 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassNet: Scaling Large Language Models for Graph Compiler Pass Generation
May 28, 2026Modern tensor compilers such as TorchInductor deliver substantial speedups on mainstream models, yet face a systematic performance ceiling on long-tail workloads -- our profiling shows that 43% of real-world subgraphs experience end-to-end slowdowns under default compilation. While LLMs offer a path toward automated optimization, existing efforts focus on standalone kernel generation. We argue that pass generation -- where LLMs author structured graph transformations that integrate directly into compiler pipelines -- is the more appropriate abstraction. We propose PassNet, the first large-scale ecosystem for LLM-based compiler pass generation, comprising: (1) PassNet-Dataset, over 18K unique computational graphs from 100K real-world models; and (2) PassBench, 200 curated long-tail fusible tasks (comprising 2,060 subgraphs in total) evaluated under the Error-aware Speedup Score (ES_t) -- a metric unifying correctness, stability, and performance -- with layered integrity defenses against systematic LLM exploitation. Experiments reveal that PassBench is both highly discriminative and genuinely unsaturated: the best frontier model trails TorchInductor by 37% in aggregate, yet on individual subgraphs LLMs achieve up to 3x speedup over the same compiler -- indicating that the bottleneck is consistency, not capability. Fine-tuning a small model on merely ~4K PassNet trajectories yields a 2.67x improvement approaching frontier-model performance, demonstrating substantial headroom and validating PassNet as live training infrastructure for advancing LLM-driven compiler optimization. All data, benchmarks, and tooling are publicly available.
BCER Agent: Reliable Long-Horizon MRI Workflow Execution via Compilation, Artifact Binding, and Bounded Local Recovery
May 27, 2026Many recent medical VLM and agent studies are benchmarked on 2D images or comparatively short tool-calling exchanges, whereas real MRI analysis typically demands long, interdependent pipelines that operate on 3D/4D volumetric data. Under these conditions, reactive tool-calling agents are prone to cascading breakdowns triggered by faulty intermediate references, mismatched tool arguments, and limited control over cross-step dependencies. To address this, we introduce BCER (Brain-Cerebellum-Extremity-Reflector), a controller architecture aimed at dependable long-horizon MRI workflow execution. BCER decouples high-level planning from execution and provides bounded local recovery. We assess BCER on a multi-organ MRI benchmark covering brain, prostate, and cardiac tasks with both short- and long-chain workflows, using matched task contracts across controller variants and several backbone models. Relative to reactive baselines, BCER yields consistent improvements in end-to-end execution, with the most pronounced gains observed on long-chain workflows. BCER additionally enables auditability by maintaining explicit links between final outputs and intermediate artifacts and measurements. Code and benchmark are released at https://github.com/Albertlongzi/BCER.
Beyond Static Artifacts: A Forensic Benchmark for Video Deepfake Reasoning in Vision Language Models
Feb 25, 2026Current Vision-Language Models (VLMs) for deepfake detection excel at identifying spatial artifacts but overlook a critical dimension: temporal inconsistencies in video forgeries. Adapting VLMs to reason about these dynamic cues remains a distinct challenge. To bridge this gap, we propose Forensic Answer-Questioning (FAQ), a large-scale benchmark that formulates temporal deepfake analysis as a multiple-choice task. FAQ introduces a three-level hierarchy to progressively evaluate and equip VLMs with forensic capabilities: (1) Facial Perception, testing the ability to identify static visual artifacts; (2) Temporal Deepfake Grounding, requiring the localization of dynamic forgery artifacts across frames; and (3) Forensic Reasoning, challenging models to synthesize evidence for final authenticity verdicts. We evaluate a range of VLMs on FAQ and generate a corresponding instruction-tuning set, FAQ-IT. Extensive experiments show that models fine-tuned on FAQ-IT achieve advanced performance on both in-domain and cross-dataset detection benchmarks. Ablation studies further validate the impact of our key design choices, confirming that FAQ is the driving force behind the temporal reasoning capabilities of these VLMs.
Groupwise Registration with Physics-Informed Test-Time Adaptation on Multi-parametric Cardiac MRI
Oct 29, 2025Multiparametric mapping MRI has become a viable tool for myocardial tissue characterization. However, misalignment between multiparametric maps makes pixel-wise analysis challenging. To address this challenge, we developed a generalizable physics-informed deep-learning model using test-time adaptation to enable group image registration across contrast weighted images acquired from multiple physical models (e.g., a T1 mapping model and T2 mapping model). The physics-informed adaptation utilized the synthetic images from specific physics model as registration reference, allows for transductive learning for various tissue contrast. We validated the model in healthy volunteers with various MRI sequences, demonstrating its improvement for multi-modal registration with a wide range of image contrast variability.
Contrast-Agnostic Groupwise Registration by Robust PCA for Quantitative Cardiac MRI
Nov 03, 2023



Quantitative cardiac magnetic resonance imaging (MRI) is an increasingly important diagnostic tool for cardiovascular diseases. Yet, co-registration of all baseline images within the quantitative MRI sequence is essential for the accuracy and precision of quantitative maps. However, co-registering all baseline images from a quantitative cardiac MRI sequence remains a nontrivial task because of the simultaneous changes in intensity and contrast, in combination with cardiac and respiratory motion. To address the challenge, we propose a novel motion correction framework based on robust principle component analysis (rPCA) that decomposes quantitative cardiac MRI into low-rank and sparse components, and we integrate the groupwise CNN-based registration backbone within the rPCA framework. The low-rank component of rPCA corresponds to the quantitative mapping (i.e. limited degree of freedom in variation), while the sparse component corresponds to the residual motion, making it easier to formulate and solve the groupwise registration problem. We evaluated our proposed method on cardiac T1 mapping by the modified Look-Locker inversion recovery (MOLLI) sequence, both before and after the Gadolinium contrast agent administration. Our experiments showed that our method effectively improved registration performance over baseline methods without introducing rPCA, and reduced quantitative mapping error in both in-domain (pre-contrast MOLLI) and out-of-domain (post-contrast MOLLI) inference. The proposed rPCA framework is generic and can be integrated with other registration backbones.
OneFlow: Redesign the Distributed Deep Learning Framework from Scratch
Oct 29, 2021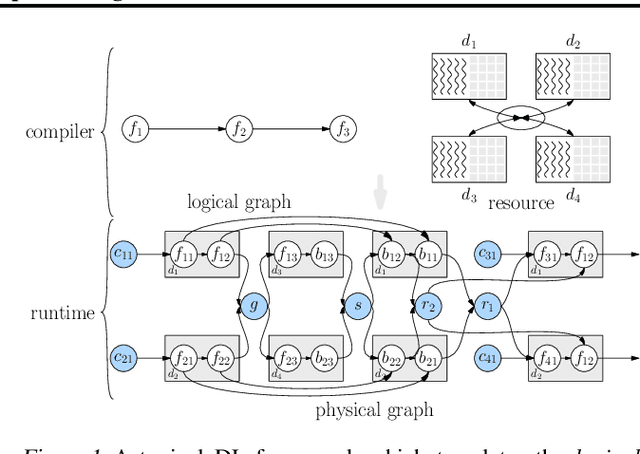
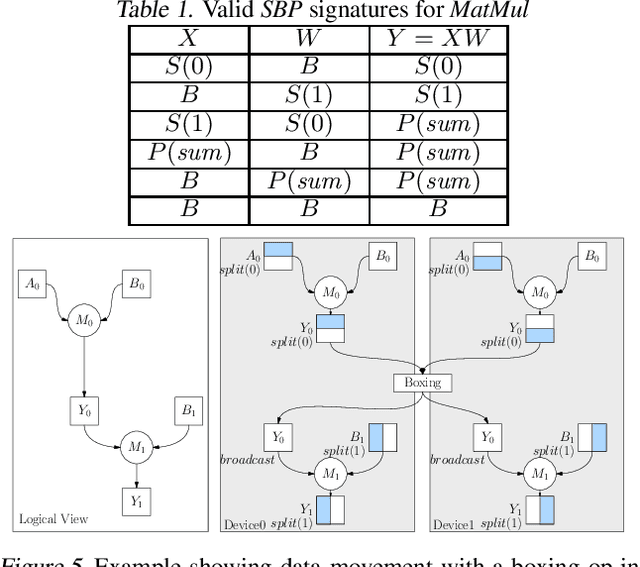
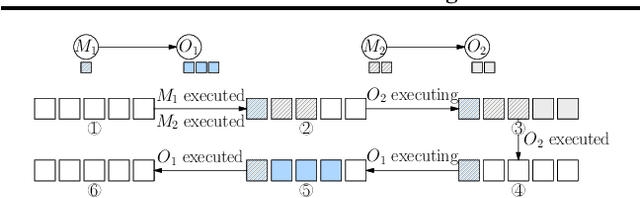

Deep learning frameworks such as TensorFlow and PyTorch provide a productive interface for expressing and training a deep neural network (DNN) model on a single device or using data parallelism. Still, they may not be flexible or efficient enough in training emerging large models on distributed devices, which require more sophisticated parallelism beyond data parallelism. Plugins or wrappers have been developed to strengthen these frameworks for model or pipeline parallelism, but they complicate the usage and implementation of distributed deep learning. Aiming at a simple, neat redesign of distributed deep learning frameworks for various parallelism paradigms, we present OneFlow, a novel distributed training framework based on an SBP (split, broadcast and partial-value) abstraction and the actor model. SBP enables much easier programming of data parallelism and model parallelism than existing frameworks, and the actor model provides a succinct runtime mechanism to manage the complex dependencies imposed by resource constraints, data movement and computation in distributed deep learning. We demonstrate the general applicability and efficiency of OneFlow for training various large DNN models with case studies and extensive experiments. The results show that OneFlow outperforms many well-known customized libraries built on top of the state-of-the-art frameworks. The code of OneFlow is available at: https://github.com/Oneflow-Inc/oneflow.
Zero-Shot Fine-Grained Classification by Deep Feature Learning with Semantics
Jul 04, 2017
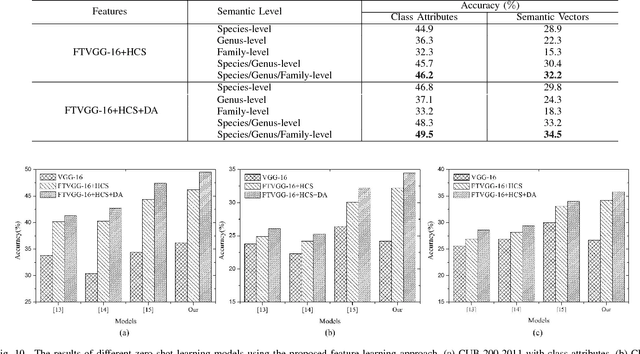
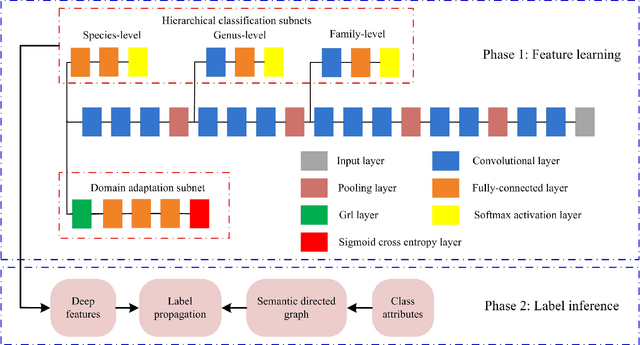
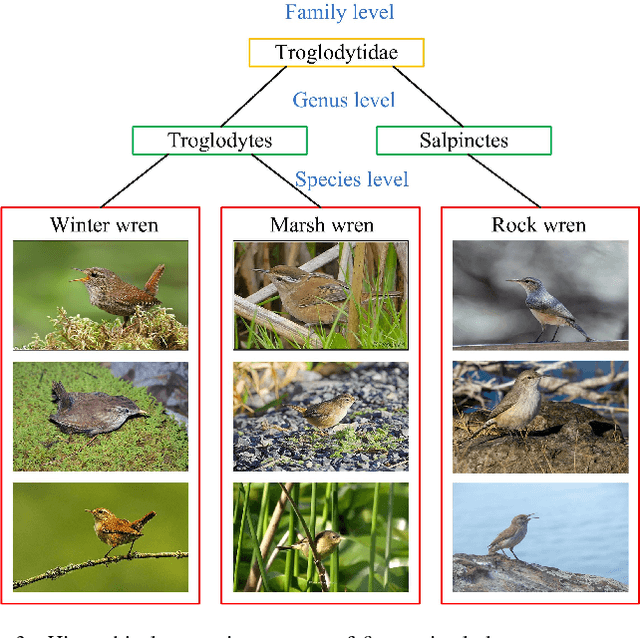
Fine-grained image classification, which aims to distinguish images with subtle distinctions, is a challenging task due to two main issues: lack of sufficient training data for every class and difficulty in learning discriminative features for representation. In this paper, to address the two issues, we propose a two-phase framework for recognizing images from unseen fine-grained classes, i.e. zero-shot fine-grained classification. In the first feature learning phase, we finetune deep convolutional neural networks using hierarchical semantic structure among fine-grained classes to extract discriminative deep visual features. Meanwhile, a domain adaptation structure is induced into deep convolutional neural networks to avoid domain shift from training data to test data. In the second label inference phase, a semantic directed graph is constructed over attributes of fine-grained classes. Based on this graph, we develop a label propagation algorithm to infer the labels of images in the unseen classes. Experimental results on two benchmark datasets demonstrate that our model outperforms the state-of-the-art zero-shot learning models. In addition, the features obtained by our feature learning model also yield significant gains when they are used by other zero-shot learning models, which shows the flexility of our model in zero-shot fine-grained classification.