 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel method and dataset for depth-guided image deblurring from smartphone Lidar
Sep 11, 2025Modern smartphones are equipped with Lidar sensors providing depth-sensing capabilities. Recent works have shown that this complementary sensor allows to improve various tasks in image processing, including deblurring. However, there is a current lack of datasets with realistic blurred images and paired mobile Lidar depth maps to further study the topic. At the same time, there is also a lack of blind zero-shot methods that can deblur a real image using the depth guidance without requiring extensive training sets of paired data. In this paper, we propose an image deblurring method based on denoising diffusion models that can leverage the Lidar depth guidance and does not require training data with paired Lidar depth maps. We also present the first dataset with real blurred images with corresponding Lidar depth maps and sharp ground truth images, acquired with an Apple iPhone 15 Pro, for the purpose of studying Lidar-guided deblurring. Experimental results on this novel dataset show that Lidar guidance is effective and the proposed method outperforms state-of-the-art deblurring methods in terms of perceptual quality.
MotionCraft: Physics-based Zero-Shot Video Generation
May 22, 2024



Generating videos with realistic and physically plausible motion is one of the main recent challenges in computer vision. While diffusion models are achieving compelling results in image generation, video diffusion models are limited by heavy training and huge models, resulting in videos that are still biased to the training dataset. In this work we propose MotionCraft, a new zero-shot video generator to craft physics-based and realistic videos. MotionCraft is able to warp the noise latent space of an image diffusion model, such as Stable Diffusion, by applying an optical flow derived from a physics simulation. We show that warping the noise latent space results in coherent application of the desired motion while allowing the model to generate missing elements consistent with the scene evolution, which would otherwise result in artefacts or missing content if the flow was applied in the pixel space. We compare our method with the state-of-the-art Text2Video-Zero reporting qualitative and quantitative improvements, demonstrating the effectiveness of our approach to generate videos with finely-prescribed complex motion dynamics. Project page: https://mezzelfo.github.io/MotionCraft/
Dynamic Hyperbolic Attention Network for Fine Hand-object Reconstruction
Sep 06, 2023Reconstructing both objects and hands in 3D from a single RGB image is complex. Existing methods rely on manually defined hand-object constraints in Euclidean space, leading to suboptimal feature learning. Compared with Euclidean space, hyperbolic space better preserves the geometric properties of meshes thanks to its exponentially-growing space distance, which amplifies the differences between the features based on similarity. In this work, we propose the first precise hand-object reconstruction method in hyperbolic space, namely Dynamic Hyperbolic Attention Network (DHANet), which leverages intrinsic properties of hyperbolic space to learn representative features. Our method that projects mesh and image features into a unified hyperbolic space includes two modules, ie. dynamic hyperbolic graph convolution and image-attention hyperbolic graph convolution. With these two modules, our method learns mesh features with rich geometry-image multi-modal information and models better hand-object interaction. Our method provides a promising alternative for fine hand-object reconstruction in hyperbolic space. Extensive experiments on three public datasets demonstrate that our method outperforms most state-of-the-art methods.
Rethinking the compositionality of point clouds through regularization in the hyperbolic space
Sep 21, 2022
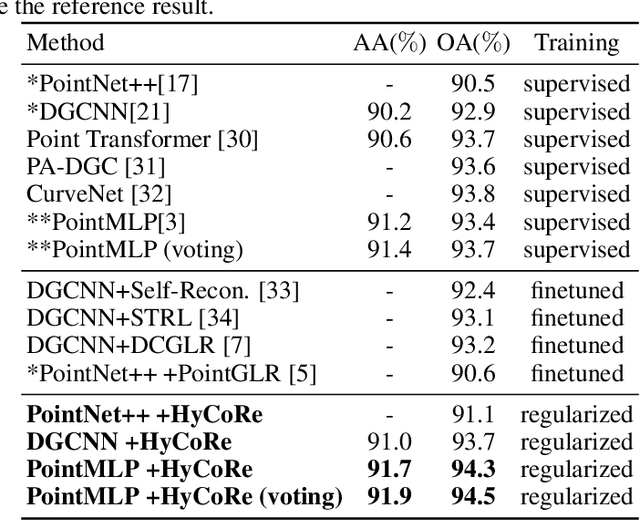
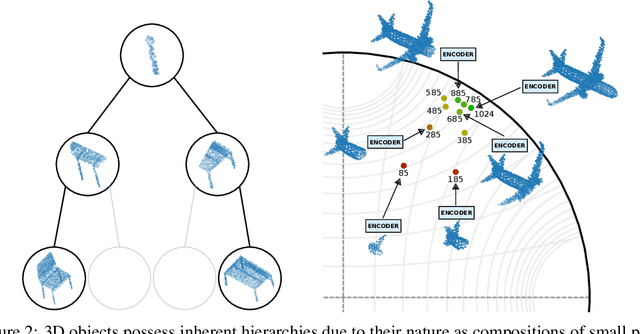
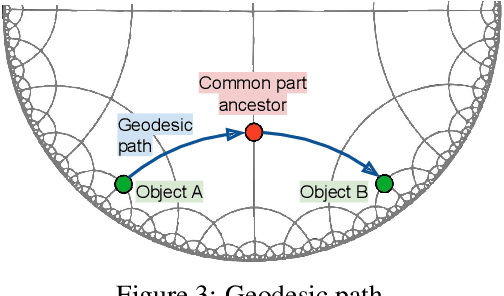
Point clouds of 3D objects exhibit an inherent compositional nature where simple parts can be assembled into progressively more complex shapes to form whole objects. Explicitly capturing such part-whole hierarchy is a long-sought objective in order to build effective models, but its tree-like nature has made the task elusive. In this paper, we propose to embed the features of a point cloud classifier into the hyperbolic space and explicitly regularize the space to account for the part-whole hierarchy. The hyperbolic space is the only space that can successfully embed the tree-like nature of the hierarchy. This leads to substantial improvements in the performance of state-of-art supervised models for point cloud classification.
Exploring the solution space of linear inverse problems with GAN latent geometry
Jul 01, 2022



Inverse problems consist in reconstructing signals from incomplete sets of measurements and their performance is highly dependent on the quality of the prior knowledge encoded via regularization. While traditional approaches focus on obtaining a unique solution, an emerging trend considers exploring multiple feasibile solutions. In this paper, we propose a method to generate multiple reconstructions that fit both the measurements and a data-driven prior learned by a generative adversarial network. In particular, we show that, starting from an initial solution, it is possible to find directions in the latent space of the generative model that are null to the forward operator, and thus keep consistency with the measurements, while inducing significant perceptual change. Our exploration approach allows to generate multiple solutions to the inverse problem an order of magnitude faster than existing approaches; we show results on image super-resolution and inpainting problems.
Self-supervised learning for joint SAR and multispectral land cover classification
Aug 20, 2021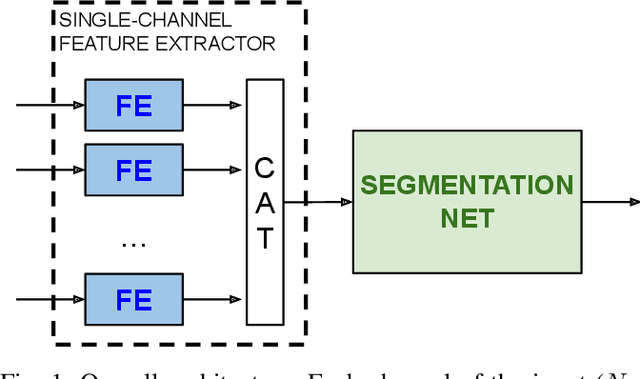
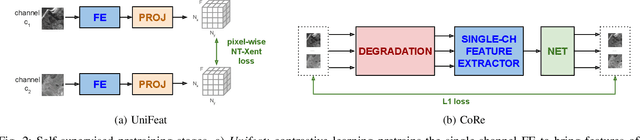
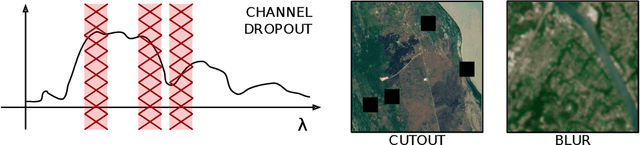
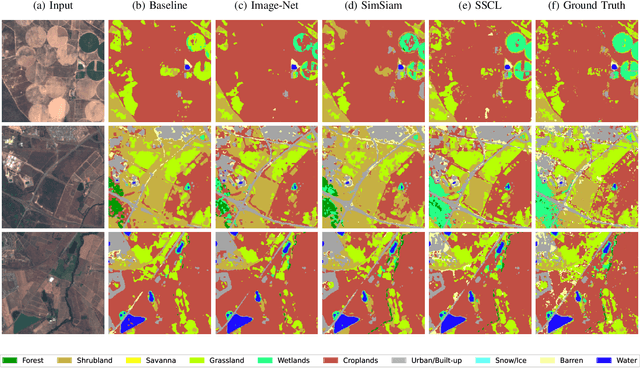
Self-supervised learning techniques are gaining popularity due to their capability of building models that are effective, even when scarce amounts of labeled data are available. In this paper, we present a framework and specific tasks for self-supervised training of multichannel models, such as the fusion of multispectral and synthetic aperture radar images. We show that the proposed self-supervised approach is highly effective at learning features that correlate with the labels for land cover classification. This is enabled by an explicit design of pretraining tasks which promotes bridging the gaps between sensing modalities and exploiting the spectral characteristics of the input. When limited labels are available, using the proposed self-supervised pretraining and supervised finetuning for land cover classification with SAR and multispectral data outperforms conventional approaches such as purely supervised learning, initialization from training on Imagenet and recent self-supervised approaches for computer vision tasks.