 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Aug 26, 2025



While Mixture of Experts (MoE) models achieve remarkable efficiency by activating only subsets of parameters, they suffer from high memory access costs during inference. Memory-layer architectures offer an appealing alternative with very few memory access, but previous attempts like UltraMem have only matched the performance of 2-expert MoE models, falling significantly short of state-of-the-art 8-expert configurations. We present UltraMemV2, a redesigned memory-layer architecture that closes this performance gap. Our approach introduces five key improvements: integrating memory layers into every transformer block, simplifying value expansion with single linear projections, adopting FFN-based value processing from PEER, implementing principled parameter initialization, and rebalancing memory-to-FFN computation ratios. Through extensive evaluation, we demonstrate that UltraMemV2 achieves performance parity with 8-expert MoE models under same computation and parameters but significantly low memory access. Notably, UltraMemV2 shows superior performance on memory-intensive tasks, with improvements of +1.6 points on long-context memorization, +6.2 points on multi-round memorization, and +7.9 points on in-context learning. We validate our approach at scale with models up to 2.5B activated parameters from 120B total parameters, and establish that activation density has greater impact on performance than total sparse parameter count. Our work brings memory-layer architectures to performance parity with state-of-the-art MoE models, presenting a compelling alternative for efficient sparse computation.
Ultra-Sparse Memory Network
Nov 19, 2024



It is widely acknowledged that the performance of Transformer models is exponentially related to their number of parameters and computational complexity. While approaches like Mixture of Experts (MoE) decouple parameter count from computational complexity, they still face challenges in inference due to high memory access costs. This work introduces UltraMem, incorporating large-scale, ultra-sparse memory layer to address these limitations. Our approach significantly reduces inference latency while maintaining model performance. We also investigate the scaling laws of this new architecture, demonstrating that it not only exhibits favorable scaling properties but outperforms traditional models. In our experiments, we train networks with up to 20 million memory slots. The results show that our method achieves state-of-the-art inference speed and model performance within a given computational budget.
OneFlow: Redesign the Distributed Deep Learning Framework from Scratch
Oct 29, 2021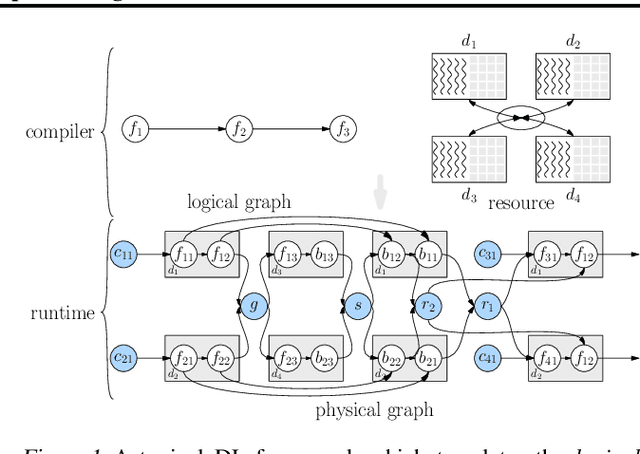
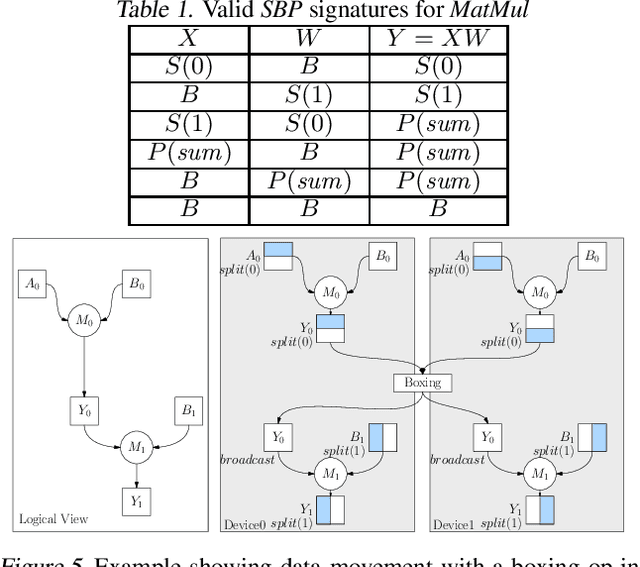
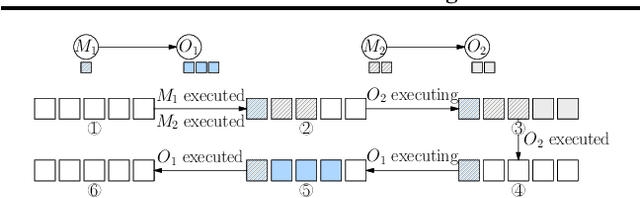

Deep learning frameworks such as TensorFlow and PyTorch provide a productive interface for expressing and training a deep neural network (DNN) model on a single device or using data parallelism. Still, they may not be flexible or efficient enough in training emerging large models on distributed devices, which require more sophisticated parallelism beyond data parallelism. Plugins or wrappers have been developed to strengthen these frameworks for model or pipeline parallelism, but they complicate the usage and implementation of distributed deep learning. Aiming at a simple, neat redesign of distributed deep learning frameworks for various parallelism paradigms, we present OneFlow, a novel distributed training framework based on an SBP (split, broadcast and partial-value) abstraction and the actor model. SBP enables much easier programming of data parallelism and model parallelism than existing frameworks, and the actor model provides a succinct runtime mechanism to manage the complex dependencies imposed by resource constraints, data movement and computation in distributed deep learning. We demonstrate the general applicability and efficiency of OneFlow for training various large DNN models with case studies and extensive experiments. The results show that OneFlow outperforms many well-known customized libraries built on top of the state-of-the-art frameworks. The code of OneFlow is available at: https://github.com/Oneflow-Inc/oneflow.