 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2Diff: Multi-Modality Multi-Task Enhanced Diffusion Model for MRI-Guided Low-Dose PET Enhancement
Mar 10, 2026Positron emission tomography (PET) scans expose patients to radiation, which can be mitigated by reducing the dose, albeit at the cost of diminished quality. This makes low-dose (LD) PET recovery an active research area. Previous studies have focused on standard-dose (SD) PET recovery from LD PET scans and/or multi-modal scans, e.g., PET/CT or PET/MRI, using deep learning. While these studies incorporate multi-modal information through conditioning in a single-task model, such approaches may limit the capacity to extract modality-specific features, potentially leading to early feature dilution. Although recent studies have begun incorporating pathology-rich data, challenges remain in effectively leveraging multi-modality inputs for reconstructing diverse features, particularly in heterogeneous patient populations. To address these limitations, we introduce a multi-modality multi-task diffusion model (M2Diff) that processes MRI and LD PET scans separately to learn modality-specific features and fuse them via hierarchical feature fusion to reconstruct SD PET. This design enables effective integration of complementary structural and functional information, leading to improved reconstruction fidelity. We have validated the effectiveness of our model on both healthy and Alzheimer's disease brain datasets. The M2Diff achieves superior qualitative and quantitative performance on both datasets.
A Vision-Language Foundation Model for Zero-shot Clinical Collaboration and Automated Concept Discovery in Dermatology
Feb 11, 2026Medical foundation models have shown promise in controlled benchmarks, yet widespread deployment remains hindered by reliance on task-specific fine-tuning. Here, we introduce DermFM-Zero, a dermatology vision-language foundation model trained via masked latent modelling and contrastive learning on over 4 million multimodal data points. We evaluated DermFM-Zero across 20 benchmarks spanning zero-shot diagnosis and multimodal retrieval, achieving state-of-the-art performance without task-specific adaptation. We further evaluated its zero-shot capabilities in three multinational reader studies involving over 1,100 clinicians. In primary care settings, AI assistance enabled general practitioners to nearly double their differential diagnostic accuracy across 98 skin conditions. In specialist settings, the model significantly outperformed board-certified dermatologists in multimodal skin cancer assessment. In collaborative workflows, AI assistance enabled non-experts to surpass unassisted experts while improving management appropriateness. Finally, we show that DermFM-Zero's latent representations are interpretable: sparse autoencoders unsupervisedly disentangle clinically meaningful concepts that outperform predefined-vocabulary approaches and enable targeted suppression of artifact-induced biases, enhancing robustness without retraining. These findings demonstrate that a foundation model can provide effective, safe, and transparent zero-shot clinical decision support.
A General-Purpose Multimodal Foundation Model for Dermatology
Oct 19, 2024



Diagnosing and treating skin diseases require advanced visual skills across multiple domains and the ability to synthesize information from various imaging modalities. Current deep learning models, while effective at specific tasks such as diagnosing skin cancer from dermoscopic images, fall short in addressing the complex, multimodal demands of clinical practice. Here, we introduce PanDerm, a multimodal dermatology foundation model pretrained through self-supervised learning on a dataset of over 2 million real-world images of skin diseases, sourced from 11 clinical institutions across 4 imaging modalities. We evaluated PanDerm on 28 diverse datasets covering a range of clinical tasks, including skin cancer screening, phenotype assessment and risk stratification, diagnosis of neoplastic and inflammatory skin diseases, skin lesion segmentation, change monitoring, and metastasis prediction and prognosis. PanDerm achieved state-of-the-art performance across all evaluated tasks, often outperforming existing models even when using only 5-10% of labeled data. PanDerm's clinical utility was demonstrated through reader studies in real-world clinical settings across multiple imaging modalities. It outperformed clinicians by 10.2% in early-stage melanoma detection accuracy and enhanced clinicians' multiclass skin cancer diagnostic accuracy by 11% in a collaborative human-AI setting. Additionally, PanDerm demonstrated robust performance across diverse demographic factors, including different body locations, age groups, genders, and skin tones. The strong results in benchmark evaluations and real-world clinical scenarios suggest that PanDerm could enhance the management of skin diseases and serve as a model for developing multimodal foundation models in other medical specialties, potentially accelerating the integration of AI support in healthcare.
Prompt-driven Latent Domain Generalization for Medical Image Classification
Jan 05, 2024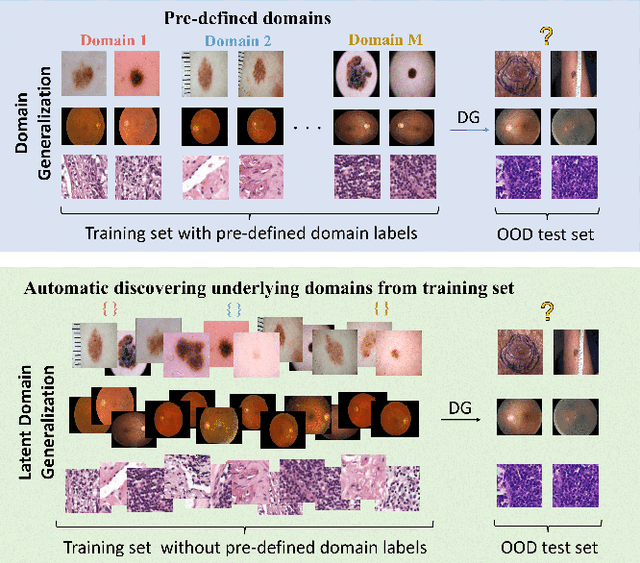
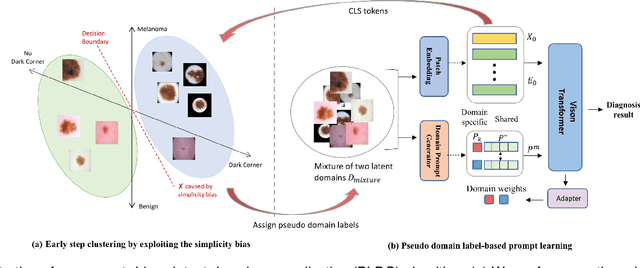
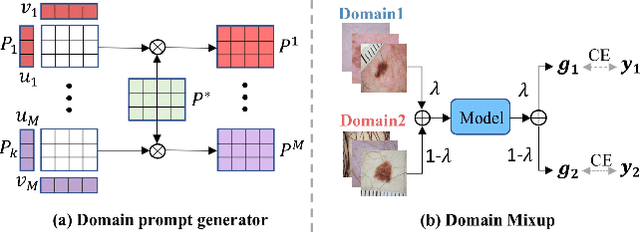

Deep learning models for medical image analysis easily suffer from distribution shifts caused by dataset artifacts bias, camera variations, differences in the imaging station, etc., leading to unreliable diagnoses in real-world clinical settings. Domain generalization (DG) methods, which aim to train models on multiple domains to perform well on unseen domains, offer a promising direction to solve the problem. However, existing DG methods assume domain labels of each image are available and accurate, which is typically feasible for only a limited number of medical datasets. To address these challenges, we propose a novel DG framework for medical image classification without relying on domain labels, called Prompt-driven Latent Domain Generalization (PLDG). PLDG consists of unsupervised domain discovery and prompt learning. This framework first discovers pseudo domain labels by clustering the bias-associated style features, then leverages collaborative domain prompts to guide a Vision Transformer to learn knowledge from discovered diverse domains. To facilitate cross-domain knowledge learning between different prompts, we introduce a domain prompt generator that enables knowledge sharing between domain prompts and a shared prompt. A domain mixup strategy is additionally employed for more flexible decision margins and mitigates the risk of incorrect domain assignments. Extensive experiments on three medical image classification tasks and one debiasing task demonstrate that our method can achieve comparable or even superior performance than conventional DG algorithms without relying on domain labels. Our code will be publicly available upon the paper is accepted.
Revamping AI Models in Dermatology: Overcoming Critical Challenges for Enhanced Skin Lesion Diagnosis
Nov 02, 2023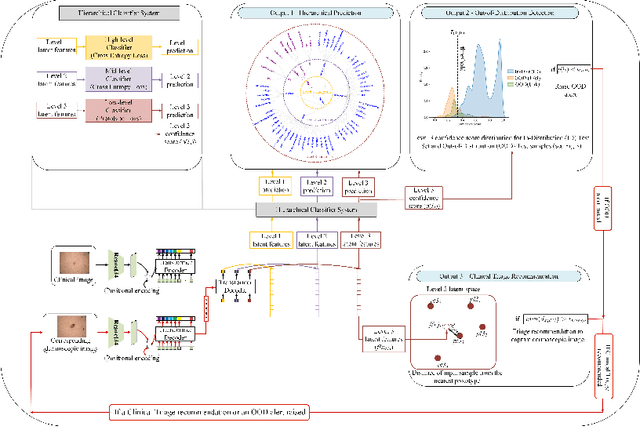
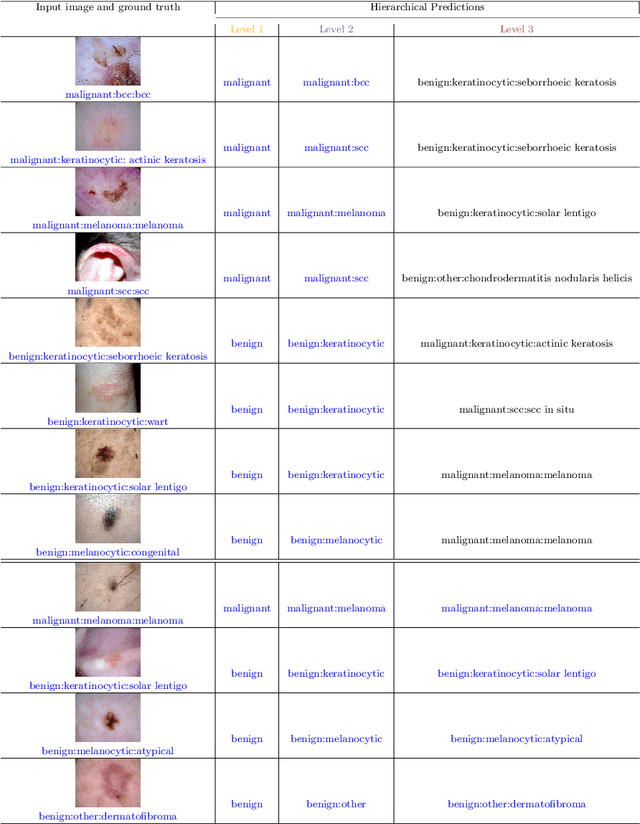
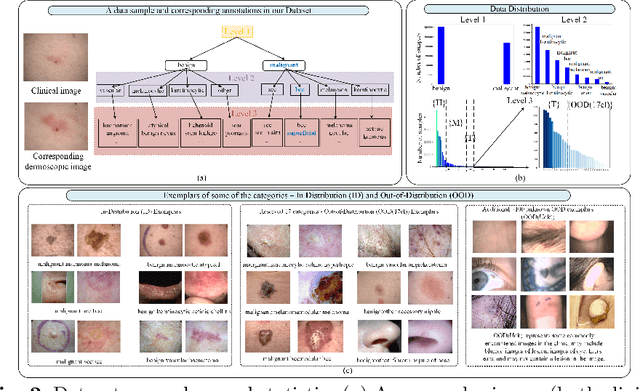

The surge in developing deep learning models for diagnosing skin lesions through image analysis is notable, yet their clinical black faces challenges. Current dermatology AI models have limitations: limited number of possible diagnostic outputs, lack of real-world testing on uncommon skin lesions, inability to detect out-of-distribution images, and over-reliance on dermoscopic images. To address these, we present an All-In-One \textbf{H}ierarchical-\textbf{O}ut of Distribution-\textbf{C}linical Triage (HOT) model. For a clinical image, our model generates three outputs: a hierarchical prediction, an alert for out-of-distribution images, and a recommendation for dermoscopy if clinical image alone is insufficient for diagnosis. When the recommendation is pursued, it integrates both clinical and dermoscopic images to deliver final diagnosis. Extensive experiments on a representative cutaneous lesion dataset demonstrate the effectiveness and synergy of each component within our framework. Our versatile model provides valuable decision support for lesion diagnosis and sets a promising precedent for medical AI applications.
EPVT: Environment-aware Prompt Vision Transformer for Domain Generalization in Skin Lesion Recognition
Apr 09, 2023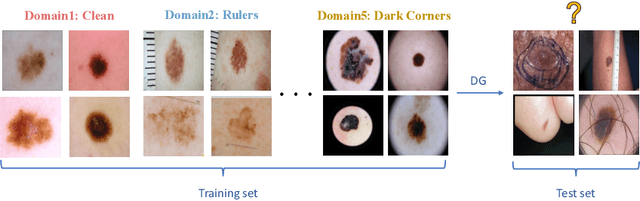
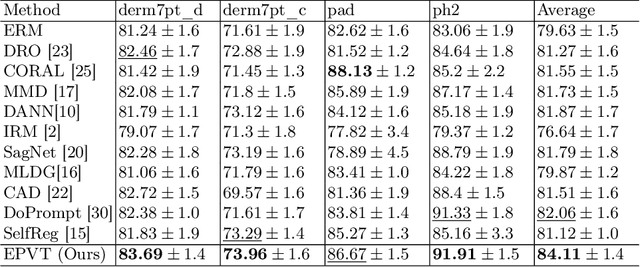
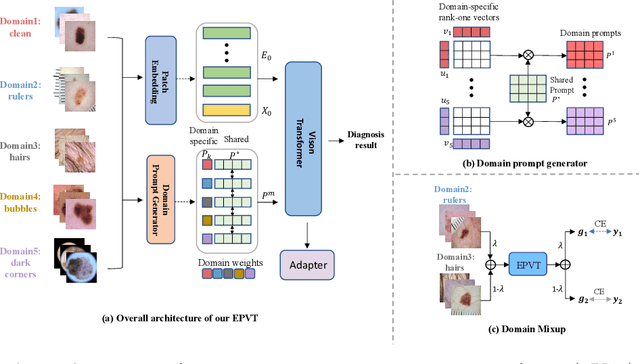
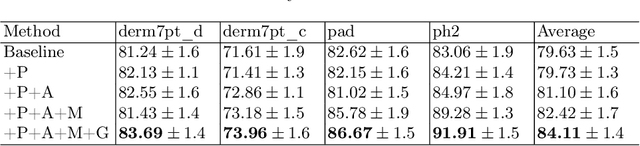
Skin lesion recognition using deep learning has made remarkable progress, and there is an increasing need for deploying these systems in real-world scenarios. However, recent research has revealed that deep neural networks for skin lesion recognition may overly depend on disease-irrelevant image artifacts (i.e. dark corners, dense hairs), leading to poor generalization in unseen environments. To address this issue, we propose a novel domain generalization method called EPVT, which involves embedding prompts into the vision transformer to collaboratively learn knowledge from diverse domains. Concretely, EPVT leverages a set of domain prompts, each of which plays as a domain expert, to capture domain-specific knowledge; and a shared prompt for general knowledge over the entire dataset. To facilitate knowledge sharing and the interaction of different prompts, we introduce a domain prompt generator that enables low-rank multiplicative updates between domain prompts and the shared prompt. A domain mixup strategy is additionally devised to reduce the co-occurring artifacts in each domain, which allows for more flexible decision margins and mitigates the issue of incorrectly assigned domain labels. Experiments on four out-of-distribution datasets and six different biased ISIC datasets demonstrate the superior generalization ability of EPVT in skin lesion recognition across various environments. Our code and dataset will be released at https://github.com/SiyuanYan1/EPVT.
Skin Lesion Recognition with Class-Hierarchy Regularized Hyperbolic Embeddings
Sep 13, 2022In practice, many medical datasets have an underlying taxonomy defined over the disease label space. However, existing classification algorithms for medical diagnoses often assume semantically independent labels. In this study, we aim to leverage class hierarchy with deep learning algorithms for more accurate and reliable skin lesion recognition. We propose a hyperbolic network to learn image embeddings and class prototypes jointly. The hyperbola provably provides a space for modeling hierarchical relations better than Euclidean geometry. Meanwhile, we restrict the distribution of hyperbolic prototypes with a distance matrix that is encoded from the class hierarchy. Accordingly, the learned prototypes preserve the semantic class relations in the embedding space and we can predict the label of an image by assigning its feature to the nearest hyperbolic class prototype. We use an in-house skin lesion dataset which consists of around 230k dermoscopic images on 65 skin diseases to verify our method. Extensive experiments provide evidence that our model can achieve higher accuracy with less severe classification errors than models without considering class relations.
Early Melanoma Diagnosis with Sequential Dermoscopic Images
Oct 12, 2021
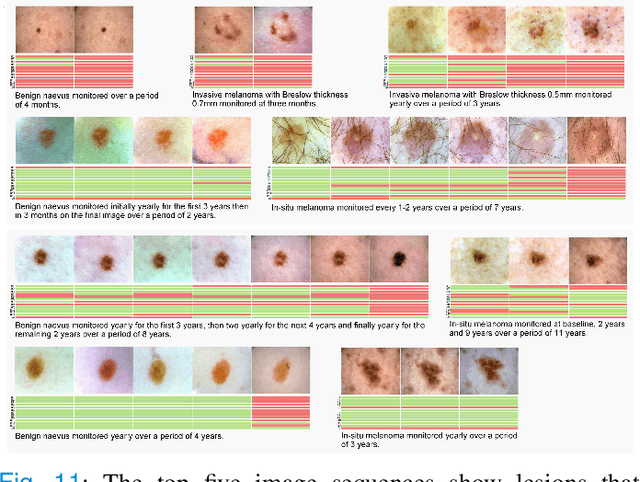
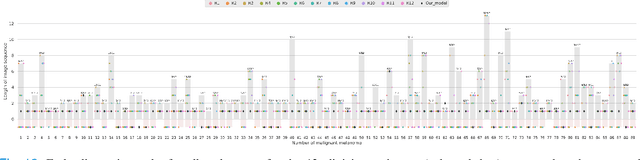
Dermatologists often diagnose or rule out early melanoma by evaluating the follow-up dermoscopic images of skin lesions. However, existing algorithms for early melanoma diagnosis are developed using single time-point images of lesions. Ignoring the temporal, morphological changes of lesions can lead to misdiagnosis in borderline cases. In this study, we propose a framework for automated early melanoma diagnosis using sequential dermoscopic images. To this end, we construct our method in three steps. First, we align sequential dermoscopic images of skin lesions using estimated Euclidean transformations, extract the lesion growth region by computing image differences among the consecutive images, and then propose a spatio-temporal network to capture the dermoscopic changes from aligned lesion images and the corresponding difference images. Finally, we develop an early diagnosis module to compute probability scores of malignancy for lesion images over time. We collected 179 serial dermoscopic imaging data from 122 patients to verify our method. Extensive experiments show that the proposed model outperforms other commonly used sequence models. We also compared the diagnostic results of our model with those of seven experienced dermatologists and five registrars. Our model achieved higher diagnostic accuracy than clinicians (63.69% vs. 54.33%, respectively) and provided an earlier diagnosis of melanoma (60.7% vs. 32.7% of melanoma correctly diagnosed on the first follow-up images). These results demonstrate that our model can be used to identify melanocytic lesions that are at high-risk of malignant transformation earlier in the disease process and thereby redefine what is possible in the early detection of melanoma.
Melanoma Diagnosis with Spatio-Temporal Feature Learning on Sequential Dermoscopic Images
Jun 19, 2020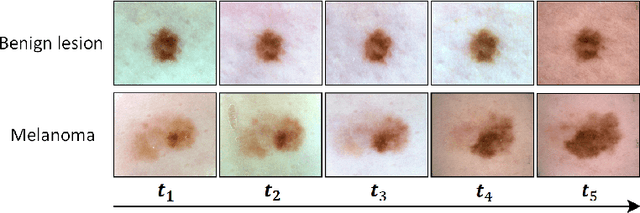
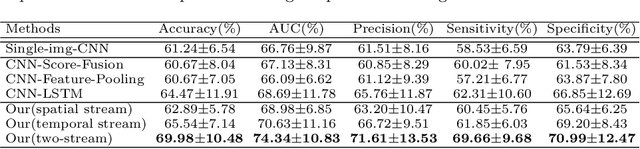
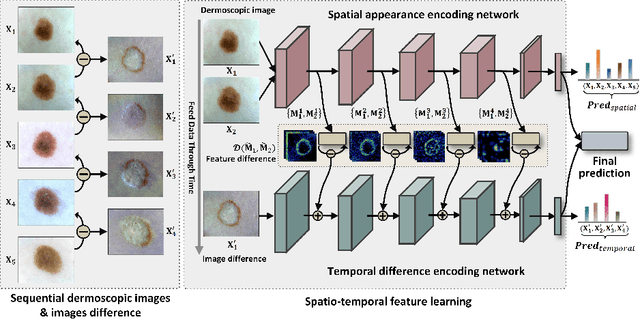
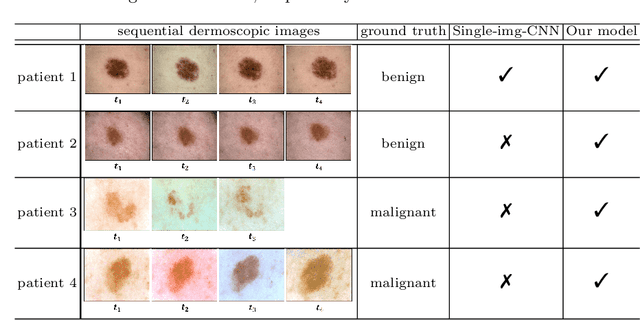
Existing studies for automated melanoma diagnosis are based on single-time point images of lesions. However, melanocytic lesions de facto are progressively evolving and, moreover, benign lesions can progress into malignant melanoma. Ignoring cross-time morphological changes of lesions thus may lead to misdiagnosis in borderline cases. Based on the fact that dermatologists diagnose ambiguous skin lesions by evaluating the dermoscopic changes over time via follow-up examination, in this study, we propose an automated framework for melanoma diagnosis using sequential dermoscopic images. To capture the spatio-temporal characterization of dermoscopic evolution, we construct our model in a two-stream network architecture which capable of simultaneously learning appearance representations of individual lesions while performing temporal reasoning on both raw pixels difference and abstract features difference. We collect 184 cases of serial dermoscopic image data, which consists of histologically confirmed 92 benign lesions and 92 melanoma lesions, to evaluate the effectiveness of the proposed method. Our model achieved AUC of 74.34%, which is ~8% higher than that of only using single images and ~6% higher than the widely used sequence learning model based on LSTM.