 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Need a More Robust Classifier: Dual Causal Learning Empowers Domain-Incremental Time Series Classification
Jan 15, 2026The World Wide Web thrives on intelligent services that rely on accurate time series classification, which has recently witnessed significant progress driven by advances in deep learning. However, existing studies face challenges in domain incremental learning. In this paper, we propose a lightweight and robust dual-causal disentanglement framework (DualCD) to enhance the robustness of models under domain incremental scenarios, which can be seamlessly integrated into time series classification models. Specifically, DualCD first introduces a temporal feature disentanglement module to capture class-causal features and spurious features. The causal features can offer sufficient predictive power to support the classifier in domain incremental learning settings. To accurately capture these causal features, we further design a dual-causal intervention mechanism to eliminate the influence of both intra-class and inter-class confounding features. This mechanism constructs variant samples by combining the current class's causal features with intra-class spurious features and with causal features from other classes. The causal intervention loss encourages the model to accurately predict the labels of these variant samples based solely on the causal features. Extensive experiments on multiple datasets and models demonstrate that DualCD effectively improves performance in domain incremental scenarios. We summarize our rich experiments into a comprehensive benchmark to facilitate research in domain incremental time series classification.
CogniSNN: Enabling Neuron-Expandability, Pathway-Reusability, and Dynamic-Configurability with Random Graph Architectures in Spiking Neural Networks
Dec 12, 2025Spiking neural networks (SNNs), regarded as the third generation of artificial neural networks, are expected to bridge the gap between artificial intelligence and computational neuroscience. However, most mainstream SNN research directly adopts the rigid, chain-like hierarchical architecture of traditional artificial neural networks (ANNs), ignoring key structural characteristics of the brain. Biological neurons are stochastically interconnected, forming complex neural pathways that exhibit Neuron-Expandability, Pathway-Reusability, and Dynamic-Configurability. In this paper, we introduce a new SNN paradigm, named Cognition-aware SNN (CogniSNN), by incorporating Random Graph Architecture (RGA). Furthermore, we address the issues of network degradation and dimensional mismatch in deep pathways by introducing an improved pure spiking residual mechanism alongside an adaptive pooling strategy. Then, we design a Key Pathway-based Learning without Forgetting (KP-LwF) approach, which selectively reuses critical neural pathways while retaining historical knowledge, enabling efficient multi-task transfer. Finally, we propose a Dynamic Growth Learning (DGL) algorithm that allows neurons and synapses to grow dynamically along the internal temporal dimension. Extensive experiments demonstrate that CogniSNN achieves performance comparable to, or even surpassing, current state-of-the-art SNNs on neuromorphic datasets and Tiny-ImageNet. The Pathway-Reusability enhances the network's continuous learning capability across different scenarios, while the dynamic growth algorithm improves robustness against interference and mitigates the fixed-timestep constraints during neuromorphic chip deployment. This work demonstrates the potential of SNNs with random graph structures in advancing brain-inspired intelligence and lays the foundation for their practical application on neuromorphic hardware.
EvolveSignal: A Large Language Model Powered Coding Agent for Discovering Traffic Signal Control Algorithms
Sep 04, 2025In traffic engineering, the fixed-time traffic signal control remains widely used for its low cost, stability, and interpretability. However, its design depends on hand-crafted formulas (e.g., Webster) and manual re-timing by engineers to adapt to demand changes, which is labor-intensive and often yields suboptimal results under heterogeneous or congested conditions. This paper introduces the EvolveSignal, a large language models (LLMs) powered coding agent to automatically discover new traffic signal control algorithms. We formulate the problem as program synthesis, where candidate algorithms are represented as Python functions with fixed input-output structures, and iteratively optimized through external evaluations (e.g., a traffic simulator) and evolutionary search. Experiments on a signalized intersection demonstrate that the discovered algorithms outperform Webster's baseline, reducing average delay by 20.1% and average stops by 47.1%. Beyond performance, ablation and incremental analyses reveal that EvolveSignal modifications-such as adjusting cycle length bounds, incorporating right-turn demand, and rescaling green allocations-can offer practically meaningful insights for traffic engineers. This work opens a new research direction by leveraging AI for algorithm design in traffic signal control, bridging program synthesis with transportation engineering.
Reinforcement Learning-based Sequential Route Recommendation for System-Optimal Traffic Assignment
May 27, 2025Modern navigation systems and shared mobility platforms increasingly rely on personalized route recommendations to improve individual travel experience and operational efficiency. However, a key question remains: can such sequential, personalized routing decisions collectively lead to system-optimal (SO) traffic assignment? This paper addresses this question by proposing a learning-based framework that reformulates the static SO traffic assignment problem as a single-agent deep reinforcement learning (RL) task. A central agent sequentially recommends routes to travelers as origin-destination (OD) demands arrive, to minimize total system travel time. To enhance learning efficiency and solution quality, we develop an MSA-guided deep Q-learning algorithm that integrates the iterative structure of traditional traffic assignment methods into the RL training process. The proposed approach is evaluated on both the Braess and Ortuzar-Willumsen (OW) networks. Results show that the RL agent converges to the theoretical SO solution in the Braess network and achieves only a 0.35% deviation in the OW network. Further ablation studies demonstrate that the route action set's design significantly impacts convergence speed and final performance, with SO-informed route sets leading to faster learning and better outcomes. This work provides a theoretically grounded and practically relevant approach to bridging individual routing behavior with system-level efficiency through learning-based sequential assignment.
ILIF: Temporal Inhibitory Leaky Integrate-and-Fire Neuron for Overactivation in Spiking Neural Networks
May 15, 2025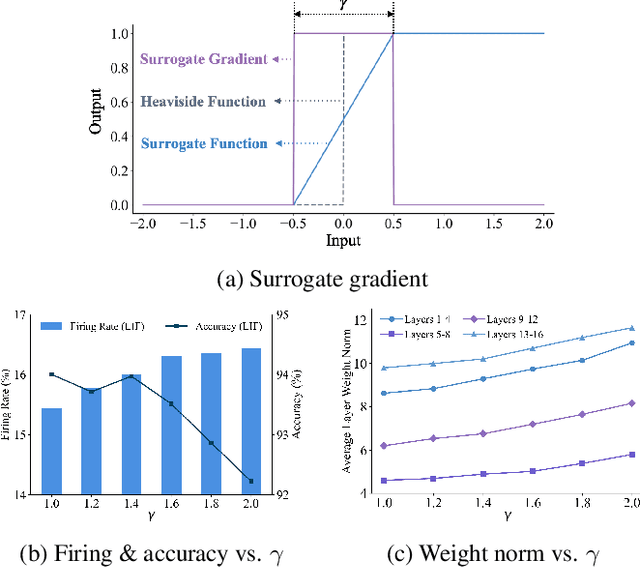
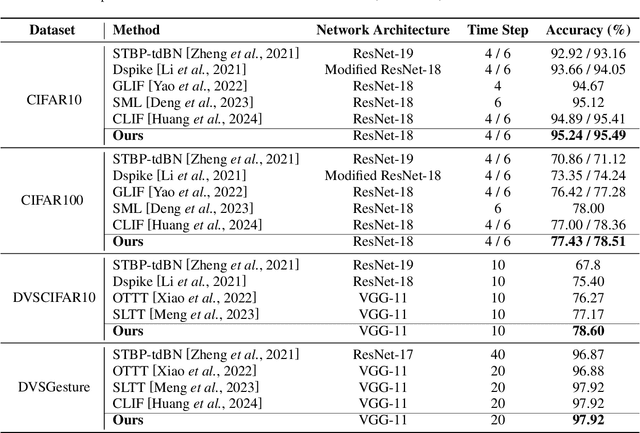

The Spiking Neural Network (SNN) has drawn increasing attention for its energy-efficient, event-driven processing and biological plausibility. To train SNNs via backpropagation, surrogate gradients are used to approximate the non-differentiable spike function, but they only maintain nonzero derivatives within a narrow range of membrane potentials near the firing threshold, referred to as the surrogate gradient support width gamma. We identify a major challenge, termed the dilemma of gamma: a relatively large gamma leads to overactivation, characterized by excessive neuron firing, which in turn increases energy consumption, whereas a small gamma causes vanishing gradients and weakens temporal dependencies. To address this, we propose a temporal Inhibitory Leaky Integrate-and-Fire (ILIF) neuron model, inspired by biological inhibitory mechanisms. This model incorporates interconnected inhibitory units for membrane potential and current, effectively mitigating overactivation while preserving gradient propagation. Theoretical analysis demonstrates ILIF effectiveness in overcoming the gamma dilemma, and extensive experiments on multiple datasets show that ILIF improves energy efficiency by reducing firing rates, stabilizes training, and enhances accuracy. The code is available at github.com/kaisun1/ILIF.
CogniSNN: A First Exploration to Random Graph Architecture based Spiking Neural Networks with Enhanced Expandability and Neuroplasticity
May 09, 2025



Despite advances in spiking neural networks (SNNs) in numerous tasks, their architectures remain highly similar to traditional artificial neural networks (ANNs), restricting their ability to mimic natural connections between biological neurons. This paper develops a new modeling paradigm for SNN with random graph architecture (RGA), termed Cognition-aware SNN (CogniSNN). Furthermore, we improve the expandability and neuroplasticity of CogniSNN by introducing a modified spiking residual neural node (ResNode) to counteract network degradation in deeper graph pathways, as well as a critical path-based algorithm that enables CogniSNN to perform continual learning on new tasks leveraging the features of the data and the RGA learned in the old task. Experiments show that CogniSNN with re-designed ResNode performs outstandingly in neuromorphic datasets with fewer parameters, achieving 95.5% precision in the DVS-Gesture dataset with only 5 timesteps. The critical path-based approach decreases 3% to 5% forgetting while maintaining expected performance in learning new tasks that are similar to or distinct from the old ones. This study showcases the potential of RGA-based SNN and paves a new path for biologically inspired networks based on graph theory.
AI-Driven Day-to-Day Route Choice
Dec 04, 2024



Understanding travelers' route choices can help policymakers devise optimal operational and planning strategies for both normal and abnormal circumstances. However, existing choice modeling methods often rely on predefined assumptions and struggle to capture the dynamic and adaptive nature of travel behavior. Recently, Large Language Models (LLMs) have emerged as a promising alternative, demonstrating remarkable ability to replicate human-like behaviors across various fields. Despite this potential, their capacity to accurately simulate human route choice behavior in transportation contexts remains doubtful. To satisfy this curiosity, this paper investigates the potential of LLMs for route choice modeling by introducing an LLM-empowered agent, "LLMTraveler." This agent integrates an LLM as its core, equipped with a memory system that learns from past experiences and makes decisions by balancing retrieved data and personality traits. The study systematically evaluates the LLMTraveler's ability to replicate human-like decision-making through two stages: (1) analyzing its route-switching behavior in single origin-destination (OD) pair congestion game scenarios, where it demonstrates patterns align with laboratory data but are not fully explained by traditional models, and (2) testing its capacity to model day-to-day (DTD) adaptive learning behaviors on the Ortuzar and Willumsen (OW) network, producing results comparable to Multinomial Logit (MNL) and Reinforcement Learning (RL) models. These experiments demonstrate that the framework can partially replicate human-like decision-making in route choice while providing natural language explanations for its decisions. This capability offers valuable insights for transportation policymaking, such as simulating traveler responses to new policies or changes in the network.
MONICA: Benchmarking on Long-tailed Medical Image Classification
Oct 02, 2024



Long-tailed learning is considered to be an extremely challenging problem in data imbalance learning. It aims to train well-generalized models from a large number of images that follow a long-tailed class distribution. In the medical field, many diagnostic imaging exams such as dermoscopy and chest radiography yield a long-tailed distribution of complex clinical findings. Recently, long-tailed learning in medical image analysis has garnered significant attention. However, the field currently lacks a unified, strictly formulated, and comprehensive benchmark, which often leads to unfair comparisons and inconclusive results. To help the community improve the evaluation and advance, we build a unified, well-structured codebase called Medical OpeN-source Long-taIled ClassifiCAtion (MONICA), which implements over 30 methods developed in relevant fields and evaluated on 12 long-tailed medical datasets covering 6 medical domains. Our work provides valuable practical guidance and insights for the field, offering detailed analysis and discussion on the effectiveness of individual components within the inbuilt state-of-the-art methodologies. We hope this codebase serves as a comprehensive and reproducible benchmark, encouraging further advancements in long-tailed medical image learning. The codebase is publicly available on https://github.com/PyJulie/MONICA.
Diffusion Model Driven Test-Time Image Adaptation for Robust Skin Lesion Classification
May 18, 2024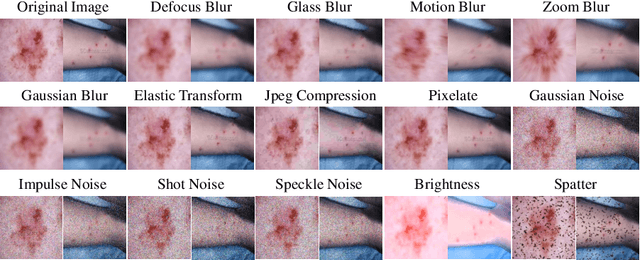

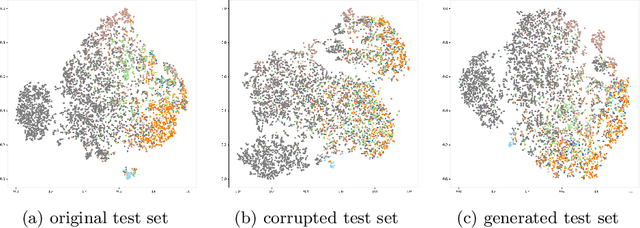

Deep learning-based diagnostic systems have demonstrated potential in skin disease diagnosis. However, their performance can easily degrade on test domains due to distribution shifts caused by input-level corruptions, such as imaging equipment variability, brightness changes, and image blur. This will reduce the reliability of model deployment in real-world scenarios. Most existing solutions focus on adapting the source model through retraining on different target domains. Although effective, this retraining process is sensitive to the amount of data and the hyperparameter configuration for optimization. In this paper, we propose a test-time image adaptation method to enhance the accuracy of the model on test data by simultaneously updating and predicting test images. We modify the target test images by projecting them back to the source domain using a diffusion model. Specifically, we design a structure guidance module that adds refinement operations through low-pass filtering during reverse sampling, regularizing the diffusion to preserve structural information. Additionally, we introduce a self-ensembling scheme automatically adjusts the reliance on adapted and unadapted inputs, enhancing adaptation robustness by rejecting inappropriate generative modeling results. To facilitate this study, we constructed the ISIC2019-C and Dermnet-C corruption robustness evaluation benchmarks. Extensive experiments on the proposed benchmarks demonstrate that our method makes the classifier more robust across various corruptions, architectures, and data regimes. Our datasets and code will be available at \url{https://github.com/minghu0830/Skin-TTA_Diffusion}.
AGHINT: Attribute-Guided Representation Learning on Heterogeneous Information Networks with Transformer
Apr 16, 2024Recently, heterogeneous graph neural networks (HGNNs) have achieved impressive success in representation learning by capturing long-range dependencies and heterogeneity at the node level. However, few existing studies have delved into the utilization of node attributes in heterogeneous information networks (HINs). In this paper, we investigate the impact of inter-node attribute disparities on HGNNs performance within the benchmark task, i.e., node classification, and empirically find that typical models exhibit significant performance decline when classifying nodes whose attributes markedly differ from their neighbors. To alleviate this issue, we propose a novel Attribute-Guided heterogeneous Information Networks representation learning model with Transformer (AGHINT), which allows a more effective aggregation of neighbor node information under the guidance of attributes. Specifically, AGHINT transcends the constraints of the original graph structure by directly integrating higher-order similar neighbor features into the learning process and modifies the message-passing mechanism between nodes based on their attribute disparities. Extensive experimental results on three real-world heterogeneous graph benchmarks with target node attributes demonstrate that AGHINT outperforms the state-of-the-art.