 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCRREAM : SCan, Register, REnder And Map:A Framework for Annotating Accurate and Dense 3D Indoor Scenes with a Benchmark
Oct 30, 2024



Traditionally, 3d indoor datasets have generally prioritized scale over ground-truth accuracy in order to obtain improved generalization. However, using these datasets to evaluate dense geometry tasks, such as depth rendering, can be problematic as the meshes of the dataset are often incomplete and may produce wrong ground truth to evaluate the details. In this paper, we propose SCRREAM, a dataset annotation framework that allows annotation of fully dense meshes of objects in the scene and registers camera poses on the real image sequence, which can produce accurate ground truth for both sparse 3D as well as dense 3D tasks. We show the details of the dataset annotation pipeline and showcase four possible variants of datasets that can be obtained from our framework with example scenes, such as indoor reconstruction and SLAM, scene editing & object removal, human reconstruction and 6d pose estimation. Recent pipelines for indoor reconstruction and SLAM serve as new benchmarks. In contrast to previous indoor dataset, our design allows to evaluate dense geometry tasks on eleven sample scenes against accurately rendered ground truth depth maps.
VoxNeRF: Bridging Voxel Representation and Neural Radiance Fields for Enhanced Indoor View Synthesis
Nov 09, 2023



Creating high-quality view synthesis is essential for immersive applications but continues to be problematic, particularly in indoor environments and for real-time deployment. Current techniques frequently require extensive computational time for both training and rendering, and often produce less-than-ideal 3D representations due to inadequate geometric structuring. To overcome this, we introduce VoxNeRF, a novel approach that leverages volumetric representations to enhance the quality and efficiency of indoor view synthesis. Firstly, VoxNeRF constructs a structured scene geometry and converts it into a voxel-based representation. We employ multi-resolution hash grids to adaptively capture spatial features, effectively managing occlusions and the intricate geometry of indoor scenes. Secondly, we propose a unique voxel-guided efficient sampling technique. This innovation selectively focuses computational resources on the most relevant portions of ray segments, substantially reducing optimization time. We validate our approach against three public indoor datasets and demonstrate that VoxNeRF outperforms state-of-the-art methods. Remarkably, it achieves these gains while reducing both training and rendering times, surpassing even Instant-NGP in speed and bringing the technology closer to real-time.
Fg-T2M: Fine-Grained Text-Driven Human Motion Generation via Diffusion Model
Sep 12, 2023



Text-driven human motion generation in computer vision is both significant and challenging. However, current methods are limited to producing either deterministic or imprecise motion sequences, failing to effectively control the temporal and spatial relationships required to conform to a given text description. In this work, we propose a fine-grained method for generating high-quality, conditional human motion sequences supporting precise text description. Our approach consists of two key components: 1) a linguistics-structure assisted module that constructs accurate and complete language feature to fully utilize text information; and 2) a context-aware progressive reasoning module that learns neighborhood and overall semantic linguistics features from shallow and deep graph neural networks to achieve a multi-step inference. Experiments show that our approach outperforms text-driven motion generation methods on HumanML3D and KIT test sets and generates better visually confirmed motion to the text conditions.
Dynamic Hyperbolic Attention Network for Fine Hand-object Reconstruction
Sep 06, 2023Reconstructing both objects and hands in 3D from a single RGB image is complex. Existing methods rely on manually defined hand-object constraints in Euclidean space, leading to suboptimal feature learning. Compared with Euclidean space, hyperbolic space better preserves the geometric properties of meshes thanks to its exponentially-growing space distance, which amplifies the differences between the features based on similarity. In this work, we propose the first precise hand-object reconstruction method in hyperbolic space, namely Dynamic Hyperbolic Attention Network (DHANet), which leverages intrinsic properties of hyperbolic space to learn representative features. Our method that projects mesh and image features into a unified hyperbolic space includes two modules, ie. dynamic hyperbolic graph convolution and image-attention hyperbolic graph convolution. With these two modules, our method learns mesh features with rich geometry-image multi-modal information and models better hand-object interaction. Our method provides a promising alternative for fine hand-object reconstruction in hyperbolic space. Extensive experiments on three public datasets demonstrate that our method outperforms most state-of-the-art methods.
CommonScenes: Generating Commonsense 3D Indoor Scenes with Scene Graphs
May 25, 2023Controllable scene synthesis aims to create interactive environments for various industrial use cases. Scene graphs provide a highly suitable interface to facilitate these applications by abstracting the scene context in a compact manner. Existing methods, reliant on retrieval from extensive databases or pre-trained shape embeddings, often overlook scene-object and object-object relationships, leading to inconsistent results due to their limited generation capacity. To address this issue, we present CommonScenes, a fully generative model that converts scene graphs into corresponding controllable 3D scenes, which are semantically realistic and conform to commonsense. Our pipeline consists of two branches, one predicting the overall scene layout via a variational auto-encoder and the other generating compatible shapes via latent diffusion, capturing global scene-object and local inter-object relationships while preserving shape diversity. The generated scenes can be manipulated by editing the input scene graph and sampling the noise in the diffusion model. Due to lacking a scene graph dataset offering high-quality object-level meshes with relations, we also construct SG-FRONT, enriching the off-the-shelf indoor dataset 3D-FRONT with additional scene graph labels. Extensive experiments are conducted on SG-FRONT where CommonScenes shows clear advantages over other methods regarding generation consistency, quality, and diversity. Codes and the dataset will be released upon acceptance.
Incremental 3D Semantic Scene Graph Prediction from RGB Sequences
May 06, 2023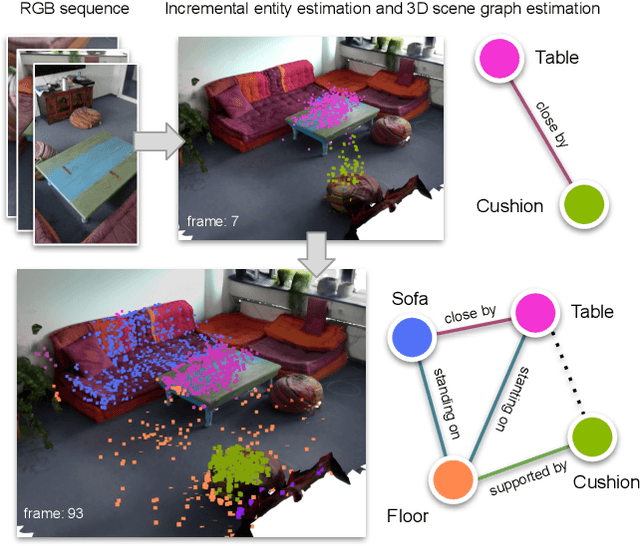
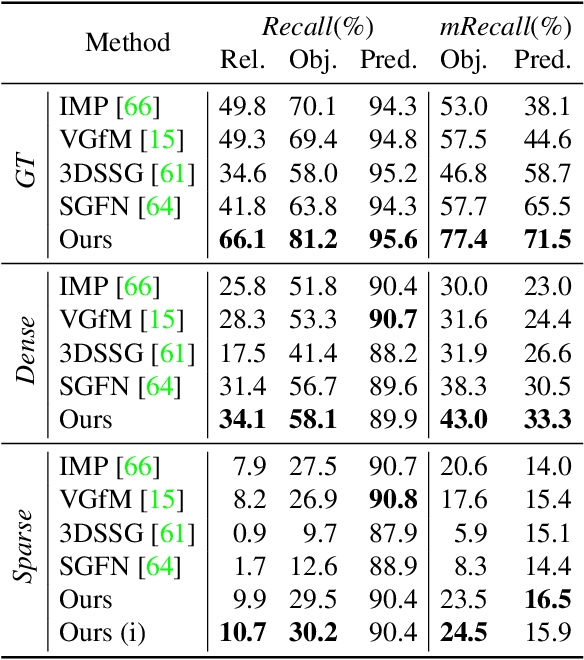

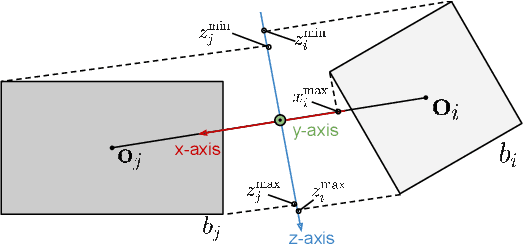
3D semantic scene graphs are a powerful holistic representation as they describe the individual objects and depict the relation between them. They are compact high-level graphs that enable many tasks requiring scene reasoning. In real-world settings, existing 3D estimation methods produce robust predictions that mostly rely on dense inputs. In this work, we propose a real-time framework that incrementally builds a consistent 3D semantic scene graph of a scene given an RGB image sequence. Our method consists of a novel incremental entity estimation pipeline and a scene graph prediction network. The proposed pipeline simultaneously reconstructs a sparse point map and fuses entity estimation from the input images. The proposed network estimates 3D semantic scene graphs with iterative message passing using multi-view and geometric features extracted from the scene entities. Extensive experiments on the 3RScan dataset show the effectiveness of the proposed method in this challenging task, outperforming state-of-the-art approaches.
HouseCat6D -- A Large-Scale Multi-Modal Category Level 6D Object Pose Dataset with Household Objects in Realistic Scenarios
Dec 21, 2022



Estimating the 6D pose of objects is one of the major fields in 3D computer vision. Since the promising outcomes from instance-level pose estimation, the research trends are heading towards category-level pose estimation for more practical application scenarios. However, unlike well-established instance-level pose datasets, available category-level datasets lack annotation quality and provided pose quantity. We propose the new category level 6D pose dataset HouseCat6D featuring 1) Multi-modality of Polarimetric RGB+P and Depth, 2) Highly diverse 194 objects of 10 household object categories including 2 photometrically challenging categories, 3) High-quality pose annotation with an error range of only 1.35 mm to 1.74 mm, 4) 41 large scale scenes with extensive viewpoint coverage, 5) Checkerboard-free environment throughout the entire scene. We also provide benchmark results of state-of-the-art category-level pose estimation networks.
MonoGraspNet: 6-DoF Grasping with a Single RGB Image
Sep 26, 2022
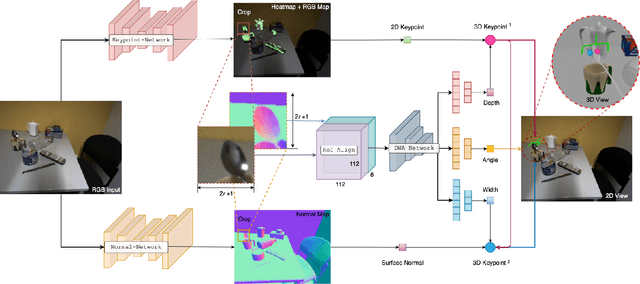
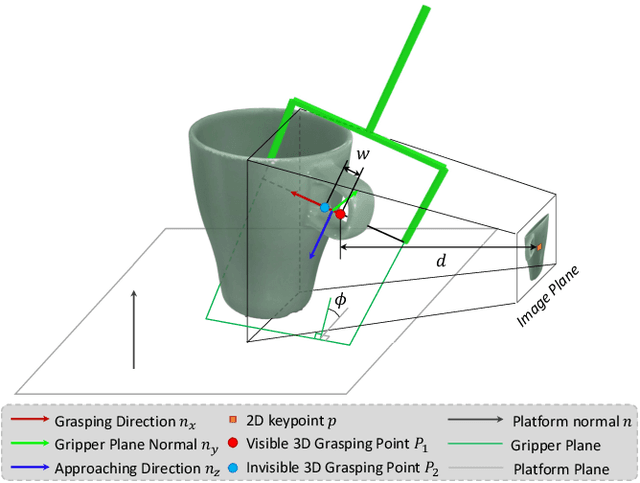

6-DoF robotic grasping is a long-lasting but unsolved problem. Recent methods utilize strong 3D networks to extract geometric grasping representations from depth sensors, demonstrating superior accuracy on common objects but perform unsatisfactorily on photometrically challenging objects, e.g., objects in transparent or reflective materials. The bottleneck lies in that the surface of these objects can not reflect back accurate depth due to the absorption or refraction of light. In this paper, in contrast to exploiting the inaccurate depth data, we propose the first RGB-only 6-DoF grasping pipeline called MonoGraspNet that utilizes stable 2D features to simultaneously handle arbitrary object grasping and overcome the problems induced by photometrically challenging objects. MonoGraspNet leverages keypoint heatmap and normal map to recover the 6-DoF grasping poses represented by our novel representation parameterized with 2D keypoints with corresponding depth, grasping direction, grasping width, and angle. Extensive experiments in real scenes demonstrate that our method can achieve competitive results in grasping common objects and surpass the depth-based competitor by a large margin in grasping photometrically challenging objects. To further stimulate robotic manipulation research, we additionally annotate and open-source a multi-view and multi-scene real-world grasping dataset, containing 120 objects of mixed photometric complexity with 20M accurate grasping labels.
Bending Graphs: Hierarchical Shape Matching using Gated Optimal Transport
Feb 03, 2022



Shape matching has been a long-studied problem for the computer graphics and vision community. The objective is to predict a dense correspondence between meshes that have a certain degree of deformation. Existing methods either consider the local description of sampled points or discover correspondences based on global shape information. In this work, we investigate a hierarchical learning design, to which we incorporate local patch-level information and global shape-level structures. This flexible representation enables correspondence prediction and provides rich features for the matching stage. Finally, we propose a novel optimal transport solver by recurrently updating features on non-confident nodes to learn globally consistent correspondences between the shapes. Our results on publicly available datasets suggest robust performance in presence of severe deformations without the need for extensive training or refinement.
SceneGraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences
Mar 31, 2021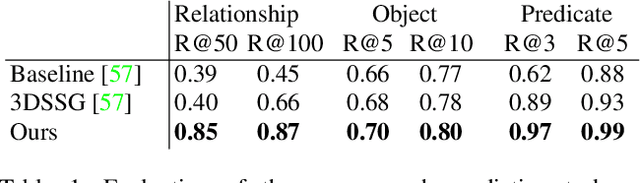
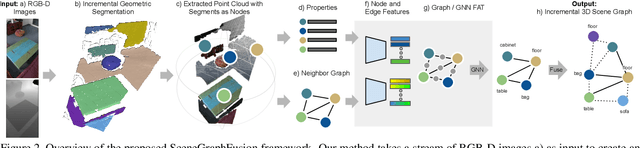
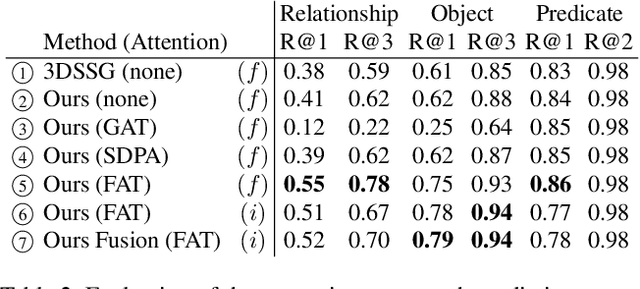
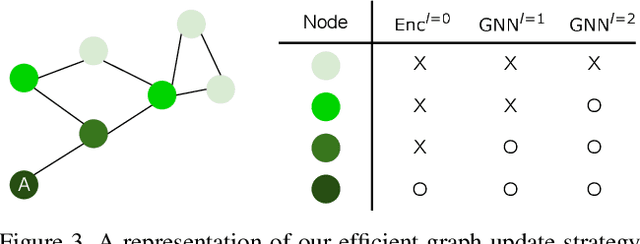
Scene graphs are a compact and explicit representation successfully used in a variety of 2D scene understanding tasks. This work proposes a method to incrementally build up semantic scene graphs from a 3D environment given a sequence of RGB-D frames. To this end, we aggregate PointNet features from primitive scene components by means of a graph neural network. We also propose a novel attention mechanism well suited for partial and missing graph data present in such an incremental reconstruction scenario. Although our proposed method is designed to run on submaps of the scene, we show it also transfers to entire 3D scenes. Experiments show that our approach outperforms 3D scene graph prediction methods by a large margin and its accuracy is on par with other 3D semantic and panoptic segmentation methods while running at 35 Hz.