 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable neural pushbroom architectures for real-time denoising of hyperspectral images onboard satellites
Jan 08, 2026The next generation of Earth observation satellites will seek to deploy intelligent models directly onboard the payload in order to minimize the latency incurred by the transmission and processing chain of the ground segment, for time-critical applications. Designing neural architectures for onboard execution, particularly for satellite-based hyperspectral imagers, poses novel challenges due to the unique constraints of this environment and imaging system that are largely unexplored by the traditional computer vision literature. In this paper, we show that this setting requires addressing three competing objectives, namely high-quality inference with low complexity, dynamic power scalability and fault tolerance. We focus on the problem of hyperspectral image denoising, which is a critical task to enable effective downstream inference, and highlights the constraints of the onboard processing scenario. We propose a neural network design that addresses the three aforementioned objectives with several novel contributions. In particular, we propose a mixture of denoisers that can be resilient to radiation-induced faults as well as allowing for time-varying power scaling. Moreover, each denoiser employs an innovative architecture where an image is processed line-by-line in a causal way, with a memory of past lines, in order to match the acquisition process of pushbroom hyperspectral sensors and greatly limit memory requirements. We show that the proposed architecture can run in real-time, i.e., process one line in the time it takes to acquire the next one, on low-power hardware and provide competitive denoising quality with respect to significantly more complex state-of-the-art models. We also show that the power scalability and fault tolerance objectives provide a design space with multiple tradeoffs between those properties and denoising quality.
A low-complexity method for efficient depth-guided image deblurring
Jan 07, 2026Image deblurring is a challenging problem in imaging due to its highly ill-posed nature. Deep learning models have shown great success in tackling this problem but the quest for the best image quality has brought their computational complexity up, making them impractical on anything but powerful servers. Meanwhile, recent works have shown that mobile Lidars can provide complementary information in the form of depth maps that enhance deblurring quality. In this paper, we introduce a novel low-complexity neural network for depth-guided image deblurring. We show that the use of the wavelet transform to separate structural details and reduce spatial redundancy as well as efficient feature conditioning on the depth information are essential ingredients in developing a low-complexity model. Experimental results show competitive image quality against recent state-of-the-art models while reducing complexity by up to two orders of magnitude.
Deep Lidar-guided Image Deblurring
Dec 10, 2024



The rise of portable Lidar instruments, including their adoption in smartphones, opens the door to novel computational imaging techniques. Being an active sensing instrument, Lidar can provide complementary data to passive optical sensors, particularly in situations like low-light imaging where motion blur can affect photos. In this paper, we study if the depth information provided by mobile Lidar sensors is useful for the task of image deblurring and how to integrate it with a general approach that transforms any state-of-the-art neural deblurring model into a depth-aware one. To achieve this, we developed a universal adapter structure that efficiently preprocesses the depth information to modulate image features with depth features. Additionally, we applied a continual learning strategy to pretrained encoder-decoder models, enabling them to incorporate depth information as an additional input with minimal extra data requirements. We demonstrate that utilizing true depth information can significantly boost the effectiveness of deblurring algorithms, as validated on a dataset with real-world depth data captured by a smartphone Lidar.
Onboard deep lossless and near-lossless predictive coding of hyperspectral images with line-based attention
Mar 26, 2024Deep learning methods have traditionally been difficult to apply to compression of hyperspectral images onboard of spacecrafts, due to the large computational complexity needed to achieve adequate representational power, as well as the lack of suitable datasets for training and testing. In this paper, we depart from the traditional autoencoder approach and we design a predictive neural network, called LineRWKV, that works recursively line-by-line to limit memory consumption. In order to achieve that, we adopt a novel hybrid attentive-recursive operation that combines the representational advantages of Transformers with the linear complexity and recursive implementation of recurrent neural networks. The compression algorithm performs prediction of each pixel using LineRWKV, followed by entropy coding of the residual. Experiments on the HySpecNet-11k dataset and PRISMA images show that LineRWKV is the first deep-learning method to outperform CCSDS-123.0-B-2 at lossless and near-lossless compression. Promising throughput results are also evaluated on a 7W embedded system.
Beyond cross-entropy: learning highly separable feature distributions for robust and accurate classification
Oct 29, 2020



Deep learning has shown outstanding performance in several applications including image classification. However, deep classifiers are known to be highly vulnerable to adversarial attacks, in that a minor perturbation of the input can easily lead to an error. Providing robustness to adversarial attacks is a very challenging task especially in problems involving a large number of classes, as it typically comes at the expense of an accuracy decrease. In this work, we propose the Gaussian class-conditional simplex (GCCS) loss: a novel approach for training deep robust multiclass classifiers that provides adversarial robustness while at the same time achieving or even surpassing the classification accuracy of state-of-the-art methods. Differently from other frameworks, the proposed method learns a mapping of the input classes onto target distributions in a latent space such that the classes are linearly separable. Instead of maximizing the likelihood of target labels for individual samples, our objective function pushes the network to produce feature distributions yielding high inter-class separation. The mean values of the distributions are centered on the vertices of a simplex such that each class is at the same distance from every other class. We show that the regularization of the latent space based on our approach yields excellent classification accuracy and inherently provides robustness to multiple adversarial attacks, both targeted and untargeted, outperforming state-of-the-art approaches over challenging datasets.
BioMetricNet: deep unconstrained face verification through learning of metrics regularized onto Gaussian distributions
Aug 13, 2020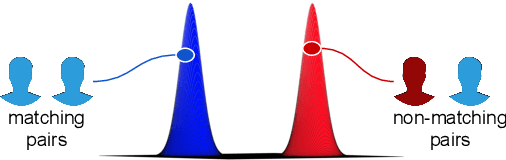
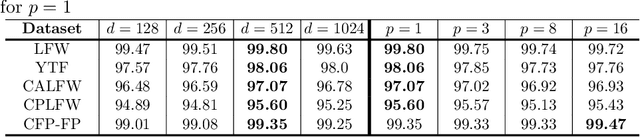
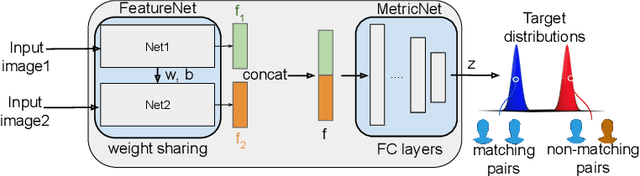
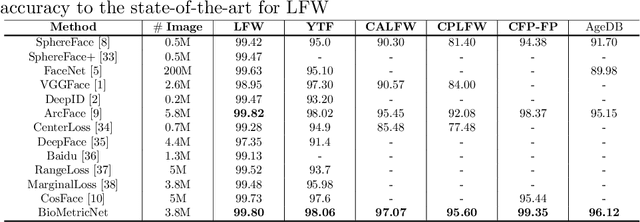
We present BioMetricNet: a novel framework for deep unconstrained face verification which learns a regularized metric to compare facial features. Differently from popular methods such as FaceNet, the proposed approach does not impose any specific metric on facial features; instead, it shapes the decision space by learning a latent representation in which matching and non-matching pairs are mapped onto clearly separated and well-behaved target distributions. In particular, the network jointly learns the best feature representation, and the best metric that follows the target distributions, to be used to discriminate face images. In this paper we present this general framework, first of its kind for facial verification, and tailor it to Gaussian distributions. This choice enables the use of a simple linear decision boundary that can be tuned to achieve the desired trade-off between false alarm and genuine acceptance rate, and leads to a loss function that can be written in closed form. Extensive analysis and experimentation on publicly available datasets such as Labeled Faces in the wild (LFW), Youtube faces (YTF), Celebrities in Frontal-Profile in the Wild (CFP), and challenging datasets like cross-age LFW (CALFW), cross-pose LFW (CPLFW), In-the-wild Age Dataset (AgeDB) show a significant performance improvement and confirms the effectiveness and superiority of BioMetricNet over existing state-of-the-art methods.
Learning mappings onto regularized latent spaces for biometric authentication
Nov 20, 2019


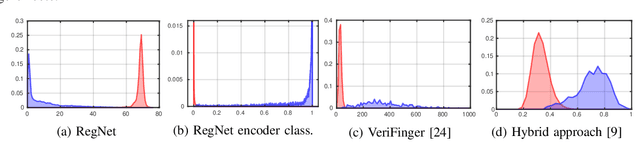
We propose a novel architecture for generic biometric authentication based on deep neural networks: RegNet. Differently from other methods, RegNet learns a mapping of the input biometric traits onto a target distribution in a well-behaved space in which users can be separated by means of simple and tunable boundaries. More specifically, authorized and unauthorized users are mapped onto two different and well behaved Gaussian distributions. The novel approach of learning the mapping instead of the boundaries further avoids the problem encountered in typical classifiers for which the learnt boundaries may be complex and difficult to analyze. RegNet achieves high performance in terms of security metrics such as Equal Error Rate (EER), False Acceptance Rate (FAR) and Genuine Acceptance Rate (GAR). The experiments we conducted on publicly available datasets of face and fingerprint confirm the effectiveness of the proposed system.
Analysis of SparseHash: an efficient embedding of set-similarity via sparse projections
Sep 02, 2019



Embeddings provide compact representations of signals in order to perform efficient inference in a wide variety of tasks. In particular, random projections are common tools to construct Euclidean distance-preserving embeddings, while hashing techniques are extensively used to embed set-similarity metrics, such as the Jaccard coefficient. In this letter, we theoretically prove that a class of random projections based on sparse matrices, called SparseHash, can preserve the Jaccard coefficient between the supports of sparse signals, which can be used to estimate set similarities. Moreover, besides the analysis, we provide an efficient implementation and we test the performance in several numerical experiments, both on synthetic and real datasets.