 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Open-Vocabulary to Vocabulary-Free Semantic Segmentation
Feb 17, 2025Open-vocabulary semantic segmentation enables models to identify novel object categories beyond their training data. While this flexibility represents a significant advancement, current approaches still rely on manually specified class names as input, creating an inherent bottleneck in real-world applications. This work proposes a Vocabulary-Free Semantic Segmentation pipeline, eliminating the need for predefined class vocabularies. Specifically, we address the chicken-and-egg problem where users need knowledge of all potential objects within a scene to identify them, yet the purpose of segmentation is often to discover these objects. The proposed approach leverages Vision-Language Models to automatically recognize objects and generate appropriate class names, aiming to solve the challenge of class specification and naming quality. Through extensive experiments on several public datasets, we highlight the crucial role of the text encoder in model performance, particularly when the image text classes are paired with generated descriptions. Despite the challenges introduced by the sensitivity of the segmentation text encoder to false negatives within the class tagging process, which adds complexity to the task, we demonstrate that our fully automated pipeline significantly enhances vocabulary-free segmentation accuracy across diverse real-world scenarios.
Learning from the Web: Language Drives Weakly-Supervised Incremental Learning for Semantic Segmentation
Jul 18, 2024



Current weakly-supervised incremental learning for semantic segmentation (WILSS) approaches only consider replacing pixel-level annotations with image-level labels, while the training images are still from well-designed datasets. In this work, we argue that widely available web images can also be considered for the learning of new classes. To achieve this, firstly we introduce a strategy to select web images which are similar to previously seen examples in the latent space using a Fourier-based domain discriminator. Then, an effective caption-driven reharsal strategy is proposed to preserve previously learnt classes. To our knowledge, this is the first work to rely solely on web images for both the learning of new concepts and the preservation of the already learned ones in WILSS. Experimental results show that the proposed approach can reach state-of-the-art performances without using manually selected and annotated data in the incremental steps.
When Cars meet Drones: Hyperbolic Federated Learning for Source-Free Domain Adaptation in Adverse Weather
Mar 20, 2024



In Federated Learning (FL), multiple clients collaboratively train a global model without sharing private data. In semantic segmentation, the Federated source Free Domain Adaptation (FFreeDA) setting is of particular interest, where clients undergo unsupervised training after supervised pretraining at the server side. While few recent works address FL for autonomous vehicles, intrinsic real-world challenges such as the presence of adverse weather conditions and the existence of different autonomous agents are still unexplored. To bridge this gap, we address both problems and introduce a new federated semantic segmentation setting where both car and drone clients co-exist and collaborate. Specifically, we propose a novel approach for this setting which exploits a batch-norm weather-aware strategy to dynamically adapt the model to the different weather conditions, while hyperbolic space prototypes are used to align the heterogeneous client representations. Finally, we introduce FLYAWARE, the first semantic segmentation dataset with adverse weather data for aerial vehicles.
RECALL+: Adversarial Web-based Replay for Continual Learning in Semantic Segmentation
Sep 19, 2023Catastrophic forgetting of previous knowledge is a critical issue in continual learning typically handled through various regularization strategies. However, existing methods struggle especially when several incremental steps are performed. In this paper, we extend our previous approach (RECALL) and tackle forgetting by exploiting unsupervised web-crawled data to retrieve examples of old classes from online databases. Differently from the original approach that did not perform any evaluation of the web data, here we introduce two novel approaches based on adversarial learning and adaptive thresholding to select from web data only samples strongly resembling the statistics of the no longer available training ones. Furthermore, we improved the pseudo-labeling scheme to achieve a more accurate labeling of web data that also consider classes being learned in the current step. Experimental results show that this enhanced approach achieves remarkable results, especially when multiple incremental learning steps are performed.
SynDrone -- Multi-modal UAV Dataset for Urban Scenarios
Aug 21, 2023



The development of computer vision algorithms for Unmanned Aerial Vehicles (UAVs) imagery heavily relies on the availability of annotated high-resolution aerial data. However, the scarcity of large-scale real datasets with pixel-level annotations poses a significant challenge to researchers as the limited number of images in existing datasets hinders the effectiveness of deep learning models that require a large amount of training data. In this paper, we propose a multimodal synthetic dataset containing both images and 3D data taken at multiple flying heights to address these limitations. In addition to object-level annotations, the provided data also include pixel-level labeling in 28 classes, enabling exploration of the potential advantages in tasks like semantic segmentation. In total, our dataset contains 72k labeled samples that allow for effective training of deep architectures showing promising results in synthetic-to-real adaptation. The dataset will be made publicly available to support the development of novel computer vision methods targeting UAV applications.
Source-Free Domain Adaptation for RGB-D Semantic Segmentation with Vision Transformers
May 23, 2023With the increasing availability of depth sensors, multimodal frameworks that combine color information with depth data are attracting increasing interest. In the challenging task of semantic segmentation, depth maps allow to distinguish between similarly colored objects at different depths and provide useful geometric cues. On the other side, ground truth data for semantic segmentation is burdensome to be provided and thus domain adaptation is another significant research area. Specifically, we address the challenging source-free domain adaptation setting where the adaptation is performed without reusing source data. We propose MISFIT: MultImodal Source-Free Information fusion Transformer, a depth-aware framework which injects depth information into a segmentation module based on vision transformers at multiple stages, namely at the input, feature and output levels. Color and depth style transfer helps early-stage domain alignment while re-wiring self-attention between modalities creates mixed features allowing the extraction of better semantic content. Furthermore, a depth-based entropy minimization strategy is also proposed to adaptively weight regions at different distances. Our framework, which is also the first approach using vision transformers for source-free semantic segmentation, shows noticeable performance improvements with respect to standard strategies.
HouseCat6D -- A Large-Scale Multi-Modal Category Level 6D Object Pose Dataset with Household Objects in Realistic Scenarios
Dec 21, 2022



Estimating the 6D pose of objects is one of the major fields in 3D computer vision. Since the promising outcomes from instance-level pose estimation, the research trends are heading towards category-level pose estimation for more practical application scenarios. However, unlike well-established instance-level pose datasets, available category-level datasets lack annotation quality and provided pose quantity. We propose the new category level 6D pose dataset HouseCat6D featuring 1) Multi-modality of Polarimetric RGB+P and Depth, 2) Highly diverse 194 objects of 10 household object categories including 2 photometrically challenging categories, 3) High-quality pose annotation with an error range of only 1.35 mm to 1.74 mm, 4) 41 large scale scenes with extensive viewpoint coverage, 5) Checkerboard-free environment throughout the entire scene. We also provide benchmark results of state-of-the-art category-level pose estimation networks.
DepthFormer: Multimodal Positional Encodings and Cross-Input Attention for Transformer-Based Segmentation Networks
Nov 08, 2022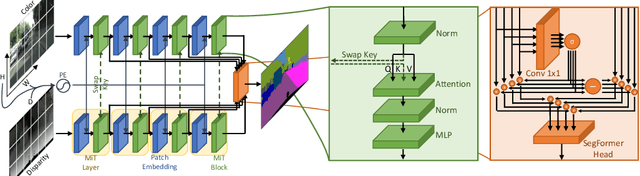


Most approaches for semantic segmentation use only information from color cameras to parse the scenes, yet recent advancements show that using depth data allows to further improve performances. In this work, we focus on transformer-based deep learning architectures, that have achieved state-of-the-art performances on the segmentation task, and we propose to employ depth information by embedding it in the positional encoding. Effectively, we extend the network to multimodal data without adding any parameters and in a natural way that makes use of the strength of transformers' self-attention modules. We also investigate the idea of performing cross-modality operations inside the attention module, swapping the key inputs between the depth and color branches. Our approach consistently improves performances on the Cityscapes benchmark.