 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGHINT: Attribute-Guided Representation Learning on Heterogeneous Information Networks with Transformer
Apr 16, 2024Recently, heterogeneous graph neural networks (HGNNs) have achieved impressive success in representation learning by capturing long-range dependencies and heterogeneity at the node level. However, few existing studies have delved into the utilization of node attributes in heterogeneous information networks (HINs). In this paper, we investigate the impact of inter-node attribute disparities on HGNNs performance within the benchmark task, i.e., node classification, and empirically find that typical models exhibit significant performance decline when classifying nodes whose attributes markedly differ from their neighbors. To alleviate this issue, we propose a novel Attribute-Guided heterogeneous Information Networks representation learning model with Transformer (AGHINT), which allows a more effective aggregation of neighbor node information under the guidance of attributes. Specifically, AGHINT transcends the constraints of the original graph structure by directly integrating higher-order similar neighbor features into the learning process and modifies the message-passing mechanism between nodes based on their attribute disparities. Extensive experimental results on three real-world heterogeneous graph benchmarks with target node attributes demonstrate that AGHINT outperforms the state-of-the-art.
Coop: Memory is not a Commodity
Nov 01, 2023


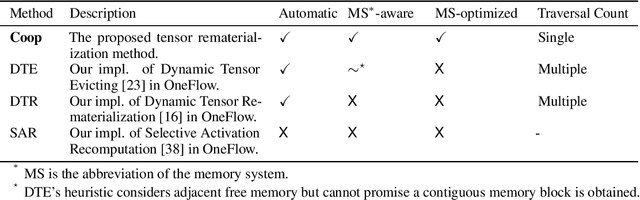
Tensor rematerialization allows the training of deep neural networks (DNNs) under limited memory budgets by checkpointing the models and recomputing the evicted tensors as needed. However, the existing tensor rematerialization techniques overlook the memory system in deep learning frameworks and implicitly assume that free memory blocks at different addresses are identical. Under this flawed assumption, discontiguous tensors are evicted, among which some are not used to allocate the new tensor. This leads to severe memory fragmentation and increases the cost of potential rematerializations. To address this issue, we propose to evict tensors within a sliding window to ensure all evictions are contiguous and are immediately used. Furthermore, we proposed cheap tensor partitioning and recomputable in-place to further reduce the rematerialization cost by optimizing the tensor allocation. We named our method Coop as it is a co-optimization of tensor allocation and tensor rematerialization. We evaluated Coop on eight representative DNNs. The experimental results demonstrate that Coop achieves up to $2\times$ memory saving and hugely reduces compute overhead, search latency, and memory fragmentation compared to the state-of-the-art baselines.
OneFlow: Redesign the Distributed Deep Learning Framework from Scratch
Oct 29, 2021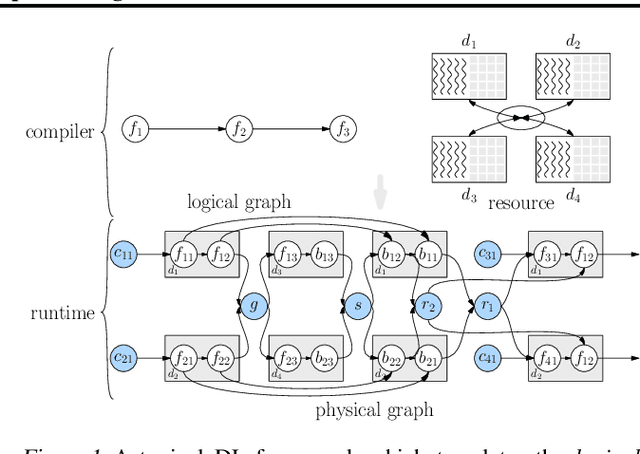
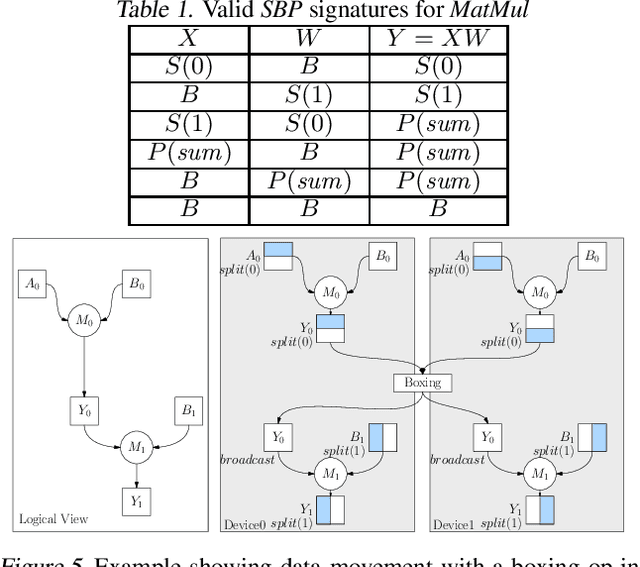
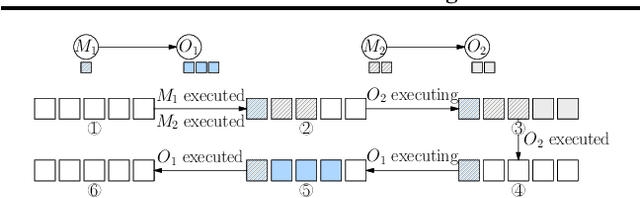

Deep learning frameworks such as TensorFlow and PyTorch provide a productive interface for expressing and training a deep neural network (DNN) model on a single device or using data parallelism. Still, they may not be flexible or efficient enough in training emerging large models on distributed devices, which require more sophisticated parallelism beyond data parallelism. Plugins or wrappers have been developed to strengthen these frameworks for model or pipeline parallelism, but they complicate the usage and implementation of distributed deep learning. Aiming at a simple, neat redesign of distributed deep learning frameworks for various parallelism paradigms, we present OneFlow, a novel distributed training framework based on an SBP (split, broadcast and partial-value) abstraction and the actor model. SBP enables much easier programming of data parallelism and model parallelism than existing frameworks, and the actor model provides a succinct runtime mechanism to manage the complex dependencies imposed by resource constraints, data movement and computation in distributed deep learning. We demonstrate the general applicability and efficiency of OneFlow for training various large DNN models with case studies and extensive experiments. The results show that OneFlow outperforms many well-known customized libraries built on top of the state-of-the-art frameworks. The code of OneFlow is available at: https://github.com/Oneflow-Inc/oneflow.
Pre-Trained Models: Past, Present and Future
Jun 15, 2021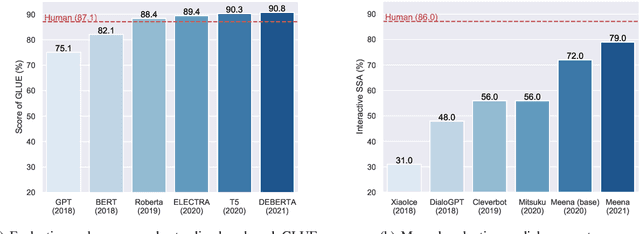
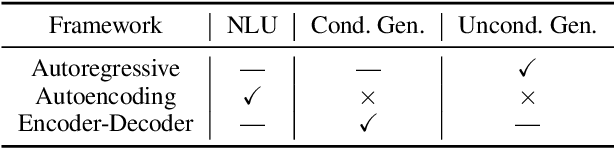
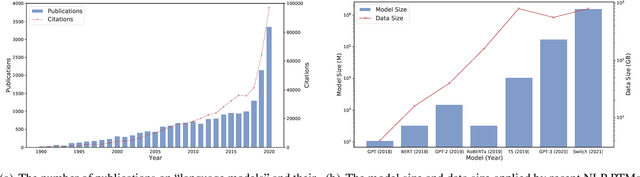
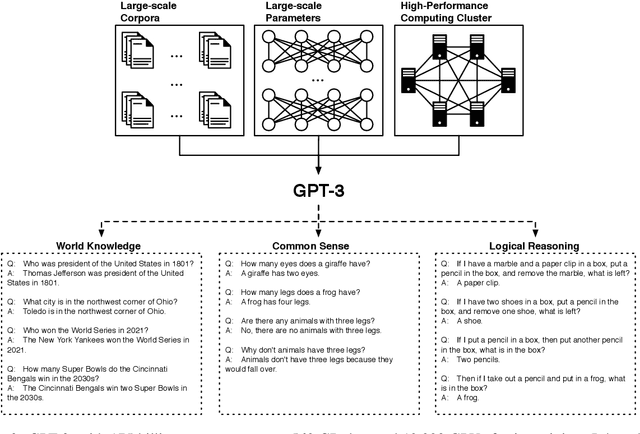
Large-scale pre-trained models (PTMs) such as BERT and GPT have recently achieved great success and become a milestone in the field of artificial intelligence (AI). Owing to sophisticated pre-training objectives and huge model parameters, large-scale PTMs can effectively capture knowledge from massive labeled and unlabeled data. By storing knowledge into huge parameters and fine-tuning on specific tasks, the rich knowledge implicitly encoded in huge parameters can benefit a variety of downstream tasks, which has been extensively demonstrated via experimental verification and empirical analysis. It is now the consensus of the AI community to adopt PTMs as backbone for downstream tasks rather than learning models from scratch. In this paper, we take a deep look into the history of pre-training, especially its special relation with transfer learning and self-supervised learning, to reveal the crucial position of PTMs in the AI development spectrum. Further, we comprehensively review the latest breakthroughs of PTMs. These breakthroughs are driven by the surge of computational power and the increasing availability of data, towards four important directions: designing effective architectures, utilizing rich contexts, improving computational efficiency, and conducting interpretation and theoretical analysis. Finally, we discuss a series of open problems and research directions of PTMs, and hope our view can inspire and advance the future study of PTMs.
Learning Structures for Deep Neural Networks
May 27, 2021
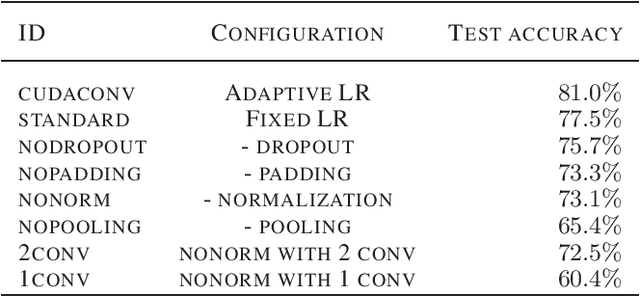


In this paper, we focus on the unsupervised setting for structure learning of deep neural networks and propose to adopt the efficient coding principle, rooted in information theory and developed in computational neuroscience, to guide the procedure of structure learning without label information. This principle suggests that a good network structure should maximize the mutual information between inputs and outputs, or equivalently maximize the entropy of outputs under mild assumptions. We further establish connections between this principle and the theory of Bayesian optimal classification, and empirically verify that larger entropy of the outputs of a deep neural network indeed corresponds to a better classification accuracy. Then as an implementation of the principle, we show that sparse coding can effectively maximize the entropy of the output signals, and accordingly design an algorithm based on global group sparse coding to automatically learn the inter-layer connection and determine the depth of a neural network. Our experiments on a public image classification dataset demonstrate that using the structure learned from scratch by our proposed algorithm, one can achieve a classification accuracy comparable to the best expert-designed structure (i.e., convolutional neural networks (CNN)). In addition, our proposed algorithm successfully discovers the local connectivity (corresponding to local receptive fields in CNN) and invariance structure (corresponding to pulling in CNN), as well as achieves a good tradeoff between marginal performance gain and network depth.
LightLDA: Big Topic Models on Modest Compute Clusters
Dec 04, 2014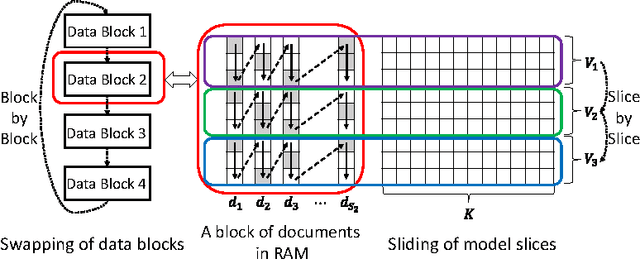

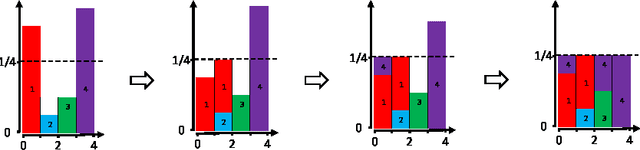
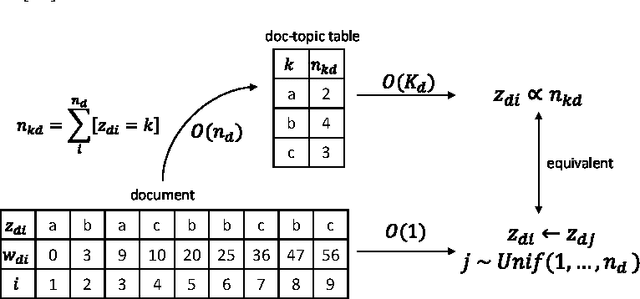
When building large-scale machine learning (ML) programs, such as big topic models or deep neural nets, one usually assumes such tasks can only be attempted with industrial-sized clusters with thousands of nodes, which are out of reach for most practitioners or academic researchers. We consider this challenge in the context of topic modeling on web-scale corpora, and show that with a modest cluster of as few as 8 machines, we can train a topic model with 1 million topics and a 1-million-word vocabulary (for a total of 1 trillion parameters), on a document collection with 200 billion tokens -- a scale not yet reported even with thousands of machines. Our major contributions include: 1) a new, highly efficient O(1) Metropolis-Hastings sampling algorithm, whose running cost is (surprisingly) agnostic of model size, and empirically converges nearly an order of magnitude faster than current state-of-the-art Gibbs samplers; 2) a structure-aware model-parallel scheme, which leverages dependencies within the topic model, yielding a sampling strategy that is frugal on machine memory and network communication; 3) a differential data-structure for model storage, which uses separate data structures for high- and low-frequency words to allow extremely large models to fit in memory, while maintaining high inference speed; and 4) a bounded asynchronous data-parallel scheme, which allows efficient distributed processing of massive data via a parameter server. Our distribution strategy is an instance of the model-and-data-parallel programming model underlying the Petuum framework for general distributed ML, and was implemented on top of the Petuum open-source system. We provide experimental evidence showing how this development puts massive models within reach on a small cluster while still enjoying proportional time cost reductions with increasing cluster size, in comparison with alternative options.