 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-AGILE: A Software Agent Framework for Efficiently Managing Dynamic Reasoning Context
Apr 13, 2026Prior representative ReAct-style approaches in autonomous Software Engineering (SWE) typically lack the explicit System-2 reasoning required for deep analysis and handling complex edge cases. While recent reasoning models demonstrate the potential of extended Chain-of-Thought (CoT), applying them to the multi-turn SWE task creates a fundamental dilemma: retaining full reasoning history leads to context explosion and ``Lost-in-the-Middle'' degradation, while discarding it would force the agent to redundantly re-reason at every step. To address these challenges, we propose SWE-AGILE, a novel software agent framework designed to bridge the gap between reasoning depth, efficiency, and context constraints. SWE-AGILE introduces a Dynamic Reasoning Context strategy, maintaining a ``sliding window'' of detailed reasoning for immediate continuity to prevent redundant re-analyzing, while compressing historical reasoning content into concise Reasoning Digests. Empirically, SWE-AGILE sets a new standard for 7B-8B models on SWE-Bench-Verified using only 2.2k trajectories and 896 tasks. Code is available at https://github.com/KDEGroup/SWE-AGILE.
GENSR: Symbolic Regression Based in Equation Generative Space
Feb 24, 2026Symbolic Regression (SR) tries to reveal the hidden equations behind observed data. However, most methods search within a discrete equation space, where the structural modifications of equations rarely align with their numerical behavior, leaving fitting error feedback too noisy to guide exploration. To address this challenge, we propose GenSR, a generative latent space-based SR framework following the `map construction -> coarse localization -> fine search'' paradigm. Specifically, GenSR first pretrains a dual-branch Conditional Variational Autoencoder (CVAE) to reparameterize symbolic equations into a generative latent space with symbolic continuity and local numerical smoothness. This space can be regarded as a well-structured `map'' of the equation space, providing directional signals for search. At inference, the CVAE coarsely localizes the input data to promising regions in the latent space. Then, a modified CMA-ES refines the candidate region, leveraging smooth latent gradients. From a Bayesian perspective, GenSR reframes the SR task as maximizing the conditional distribution $p(\mathrm{Equ.} \mid \mathrm{Num.})$, with CVAE training achieving this objective through the Evidence Lower Bound (ELBO). This new perspective provides a theoretical guarantee for the effectiveness of GenSR. Extensive experiments show that GenSR jointly optimizes predictive accuracy, expression simplicity, and computational efficiency, while remaining robust under noise.
EvoClinician: A Self-Evolving Agent for Multi-Turn Medical Diagnosis via Test-Time Evolutionary Learning
Jan 30, 2026Prevailing medical AI operates on an unrealistic ''one-shot'' model, diagnosing from a complete patient file. However, real-world diagnosis is an iterative inquiry where Clinicians sequentially ask questions and order tests to strategically gather information while managing cost and time. To address this, we first propose Med-Inquire, a new benchmark designed to evaluate an agent's ability to perform multi-turn diagnosis. Built upon a dataset of real-world clinical cases, Med-Inquire simulates the diagnostic process by hiding a complete patient file behind specialized Patient and Examination agents. They force the agent to proactively ask questions and order tests to gather information piece by piece. To tackle the challenges posed by Med-Inquire, we then introduce EvoClinician, a self-evolving agent that learns efficient diagnostic strategies at test time. Its core is a ''Diagnose-Grade-Evolve'' loop: an Actor agent attempts a diagnosis; a Process Grader agent performs credit assignment by evaluating each action for both clinical yield and resource efficiency; finally, an Evolver agent uses this feedback to update the Actor's strategy by evolving its prompt and memory. Our experiments show EvoClinician outperforms continual learning baselines and other self-evolving agents like memory agents. The code is available at https://github.com/yf-he/EvoClinician
Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
Jan 15, 2026Multi-agent systems have evolved into practical LLM-driven collaborators for many applications, gaining robustness from diversity and cross-checking. However, multi-agent RL (MARL) training is resource-intensive and unstable: co-adapting teammates induce non-stationarity, and rewards are often sparse and high-variance. Therefore, we introduce \textbf{Multi-Agent Test-Time Reinforcement Learning (MATTRL)}, a framework that injects structured textual experience into multi-agent deliberation at inference time. MATTRL forms a multi-expert team of specialists for multi-turn discussions, retrieves and integrates test-time experiences, and reaches consensus for final decision-making. We also study credit assignment for constructing a turn-level experience pool, then reinjecting it into the dialogue. Across challenging benchmarks in medicine, math, and education, MATTRL improves accuracy by an average of 3.67\% over a multi-agent baseline, and by 8.67\% over comparable single-agent baselines. Ablation studies examine different credit-assignment schemes and provide a detailed comparison of how they affect training outcomes. MATTRL offers a stable, effective and efficient path to distribution-shift-robust multi-agent reasoning without tuning.
Moirai 2.0: When Less Is More for Time Series Forecasting
Nov 12, 2025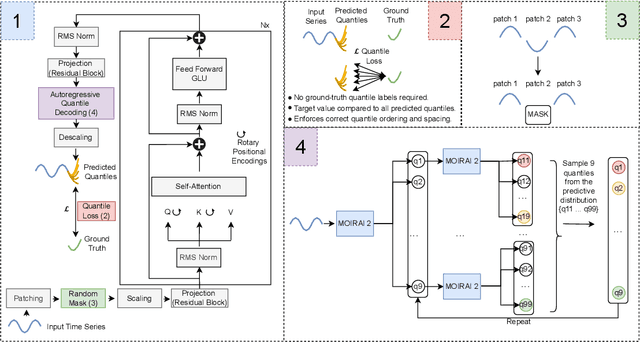

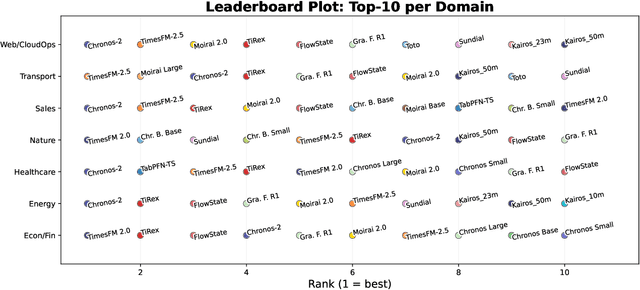
We introduce Moirai 2.0, a decoder-only time-series foundation model trained on a new corpus of 36M series. The model adopts quantile forecasting and multi-token prediction, improving both probabilistic accuracy and inference efficiency. On the Gift-Eval benchmark, it ranks among the top pretrained models while achieving a strong trade-off between accuracy, speed, and model size. Compared to Moirai 1.0, Moirai 2.0 replaces masked-encoder training, multi-patch inputs, and mixture-distribution outputs with a simpler decoder-only architecture, single patch, and quantile loss. Ablation studies isolate these changes -- showing that the decoder-only backbone along with recursive multi-quantile decoding contribute most to the gains. Additional experiments show that Moirai 2.0 outperforms larger models from the same family and exhibits robust domain-level results. In terms of efficiency and model size, Moirai 2.0 is twice as fast and thirty times smaller than its prior best version, Moirai 1.0-Large, while also performing better. Model performance plateaus with increasing parameter count and declines at longer horizons, motivating future work on data scaling and long-horizon modeling. We release code and evaluation details to support further research.
Serving Large Language Models on Huawei CloudMatrix384
Jun 15, 2025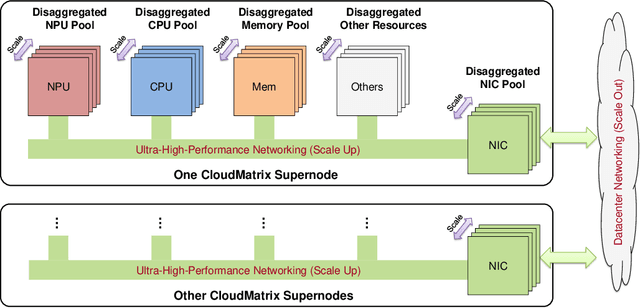
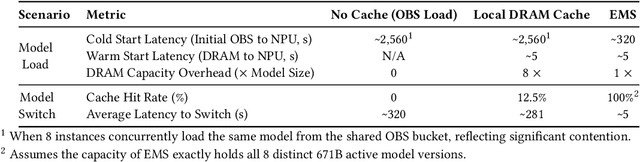
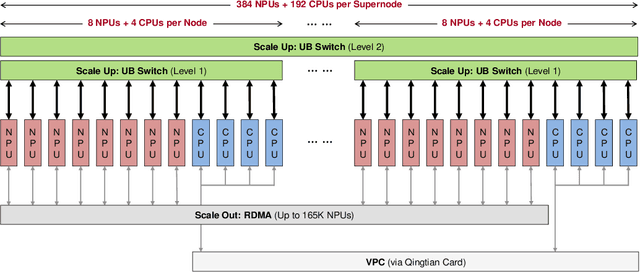
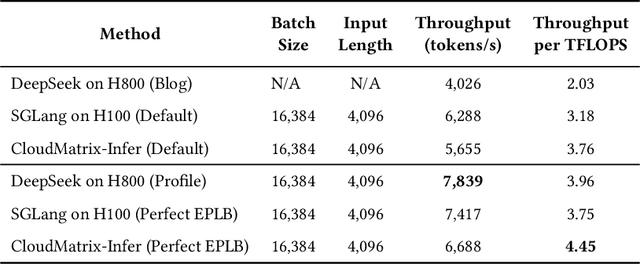
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
Empowering Time Series Analysis with Synthetic Data: A Survey and Outlook in the Era of Foundation Models
Mar 14, 2025



Time series analysis is crucial for understanding dynamics of complex systems. Recent advances in foundation models have led to task-agnostic Time Series Foundation Models (TSFMs) and Large Language Model-based Time Series Models (TSLLMs), enabling generalized learning and integrating contextual information. However, their success depends on large, diverse, and high-quality datasets, which are challenging to build due to regulatory, diversity, quality, and quantity constraints. Synthetic data emerge as a viable solution, addressing these challenges by offering scalable, unbiased, and high-quality alternatives. This survey provides a comprehensive review of synthetic data for TSFMs and TSLLMs, analyzing data generation strategies, their role in model pretraining, fine-tuning, and evaluation, and identifying future research directions.
GIFT-Eval: A Benchmark For General Time Series Forecasting Model Evaluation
Oct 14, 2024



Time series foundation models excel in zero-shot forecasting, handling diverse tasks without explicit training. However, the advancement of these models has been hindered by the lack of comprehensive benchmarks. To address this gap, we introduce the General Time Series Forecasting Model Evaluation, GIFT-Eval, a pioneering benchmark aimed at promoting evaluation across diverse datasets. GIFT-Eval encompasses 28 datasets over 144,000 time series and 177 million data points, spanning seven domains, 10 frequencies, multivariate inputs, and prediction lengths ranging from short to long-term forecasts. To facilitate the effective pretraining and evaluation of foundation models, we also provide a non-leaking pretraining dataset containing approximately 230 billion data points. Additionally, we provide a comprehensive analysis of 17 baselines, which includes statistical models, deep learning models, and foundation models. We discuss each model in the context of various benchmark characteristics and offer a qualitative analysis that spans both deep learning and foundation models. We believe the insights from this analysis, along with access to this new standard zero-shot time series forecasting benchmark, will guide future developments in time series foundation models. The codebase, datasets, and a leaderboard showing all the results in detail will be available soon.
Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts
Oct 14, 2024



Time series foundation models have demonstrated impressive performance as zero-shot forecasters. However, achieving effectively unified training on time series remains an open challenge. Existing approaches introduce some level of model specialization to account for the highly heterogeneous nature of time series data. For instance, Moirai pursues unified training by employing multiple input/output projection layers, each tailored to handle time series at a specific frequency. Similarly, TimesFM maintains a frequency embedding dictionary for this purpose. We identify two major drawbacks to this human-imposed frequency-level model specialization: (1) Frequency is not a reliable indicator of the underlying patterns in time series. For example, time series with different frequencies can display similar patterns, while those with the same frequency may exhibit varied patterns. (2) Non-stationarity is an inherent property of real-world time series, leading to varied distributions even within a short context window of a single time series. Frequency-level specialization is too coarse-grained to capture this level of diversity. To address these limitations, this paper introduces Moirai-MoE, using a single input/output projection layer while delegating the modeling of diverse time series patterns to the sparse mixture of experts (MoE) within Transformers. With these designs, Moirai-MoE reduces reliance on human-defined heuristics and enables automatic token-level specialization. Extensive experiments on 39 datasets demonstrate the superiority of Moirai-MoE over existing foundation models in both in-distribution and zero-shot scenarios. Furthermore, this study conducts comprehensive model analyses to explore the inner workings of time series MoE foundation models and provides valuable insights for future research.
UniTST: Effectively Modeling Inter-Series and Intra-Series Dependencies for Multivariate Time Series Forecasting
Jun 07, 2024



Transformer-based models have emerged as powerful tools for multivariate time series forecasting (MTSF). However, existing Transformer models often fall short of capturing both intricate dependencies across variate and temporal dimensions in MTS data. Some recent models are proposed to separately capture variate and temporal dependencies through either two sequential or parallel attention mechanisms. However, these methods cannot directly and explicitly learn the intricate inter-series and intra-series dependencies. In this work, we first demonstrate that these dependencies are very important as they usually exist in real-world data. To directly model these dependencies, we propose a transformer-based model UniTST containing a unified attention mechanism on the flattened patch tokens. Additionally, we add a dispatcher module which reduces the complexity and makes the model feasible for a potentially large number of variates. Although our proposed model employs a simple architecture, it offers compelling performance as shown in our extensive experiments on several datasets for time series forecasting.