 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeSimulator: A Large Language Model Powered Text-based Behavior Simulator
Sep 24, 2024



Traditional robot simulators focus on physical process modeling and realistic rendering, often suffering from high computational costs, inefficiencies, and limited adaptability. To handle this issue, we propose Behavior Simulation in robotics to emphasize checking the behavior logic of robots and achieving sufficient alignment between the outcome of robot actions and real scenarios. In this paper, we introduce BeSimulator, a modular and novel LLM-powered framework, as an attempt towards behavior simulation in the context of text-based environments. By constructing text-based virtual environments and performing semantic-level simulation, BeSimulator can generalize across scenarios and achieve long-horizon complex simulation. Inspired by human cognition processes, it employs a "consider-decide-capture-transfer" methodology, termed Chain of Behavior Simulation, which excels at analyzing action feasibility and state transitions. Additionally, BeSimulator incorporates code-driven reasoning to enable arithmetic operations and enhance reliability, as well as integrates reflective feedback to refine simulation. Based on our manually constructed behavior-tree-based simulation benchmark BTSIMBENCH, our experiments show a significant performance improvement in behavior simulation compared to baselines, ranging from 14.7% to 26.6%.
Task2Morph: Differentiable Task-inspired Framework for Contact-Aware Robot Design
Mar 28, 2024
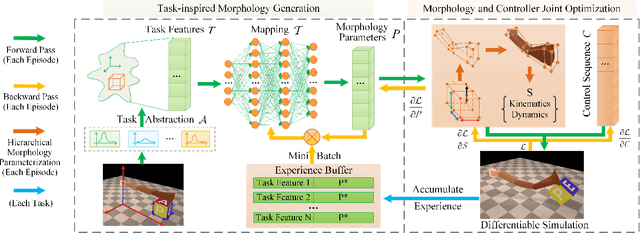
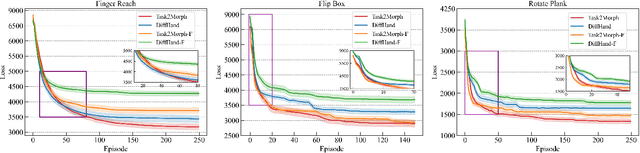

Optimizing the morphologies and the controllers that adapt to various tasks is a critical issue in the field of robot design, aka. embodied intelligence. Previous works typically model it as a joint optimization problem and use search-based methods to find the optimal solution in the morphology space. However, they ignore the implicit knowledge of task-to-morphology mapping which can directly inspire robot design. For example, flipping heavier boxes tends to require more muscular robot arms. This paper proposes a novel and general differentiable task-inspired framework for contact-aware robot design called Task2Morph. We abstract task features highly related to task performance and use them to build a task-to-morphology mapping. Further, we embed the mapping into a differentiable robot design process, where the gradient information is leveraged for both the mapping learning and the whole optimization. The experiments are conducted on three scenarios, and the results validate that Task2Morph outperforms DiffHand, which lacks a task-inspired morphology module, in terms of efficiency and effectiveness.
* 9 pages, 10 figures, published to IROS
A Study on Training and Developing Large Language Models for Behavior Tree Generation
Jan 16, 2024This paper presents an innovative exploration of the application potential of large language models (LLM) in addressing the challenging task of automatically generating behavior trees (BTs) for complex tasks. The conventional manual BT generation method is inefficient and heavily reliant on domain expertise. On the other hand, existing automatic BT generation technologies encounter bottlenecks related to task complexity, model adaptability, and reliability. In order to overcome these challenges, we propose a novel methodology that leverages the robust representation and reasoning abilities of LLMs. The core contribution of this paper lies in the design of a BT generation framework based on LLM, which encompasses the entire process, from data synthesis and model training to application developing and data verification. Synthetic data is introduced to train the BT generation model (BTGen model), enhancing its understanding and adaptability to various complex tasks, thereby significantly improving its overall performance. In order to ensure the effectiveness and executability of the generated BTs, we emphasize the importance of data verification and introduce a multilevel verification strategy. Additionally, we explore a range of agent design and development schemes with LLM as the central element. We hope that the work in this paper may provide a reference for the researchers who are interested in BT generation based on LLMs.
MVP: Meta Visual Prompt Tuning for Few-Shot Remote Sensing Image Scene Classification
Sep 17, 2023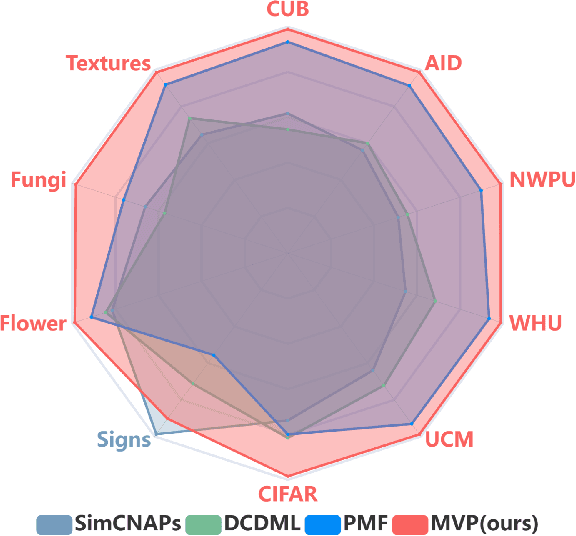
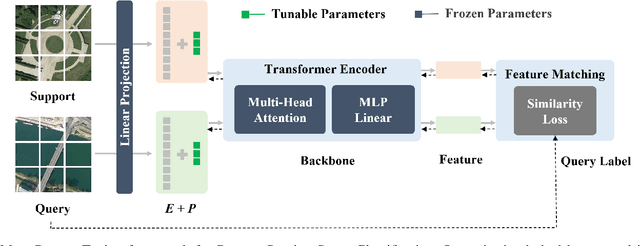
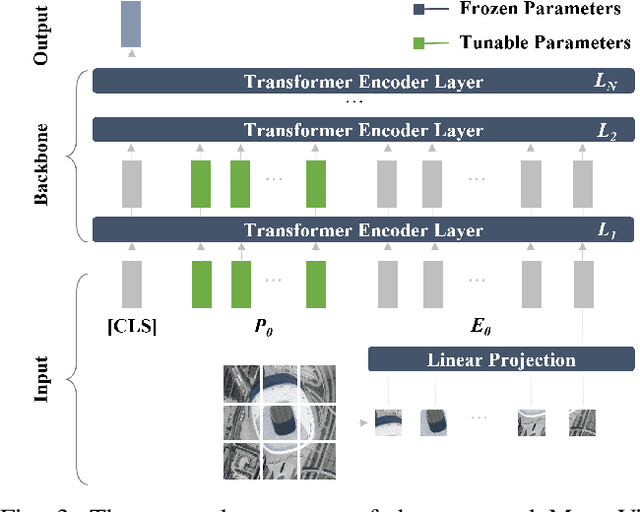
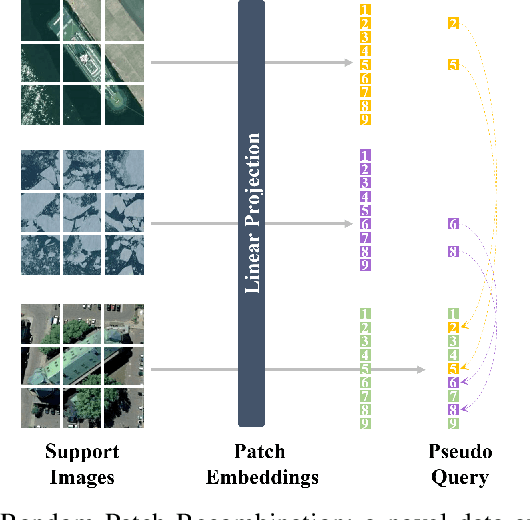
Vision Transformer (ViT) models have recently emerged as powerful and versatile models for various visual tasks. Recently, a work called PMF has achieved promising results in few-shot image classification by utilizing pre-trained vision transformer models. However, PMF employs full fine-tuning for learning the downstream tasks, leading to significant overfitting and storage issues, especially in the remote sensing domain. In order to tackle these issues, we turn to the recently proposed parameter-efficient tuning methods, such as VPT, which updates only the newly added prompt parameters while keeping the pre-trained backbone frozen. Inspired by VPT, we propose the Meta Visual Prompt Tuning (MVP) method. Specifically, we integrate the VPT method into the meta-learning framework and tailor it to the remote sensing domain, resulting in an efficient framework for Few-Shot Remote Sensing Scene Classification (FS-RSSC). Furthermore, we introduce a novel data augmentation strategy based on patch embedding recombination to enhance the representation and diversity of scenes for classification purposes. Experiment results on the FS-RSSC benchmark demonstrate the superior performance of the proposed MVP over existing methods in various settings, such as various-way-various-shot, various-way-one-shot, and cross-domain adaptation.
Expediting Distributed DNN Training with Device Topology-Aware Graph Deployment
Feb 13, 2023



This paper presents TAG, an automatic system to derive optimized DNN training graph and its deployment onto any device topology, for expedited training in device- and topology- heterogeneous ML clusters. We novelly combine both the DNN computation graph and the device topology graph as input to a graph neural network (GNN), and join the GNN with a search-based method to quickly identify optimized distributed training strategies. To reduce communication in a heterogeneous cluster, we further explore a lossless gradient compression technique and solve a combinatorial optimization problem to automatically apply the technique for training time minimization. We evaluate TAG with various representative DNN models and device topologies, showing that it can achieve up to 4.56x training speed-up as compared to existing schemes. TAG can produce efficient deployment strategies for both unseen DNN models and unseen device topologies, without heavy fine-tuning.
OneFlow: Redesign the Distributed Deep Learning Framework from Scratch
Oct 29, 2021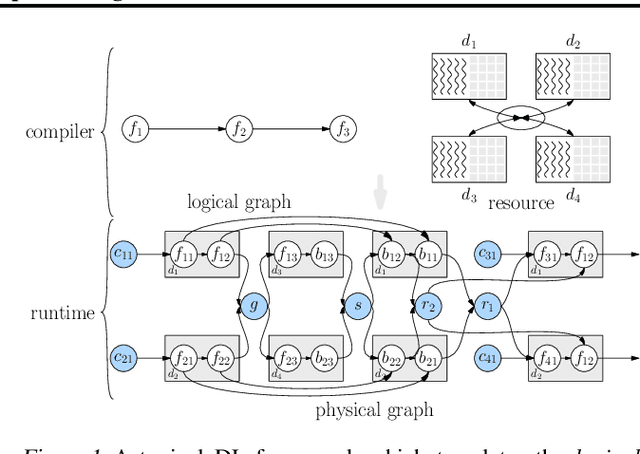
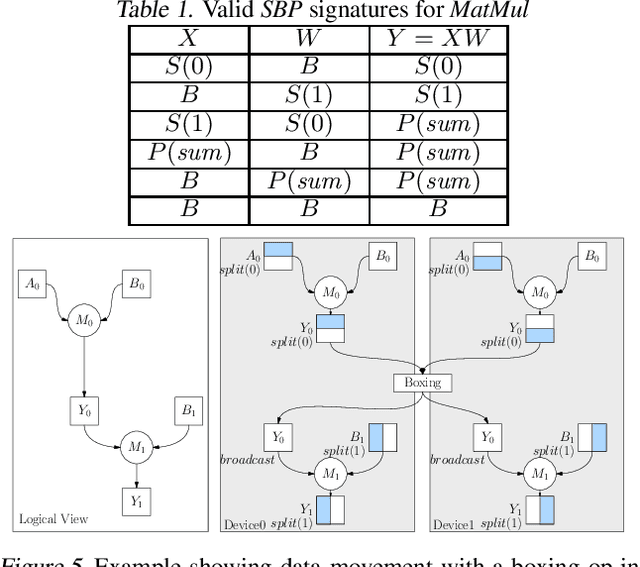
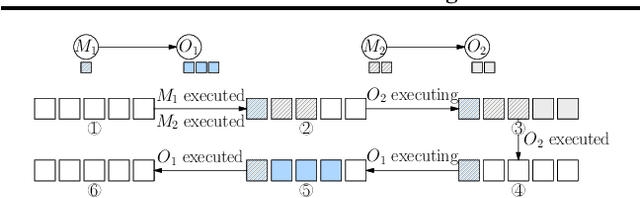

Deep learning frameworks such as TensorFlow and PyTorch provide a productive interface for expressing and training a deep neural network (DNN) model on a single device or using data parallelism. Still, they may not be flexible or efficient enough in training emerging large models on distributed devices, which require more sophisticated parallelism beyond data parallelism. Plugins or wrappers have been developed to strengthen these frameworks for model or pipeline parallelism, but they complicate the usage and implementation of distributed deep learning. Aiming at a simple, neat redesign of distributed deep learning frameworks for various parallelism paradigms, we present OneFlow, a novel distributed training framework based on an SBP (split, broadcast and partial-value) abstraction and the actor model. SBP enables much easier programming of data parallelism and model parallelism than existing frameworks, and the actor model provides a succinct runtime mechanism to manage the complex dependencies imposed by resource constraints, data movement and computation in distributed deep learning. We demonstrate the general applicability and efficiency of OneFlow for training various large DNN models with case studies and extensive experiments. The results show that OneFlow outperforms many well-known customized libraries built on top of the state-of-the-art frameworks. The code of OneFlow is available at: https://github.com/Oneflow-Inc/oneflow.
CNN Feature boosted SeqSLAM for Real-Time Loop Closure Detection
Apr 17, 2017

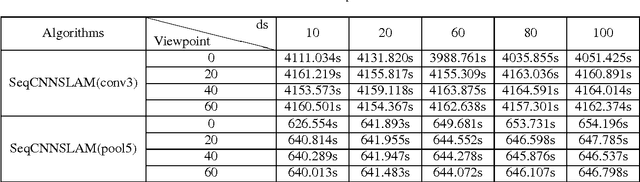
Loop closure detection (LCD) is an indispensable part of simultaneous localization and mapping systems (SLAM); it enables robots to produce a consistent map by recognizing previously visited places. When robots operate over extended periods, robustness to viewpoint and condition changes as well as satisfactory real-time performance become essential requirements for a practical LCD system. This paper presents an approach to directly utilize the outputs at the intermediate layer of a pre-trained convolutional neural network (CNN) as image descriptors. The matching location is determined by matching the image sequences through a method called SeqCNNSLAM. The utility of SeqCNNSLAM is comprehensively evaluated in terms of viewpoint and condition invariance. Experiments show that SeqCNNSLAM outperforms state-of-the-art LCD systems, such as SeqSLAM and Change Removal, in most cases. To allow for the real-time performance of SeqCNNSLAM, an acceleration method, A-SeqCNNSLAM, is established. This method exploits the location relationship between the matching images of adjacent images to reduce the matching range of the current image. Results demonstrate that acceleration of 4-6 is achieved with minimal accuracy degradation, and the method's runtime satisfies the real-time demand. To extend the applicability of A-SeqCNNSLAM to new environments, a method called O-SeqCNNSLAM is established for the online adjustment of the parameters of A-SeqCNNSLAM.
Joint Communication-Motion Planning in Wireless-Connected Robotic Networks: Overview and Design Guidelines
Nov 07, 2015
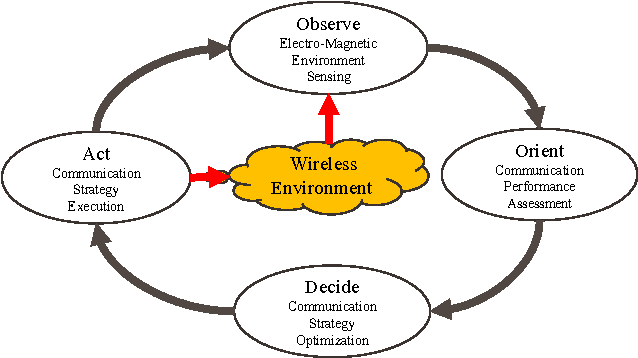
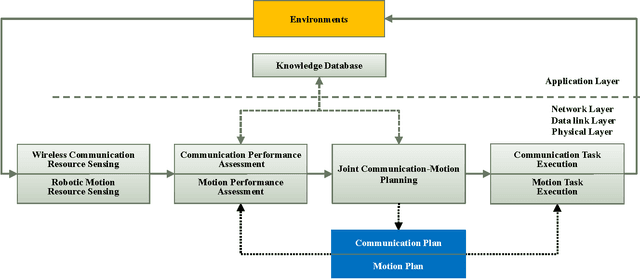
Recent years have witnessed the prosperity of robots and in order to support consensus and cooperation for multi-robot system, wireless communications and networking among robots and the infrastructure have become indispensable. In this technical note, we first provide an overview of the research contributions on communication-aware motion planning (CAMP) in designing wireless-connected robotic networks (WCRNs), where the degree-of-freedom (DoF) provided by motion and communication capabilities embraced by the robots have not been fully exploited. Therefore, we propose the framework of joint communication-motion planning (JCMP) as well as the architecture for incorporating JCMP in WCRNs. The proposed architecture is motivated by the observe-orient-decision-action (OODA) model commonly adopted in robotic motion control and cognitive radio. Then, we provide an overview of the orient module that quantify the connectivity assessment. Afterwards, we highlight the JCMP module and compare it with the conventional communication-planning, where the necessity of the JCMP is validated via both theoretical analysis and simulation results of an illustrative example. Finally, a series of open problems are discussed, which picture the gap between the state-of-the-art and a practical WCRN.