally been difficult to apply to compression of hyperspectral images onboard of spacecrafts, due to the large computational complexity needed to achieve adequate representational power, as well as the lack of suitable datasets for training and testing. In this paper, we depart from the traditional autoencoder approach and we design a predictive neural network, called LineRWKV, that works recursively line-by-line to limit memory consumption. In order to achieve that, we adopt a novel hybrid attentive-recursive operation that combines the representational advantages of Transformers with the linear complexity and recursive implementation of recurrent neural networks. The compression algorithm performs prediction of each pixel using LineRWKV, followed by entropy coding of the residual. Experiments on the HySpecNet-11k dataset and PRISMA images show that LineRWKV is the first deep-learning method to outperform CCSDS-123.0-B-2 at lossless and near-lossless compression. Promising throughput results are also evaluated on a 7W embedded system.