 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeoculomix: Hierarchical Sampling for Retinal-Based Systemic Disease Prediction
Jan 16, 2026Oculomics - the concept of predicting systemic diseases, such as cardiovascular disease and dementia, through retinal imaging - has advanced rapidly due to the data efficiency of transformer-based foundation models like RETFound. Image-level mixed sample data augmentations, such as CutMix and MixUp, are frequently used for training transformers, yet these techniques perturb patient-specific attributes, such as medical comorbidity and clinical factors, since they only account for images and labels. To address this limitation, we propose a hierarchical sampling strategy, Oculomix, for mixed sample augmentations. Our method is based on two clinical priors. First (exam level), images acquired from the same patient at the same time point share the same attributes. Second (patient level), images acquired from the same patient at different time points have a soft temporal trend, as morbidity generally increases over time. Guided by these priors, our method constrains the mixing space to the patient and exam levels to better preserve patient-specific characteristics and leverages their hierarchical relationships. The proposed method is validated using ViT models on a five-year prediction of major adverse cardiovascular events (MACE) in a large ethnically diverse population (Alzeye). We show that Oculomix consistently outperforms image-level CutMix and MixUp by up to 3% in AUROC, demonstrating the necessity and value of the proposed method in oculomics.
Native Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
Benchmarking Real-World Medical Image Classification with Noisy Labels: Challenges, Practice, and Outlook
Dec 10, 2025Learning from noisy labels remains a major challenge in medical image analysis, where annotation demands expert knowledge and substantial inter-observer variability often leads to inconsistent or erroneous labels. Despite extensive research on learning with noisy labels (LNL), the robustness of existing methods in medical imaging has not been systematically assessed. To address this gap, we introduce LNMBench, a comprehensive benchmark for Label Noise in Medical imaging. LNMBench encompasses \textbf{10} representative methods evaluated across 7 datasets, 6 imaging modalities, and 3 noise patterns, establishing a unified and reproducible framework for robustness evaluation under realistic conditions. Comprehensive experiments reveal that the performance of existing LNL methods degrades substantially under high and real-world noise, highlighting the persistent challenges of class imbalance and domain variability in medical data. Motivated by these findings, we further propose a simple yet effective improvement to enhance model robustness under such conditions. The LNMBench codebase is publicly released to facilitate standardized evaluation, promote reproducible research, and provide practical insights for developing noise-resilient algorithms in both research and real-world medical applications.The codebase is publicly available on https://github.com/myyy777/LNMBench.
Generalist versus Specialist Vision Foundation Models for Ocular Disease and Oculomics
Sep 03, 2025Medical foundation models, pre-trained with large-scale clinical data, demonstrate strong performance in diverse clinically relevant applications. RETFound, trained on nearly one million retinal images, exemplifies this approach in applications with retinal images. However, the emergence of increasingly powerful and multifold larger generalist foundation models such as DINOv2 and DINOv3 raises the question of whether domain-specific pre-training remains essential, and if so, what gap persists. To investigate this, we systematically evaluated the adaptability of DINOv2 and DINOv3 in retinal image applications, compared to two specialist RETFound models, RETFound-MAE and RETFound-DINOv2. We assessed performance on ocular disease detection and systemic disease prediction using two adaptation strategies: fine-tuning and linear probing. Data efficiency and adaptation efficiency were further analysed to characterise trade-offs between predictive performance and computational cost. Our results show that although scaling generalist models yields strong adaptability across diverse tasks, RETFound-DINOv2 consistently outperforms these generalist foundation models in ocular-disease detection and oculomics tasks, demonstrating stronger generalisability and data efficiency. These findings suggest that specialist retinal foundation models remain the most effective choice for clinical applications, while the narrowing gap with generalist foundation models suggests that continued data and model scaling can deliver domain-relevant gains and position them as strong foundations for future medical foundation models.
MONICA: Benchmarking on Long-tailed Medical Image Classification
Oct 02, 2024



Long-tailed learning is considered to be an extremely challenging problem in data imbalance learning. It aims to train well-generalized models from a large number of images that follow a long-tailed class distribution. In the medical field, many diagnostic imaging exams such as dermoscopy and chest radiography yield a long-tailed distribution of complex clinical findings. Recently, long-tailed learning in medical image analysis has garnered significant attention. However, the field currently lacks a unified, strictly formulated, and comprehensive benchmark, which often leads to unfair comparisons and inconclusive results. To help the community improve the evaluation and advance, we build a unified, well-structured codebase called Medical OpeN-source Long-taIled ClassifiCAtion (MONICA), which implements over 30 methods developed in relevant fields and evaluated on 12 long-tailed medical datasets covering 6 medical domains. Our work provides valuable practical guidance and insights for the field, offering detailed analysis and discussion on the effectiveness of individual components within the inbuilt state-of-the-art methodologies. We hope this codebase serves as a comprehensive and reproducible benchmark, encouraging further advancements in long-tailed medical image learning. The codebase is publicly available on https://github.com/PyJulie/MONICA.
TP-DRSeg: Improving Diabetic Retinopathy Lesion Segmentation with Explicit Text-Prompts Assisted SAM
Jun 22, 2024



Recent advances in large foundation models, such as the Segment Anything Model (SAM), have demonstrated considerable promise across various tasks. Despite their progress, these models still encounter challenges in specialized medical image analysis, especially in recognizing subtle inter-class differences in Diabetic Retinopathy (DR) lesion segmentation. In this paper, we propose a novel framework that customizes SAM for text-prompted DR lesion segmentation, termed TP-DRSeg. Our core idea involves exploiting language cues to inject medical prior knowledge into the vision-only segmentation network, thereby combining the advantages of different foundation models and enhancing the credibility of segmentation. Specifically, to unleash the potential of vision-language models in the recognition of medical concepts, we propose an explicit prior encoder that transfers implicit medical concepts into explicit prior knowledge, providing explainable clues to excavate low-level features associated with lesions. Furthermore, we design a prior-aligned injector to inject explicit priors into the segmentation process, which can facilitate knowledge sharing across multi-modality features and allow our framework to be trained in a parameter-efficient fashion. Experimental results demonstrate the superiority of our framework over other traditional models and foundation model variants.
Diversified and Personalized Multi-rater Medical Image Segmentation
Mar 20, 2024Annotation ambiguity due to inherent data uncertainties such as blurred boundaries in medical scans and different observer expertise and preferences has become a major obstacle for training deep-learning based medical image segmentation models. To address it, the common practice is to gather multiple annotations from different experts, leading to the setting of multi-rater medical image segmentation. Existing works aim to either merge different annotations into the "groundtruth" that is often unattainable in numerous medical contexts, or generate diverse results, or produce personalized results corresponding to individual expert raters. Here, we bring up a more ambitious goal for multi-rater medical image segmentation, i.e., obtaining both diversified and personalized results. Specifically, we propose a two-stage framework named D-Persona (first Diversification and then Personalization). In Stage I, we exploit multiple given annotations to train a Probabilistic U-Net model, with a bound-constrained loss to improve the prediction diversity. In this way, a common latent space is constructed in Stage I, where different latent codes denote diversified expert opinions. Then, in Stage II, we design multiple attention-based projection heads to adaptively query the corresponding expert prompts from the shared latent space, and then perform the personalized medical image segmentation. We evaluated the proposed model on our in-house Nasopharyngeal Carcinoma dataset and the public lung nodule dataset (i.e., LIDC-IDRI). Extensive experiments demonstrated our D-Persona can provide diversified and personalized results at the same time, achieving new SOTA performance for multi-rater medical image segmentation. Our code will be released at https://github.com/ycwu1997/D-Persona.
Prompt-driven Latent Domain Generalization for Medical Image Classification
Jan 05, 2024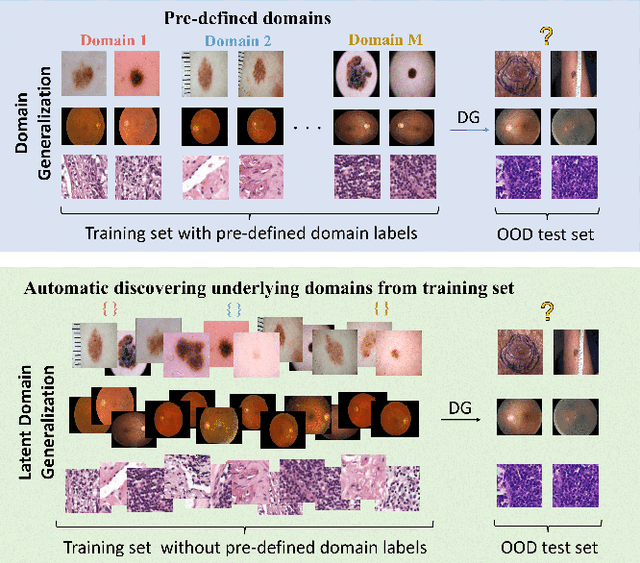
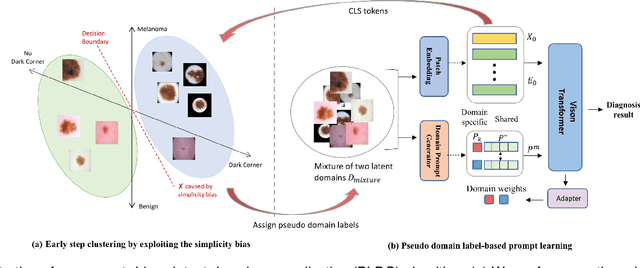
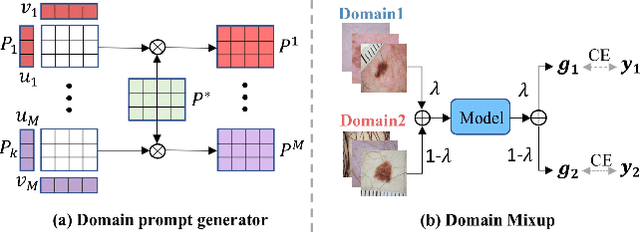

Deep learning models for medical image analysis easily suffer from distribution shifts caused by dataset artifacts bias, camera variations, differences in the imaging station, etc., leading to unreliable diagnoses in real-world clinical settings. Domain generalization (DG) methods, which aim to train models on multiple domains to perform well on unseen domains, offer a promising direction to solve the problem. However, existing DG methods assume domain labels of each image are available and accurate, which is typically feasible for only a limited number of medical datasets. To address these challenges, we propose a novel DG framework for medical image classification without relying on domain labels, called Prompt-driven Latent Domain Generalization (PLDG). PLDG consists of unsupervised domain discovery and prompt learning. This framework first discovers pseudo domain labels by clustering the bias-associated style features, then leverages collaborative domain prompts to guide a Vision Transformer to learn knowledge from discovered diverse domains. To facilitate cross-domain knowledge learning between different prompts, we introduce a domain prompt generator that enables knowledge sharing between domain prompts and a shared prompt. A domain mixup strategy is additionally employed for more flexible decision margins and mitigates the risk of incorrect domain assignments. Extensive experiments on three medical image classification tasks and one debiasing task demonstrate that our method can achieve comparable or even superior performance than conventional DG algorithms without relying on domain labels. Our code will be publicly available upon the paper is accepted.
HGCLIP: Exploring Vision-Language Models with Graph Representations for Hierarchical Understanding
Nov 23, 2023



Object categories are typically organized into a multi-granularity taxonomic hierarchy. When classifying categories at different hierarchy levels, traditional uni-modal approaches focus primarily on image features, revealing limitations in complex scenarios. Recent studies integrating Vision-Language Models (VLMs) with class hierarchies have shown promise, yet they fall short of fully exploiting the hierarchical relationships. These efforts are constrained by their inability to perform effectively across varied granularity of categories. To tackle this issue, we propose a novel framework (HGCLIP) that effectively combines CLIP with a deeper exploitation of the Hierarchical class structure via Graph representation learning. We explore constructing the class hierarchy into a graph, with its nodes representing the textual or image features of each category. After passing through a graph encoder, the textual features incorporate hierarchical structure information, while the image features emphasize class-aware features derived from prototypes through the attention mechanism. Our approach demonstrates significant improvements on both generic and fine-grained visual recognition benchmarks. Our codes are fully available at https://github.com/richard-peng-xia/HGCLIP.
NurViD: A Large Expert-Level Video Database for Nursing Procedure Activity Understanding
Oct 20, 2023



The application of deep learning to nursing procedure activity understanding has the potential to greatly enhance the quality and safety of nurse-patient interactions. By utilizing the technique, we can facilitate training and education, improve quality control, and enable operational compliance monitoring. However, the development of automatic recognition systems in this field is currently hindered by the scarcity of appropriately labeled datasets. The existing video datasets pose several limitations: 1) these datasets are small-scale in size to support comprehensive investigations of nursing activity; 2) they primarily focus on single procedures, lacking expert-level annotations for various nursing procedures and action steps; and 3) they lack temporally localized annotations, which prevents the effective localization of targeted actions within longer video sequences. To mitigate these limitations, we propose NurViD, a large video dataset with expert-level annotation for nursing procedure activity understanding. NurViD consists of over 1.5k videos totaling 144 hours, making it approximately four times longer than the existing largest nursing activity datasets. Notably, it encompasses 51 distinct nursing procedures and 177 action steps, providing a much more comprehensive coverage compared to existing datasets that primarily focus on limited procedures. To evaluate the efficacy of current deep learning methods on nursing activity understanding, we establish three benchmarks on NurViD: procedure recognition on untrimmed videos, procedure and action recognition on trimmed videos, and action detection. Our benchmark and code will be available at \url{https://github.com/minghu0830/NurViD-benchmark}.