 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoleyDirector: Fine-Grained Temporal Steering for Video-to-Audio Generation via Structured Scripts
Mar 20, 2026Recent Video-to-Audio (V2A) methods have achieved remarkable progress, enabling the synthesis of realistic, high-quality audio. However, they struggle with fine-grained temporal control in multi-event scenarios or when visual cues are insufficient, such as small regions, off-screen sounds, or occluded or partially visible objects. In this paper, we propose FoleyDirector, a framework that, for the first time, enables precise temporal guidance in DiT-based V2A generation while preserving the base model's audio quality and allowing seamless switching between V2A generation and temporally controlled synthesis. FoleyDirector introduces Structured Temporal Scripts (STS), a set of captions corresponding to short temporal segments, to provide richer temporal information. These features are integrated via the Script-Guided Temporal Fusion Module, which employs Temporal Script Attention to fuse STS features coherently. To handle complex multi-event scenarios, we further propose Bi-Frame Sound Synthesis, enabling parallel in-frame and out-of-frame audio generation and improving controllability. To support training and evaluation, we construct the DirectorSound dataset and introduce VGGSoundDirector and DirectorBench. Experiments demonstrate that FoleyDirector substantially enhances temporal controllability while maintaining high audio fidelity, empowering users to act as Foley directors and advancing V2A toward more expressive and controllable generation.
Diffusion-driven SpatioTemporal Graph KANsformer for Medical Examination Recommendation
May 12, 2025Recommendation systems in AI-based medical diagnostics and treatment constitute a critical component of AI in healthcare. Although some studies have explored this area and made notable progress, healthcare recommendation systems remain in their nascent stage. And these researches mainly target the treatment process such as drug or disease recommendations. In addition to the treatment process, the diagnostic process, particularly determining which medical examinations are necessary to evaluate the condition, also urgently requires intelligent decision support. To bridge this gap, we first formalize the task of medical examination recommendations. Compared to traditional recommendations, the medical examination recommendation involves more complex interactions. This complexity arises from two folds: 1) The historical medical records for examination recommendations are heterogeneous and redundant, which makes the recommendation results susceptible to noise. 2) The correlation between the medical history of patients is often irregular, making it challenging to model spatiotemporal dependencies. Motivated by the above observation, we propose a novel Diffusion-driven SpatioTemporal Graph KANsformer for Medical Examination Recommendation (DST-GKAN) with a two-stage learning paradigm to solve the above challenges. In the first stage, we exploit a task-adaptive diffusion model to distill recommendation-oriented information by reducing the noises in heterogeneous medical data. In the second stage, a spatiotemporal graph KANsformer is proposed to simultaneously model the complex spatial and temporal relationships. Moreover, to facilitate the medical examination recommendation research, we introduce a comprehensive dataset. The experimental results demonstrate the state-of-the-art performance of the proposed method compared to various competitive baselines.
CoCoDiff: Diversifying Skeleton Action Features via Coarse-Fine Text-Co-Guided Latent Diffusion
Apr 30, 2025In action recognition tasks, feature diversity is essential for enhancing model generalization and performance. Existing methods typically promote feature diversity by expanding the training data in the sample space, which often leads to inefficiencies and semantic inconsistencies. To overcome these problems, we propose a novel Coarse-fine text co-guidance Diffusion model (CoCoDiff). CoCoDiff generates diverse yet semantically consistent features in the latent space by leveraging diffusion and multi-granularity textual guidance. Specifically, our approach feeds spatio-temporal features extracted from skeleton sequences into a latent diffusion model to generate diverse action representations. Meanwhile, we introduce a coarse-fine text co-guided strategy that leverages textual information from large language models (LLMs) to ensure semantic consistency between the generated features and the original inputs. It is noted that CoCoDiff operates as a plug-and-play auxiliary module during training, incurring no additional inference cost. Extensive experiments demonstrate that CoCoDiff achieves SOTA performance on skeleton-based action recognition benchmarks, including NTU RGB+D, NTU RGB+D 120 and Kinetics-Skeleton.
Painting with Words: Elevating Detailed Image Captioning with Benchmark and Alignment Learning
Mar 10, 2025



Image captioning has long been a pivotal task in visual understanding, with recent advancements in vision-language models (VLMs) significantly enhancing the ability to generate detailed image captions. However, the evaluation of detailed image captioning remains underexplored due to outdated evaluation metrics and coarse annotations. In this paper, we introduce DeCapBench along with a novel metric, DCScore, specifically designed for detailed captioning tasks. DCScore evaluates hallucinations and fine-grained comprehensiveness by deconstructing responses into the smallest self-sufficient units, termed primitive information units, and assessing them individually. Our evaluation shows that DCScore aligns more closely with human judgment than other rule-based or model-based metrics. Concurrently, DeCapBench exhibits a high correlation with VLM arena results on descriptive tasks, surpassing existing benchmarks for vision-language models. Additionally, we present an automatic fine-grained feedback collection method, FeedQuill, for preference optimization based on our advanced metric, showing robust generalization capabilities across auto-generated preference data. Extensive experiments on multiple VLMs demonstrate that our method not only significantly reduces hallucinations but also enhances performance across various benchmarks, achieving superior detail captioning performance while surpassing GPT-4o.
Learned Correction Methods for Ultrasound Computed Tomography Imaging Using Simplified Physics Models
Feb 13, 2025


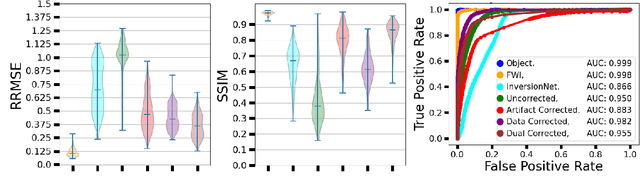
Ultrasound computed tomography (USCT) is an emerging modality for breast imaging. Image reconstruction methods that incorporate accurate wave physics produce high resolution quantitative images of acoustic properties but are computationally expensive. The use of a simplified linear model in reconstruction reduces computational expense at the cost of reduced accuracy. This work aims to systematically compare different learning approaches for USCT reconstruction utilizing simplified linear models. This work considered various learning approaches to compensate for errors stemming from a linearized wave propagation model: correction in the data and image domains. The resulting image reconstruction methods are systematically assessed, alongside data-driven and model-based methods, in four virtual imaging studies utilizing anatomically realistic numerical phantoms. Image quality was assessed utilizing relative root mean square error (RRMSE), structural similarity index measure (SSIM), and a task-based assessment for tumor detection. Correction in the measurement domain resulted in images with minor visual artifacts and highly accurate task performance. Correction in the image domain demonstrated a heavy bias on training data, resulting in hallucinations, but greater robustness to measurement noise. Combining both forms of correction performed best in terms of RRMSE and SSIM, at the cost of task performance. This work systematically assessed learned reconstruction methods incorporating an approximated physical model for USCT imaging. Results demonstrated the importance of incorporating physics, compared to data-driven methods. Learning a correction in the data domain led to better task performance and robust out-of-distribution generalization compared to correction in the image domain.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
Spatio-Temporal Progressive Attention Model for EEG Classification in Rapid Serial Visual Presentation Task
Feb 02, 2025



As a type of multi-dimensional sequential data, the spatial and temporal dependencies of electroencephalogram (EEG) signals should be further investigated. Thus, in this paper, we propose a novel spatial-temporal progressive attention model (STPAM) to improve EEG classification in rapid serial visual presentation (RSVP) tasks. STPAM first adopts three distinct spatial experts to learn the spatial topological information of brain regions progressively, which is used to minimize the interference of irrelevant brain regions. Concretely, the former expert filters out EEG electrodes in the relative brain regions to be used as prior knowledge for the next expert, ensuring that the subsequent experts gradually focus their attention on information from significant EEG electrodes. This process strengthens the effect of the important brain regions. Then, based on the above-obtained feature sequence with spatial information, three temporal experts are adopted to capture the temporal dependence by progressively assigning attention to the crucial EEG slices. Except for the above EEG classification method, in this paper, we build a novel Infrared RSVP EEG Dataset (IRED) which is based on dim infrared images with small targets for the first time, and conduct extensive experiments on it. The results show that our STPAM can achieve better performance than all the compared methods.
Adaptive Progressive Attention Graph Neural Network for EEG Emotion Recognition
Jan 24, 2025In recent years, numerous neuroscientific studies have shown that human emotions are closely linked to specific brain regions, with these regions exhibiting variability across individuals and emotional states. To fully leverage these neural patterns, we propose an Adaptive Progressive Attention Graph Neural Network (APAGNN), which dynamically captures the spatial relationships among brain regions during emotional processing. The APAGNN employs three specialized experts that progressively analyze brain topology. The first expert captures global brain patterns, the second focuses on region-specific features, and the third examines emotion-related channels. This hierarchical approach enables increasingly refined analysis of neural activity. Additionally, a weight generator integrates the outputs of all three experts, balancing their contributions to produce the final predictive label. Extensive experiments on three publicly available datasets (SEED, SEED-IV and MPED) demonstrate that the proposed method enhances EEG emotion recognition performance, achieving superior results compared to baseline methods.
Integrating Language-Image Prior into EEG Decoding for Cross-Task Zero-Calibration RSVP-BCI
Jan 06, 2025



Rapid Serial Visual Presentation (RSVP)-based Brain-Computer Interface (BCI) is an effective technology used for information detection by detecting Event-Related Potentials (ERPs). The current RSVP decoding methods can perform well in decoding EEG signals within a single RSVP task, but their decoding performance significantly decreases when directly applied to different RSVP tasks without calibration data from the new tasks. This limits the rapid and efficient deployment of RSVP-BCI systems for detecting different categories of targets in various scenarios. To overcome this limitation, this study aims to enhance the cross-task zero-calibration RSVP decoding performance. First, we design three distinct RSVP tasks for target image retrieval and build an open-source dataset containing EEG signals and corresponding stimulus images. Then we propose an EEG with Language-Image Prior fusion Transformer (ELIPformer) for cross-task zero-calibration RSVP decoding. Specifically, we propose a prompt encoder based on the language-image pre-trained model to extract language-image features from task-specific prompts and stimulus images as prior knowledge for enhancing EEG decoding. A cross bidirectional attention mechanism is also adopted to facilitate the effective feature fusion and alignment between the EEG and language-image features. Extensive experiments demonstrate that the proposed model achieves superior performance in cross-task zero-calibration RSVP decoding, which promotes the RSVP-BCI system from research to practical application.
BeSimulator: A Large Language Model Powered Text-based Behavior Simulator
Sep 24, 2024



Traditional robot simulators focus on physical process modeling and realistic rendering, often suffering from high computational costs, inefficiencies, and limited adaptability. To handle this issue, we propose Behavior Simulation in robotics to emphasize checking the behavior logic of robots and achieving sufficient alignment between the outcome of robot actions and real scenarios. In this paper, we introduce BeSimulator, a modular and novel LLM-powered framework, as an attempt towards behavior simulation in the context of text-based environments. By constructing text-based virtual environments and performing semantic-level simulation, BeSimulator can generalize across scenarios and achieve long-horizon complex simulation. Inspired by human cognition processes, it employs a "consider-decide-capture-transfer" methodology, termed Chain of Behavior Simulation, which excels at analyzing action feasibility and state transitions. Additionally, BeSimulator incorporates code-driven reasoning to enable arithmetic operations and enhance reliability, as well as integrates reflective feedback to refine simulation. Based on our manually constructed behavior-tree-based simulation benchmark BTSIMBENCH, our experiments show a significant performance improvement in behavior simulation compared to baselines, ranging from 14.7% to 26.6%.