 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Pre-training Across Domains for Few-Shot Surgical Skill Assessment
Sep 11, 2025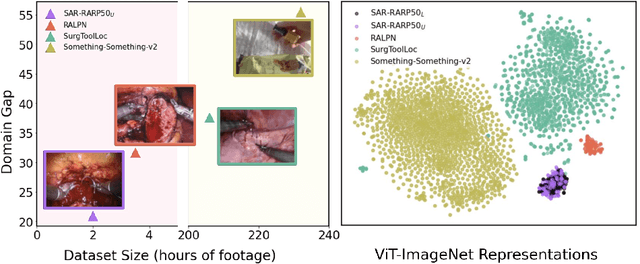

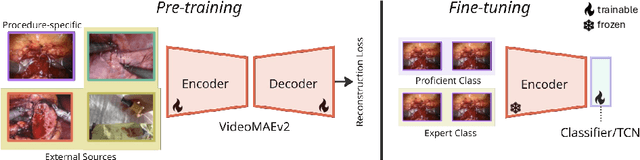
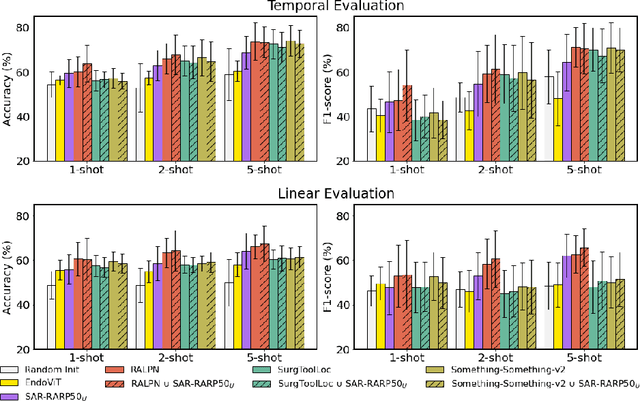
Automated surgical skill assessment (SSA) is a central task in surgical computer vision. Developing robust SSA models is challenging due to the scarcity of skill annotations, which are time-consuming to produce and require expert consensus. Few-shot learning (FSL) offers a scalable alternative enabling model development with minimal supervision, though its success critically depends on effective pre-training. While widely studied for several surgical downstream tasks, pre-training has remained largely unexplored in SSA. In this work, we formulate SSA as a few-shot task and investigate how self-supervised pre-training strategies affect downstream few-shot SSA performance. We annotate a publicly available robotic surgery dataset with Objective Structured Assessment of Technical Skill (OSATS) scores, and evaluate various pre-training sources across three few-shot settings. We quantify domain similarity and analyze how domain gap and the inclusion of procedure-specific data into pre-training influence transferability. Our results show that small but domain-relevant datasets can outperform large scale, less aligned ones, achieving accuracies of 60.16%, 66.03%, and 73.65% in the 1-, 2-, and 5-shot settings, respectively. Moreover, incorporating procedure-specific data into pre-training with a domain-relevant external dataset significantly boosts downstream performance, with an average gain of +1.22% in accuracy and +2.28% in F1-score; however, applying the same strategy with less similar but large-scale sources can instead lead to performance degradation. Code and models are available at https://github.com/anastadimi/ssa-fsl.
Fine-Tuning Federated Learning-Based Intrusion Detection Systems for Transportation IoT
Feb 10, 2025

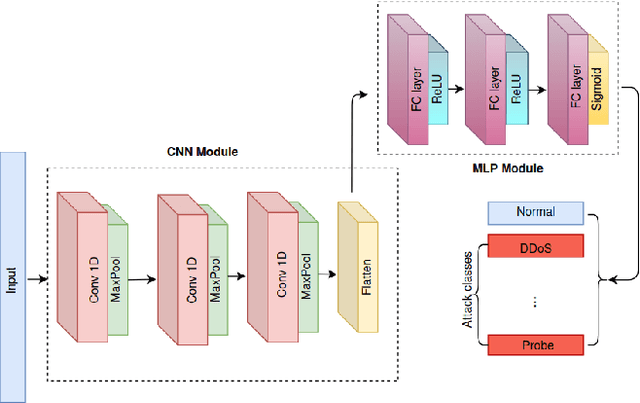

The rapid advancement of machine learning (ML) and on-device computing has revolutionized various industries, including transportation, through the development of Connected and Autonomous Vehicles (CAVs) and Intelligent Transportation Systems (ITS). These technologies improve traffic management and vehicle safety, but also introduce significant security and privacy concerns, such as cyberattacks and data breaches. Traditional Intrusion Detection Systems (IDS) are increasingly inadequate in detecting modern threats, leading to the adoption of ML-based IDS solutions. Federated Learning (FL) has emerged as a promising method for enabling the decentralized training of IDS models on distributed edge devices without sharing sensitive data. However, deploying FL-based IDS in CAV networks poses unique challenges, including limited computational and memory resources on edge devices, competing demands from critical applications such as navigation and safety systems, and the need to scale across diverse hardware and connectivity conditions. To address these issues, we propose a hybrid server-edge FL framework that offloads pre-training to a central server while enabling lightweight fine-tuning on edge devices. This approach reduces memory usage by up to 42%, decreases training times by up to 75%, and achieves competitive IDS accuracy of up to 99.2%. Scalability analyses further demonstrates minimal performance degradation as the number of clients increase, highlighting the framework's feasibility for CAV networks and other IoT applications.
Early Melanoma Diagnosis with Sequential Dermoscopic Images
Oct 12, 2021
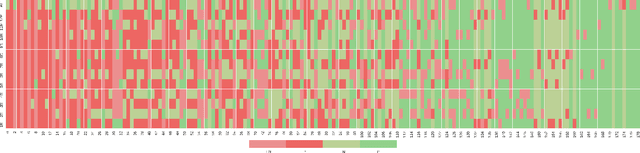
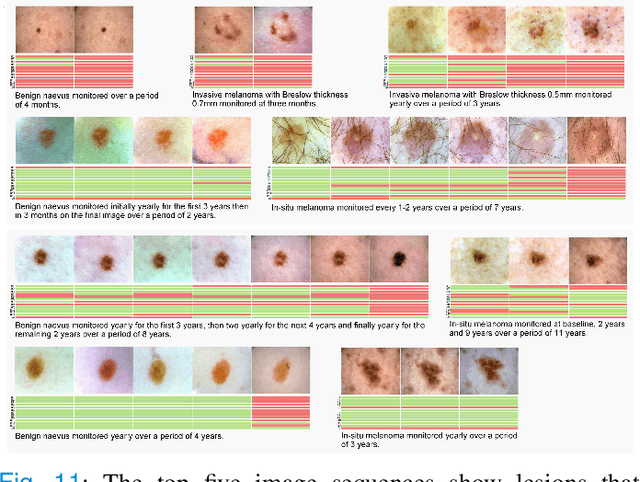
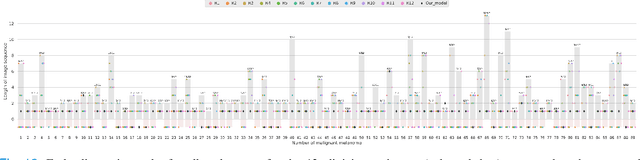
Dermatologists often diagnose or rule out early melanoma by evaluating the follow-up dermoscopic images of skin lesions. However, existing algorithms for early melanoma diagnosis are developed using single time-point images of lesions. Ignoring the temporal, morphological changes of lesions can lead to misdiagnosis in borderline cases. In this study, we propose a framework for automated early melanoma diagnosis using sequential dermoscopic images. To this end, we construct our method in three steps. First, we align sequential dermoscopic images of skin lesions using estimated Euclidean transformations, extract the lesion growth region by computing image differences among the consecutive images, and then propose a spatio-temporal network to capture the dermoscopic changes from aligned lesion images and the corresponding difference images. Finally, we develop an early diagnosis module to compute probability scores of malignancy for lesion images over time. We collected 179 serial dermoscopic imaging data from 122 patients to verify our method. Extensive experiments show that the proposed model outperforms other commonly used sequence models. We also compared the diagnostic results of our model with those of seven experienced dermatologists and five registrars. Our model achieved higher diagnostic accuracy than clinicians (63.69% vs. 54.33%, respectively) and provided an earlier diagnosis of melanoma (60.7% vs. 32.7% of melanoma correctly diagnosed on the first follow-up images). These results demonstrate that our model can be used to identify melanocytic lesions that are at high-risk of malignant transformation earlier in the disease process and thereby redefine what is possible in the early detection of melanoma.
Melanoma Diagnosis with Spatio-Temporal Feature Learning on Sequential Dermoscopic Images
Jun 19, 2020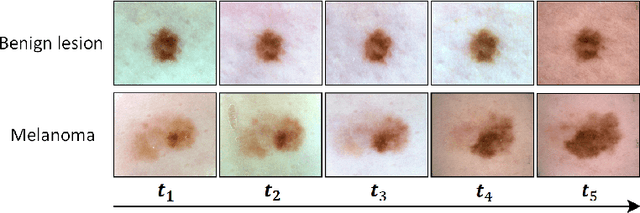
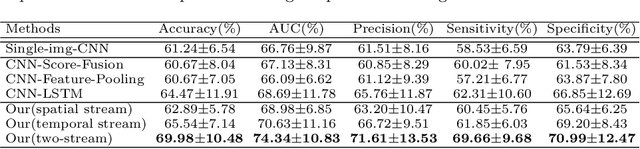
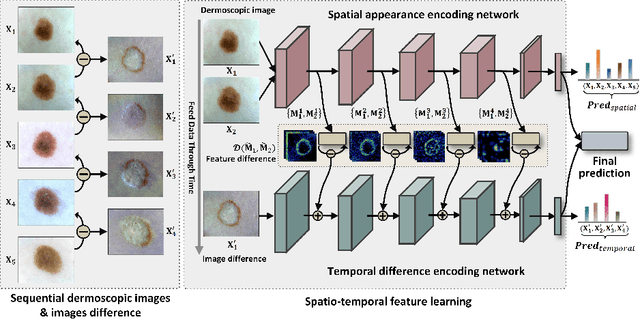
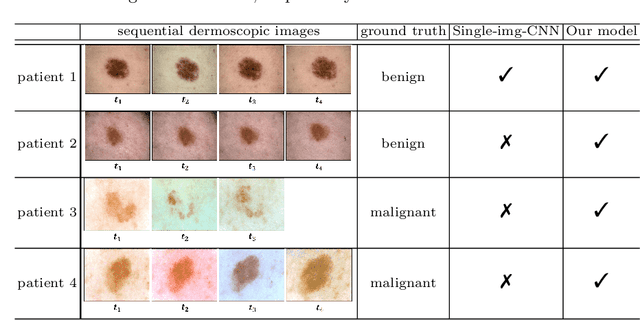
Existing studies for automated melanoma diagnosis are based on single-time point images of lesions. However, melanocytic lesions de facto are progressively evolving and, moreover, benign lesions can progress into malignant melanoma. Ignoring cross-time morphological changes of lesions thus may lead to misdiagnosis in borderline cases. Based on the fact that dermatologists diagnose ambiguous skin lesions by evaluating the dermoscopic changes over time via follow-up examination, in this study, we propose an automated framework for melanoma diagnosis using sequential dermoscopic images. To capture the spatio-temporal characterization of dermoscopic evolution, we construct our model in a two-stream network architecture which capable of simultaneously learning appearance representations of individual lesions while performing temporal reasoning on both raw pixels difference and abstract features difference. We collect 184 cases of serial dermoscopic image data, which consists of histologically confirmed 92 benign lesions and 92 melanoma lesions, to evaluate the effectiveness of the proposed method. Our model achieved AUC of 74.34%, which is ~8% higher than that of only using single images and ~6% higher than the widely used sequence learning model based on LSTM.
Higher Order of Motion Magnification for Vessel Localisation in Surgical Video
Jun 13, 2018
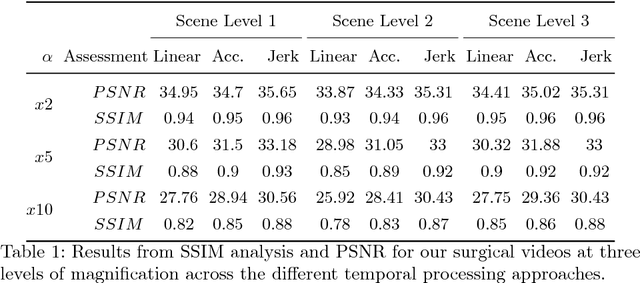
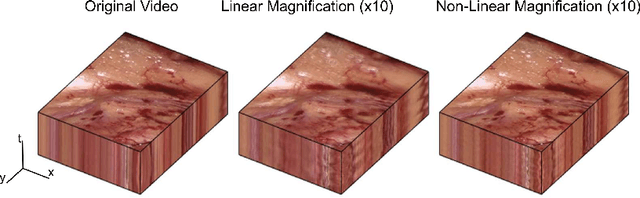
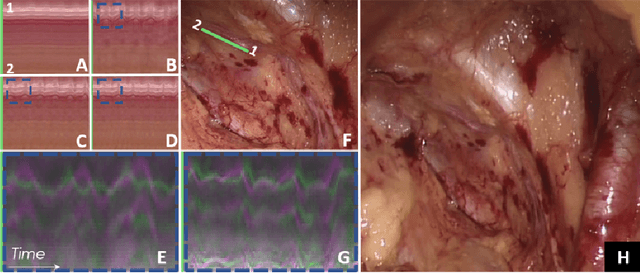
Locating vessels during surgery is critical for avoiding inadvertent damage, yet vasculature can be difficult to identify. Video motion magnification can potentially highlight vessels by exaggerating subtle motion embedded within the video to become perceivable to the surgeon. In this paper, we explore a physiological model of artery distension to extend motion magnification to incorporate higher orders of motion, leveraging the difference in acceleration over time (jerk) in pulsatile motion to highlight the vascular pulse wave. Our method is compared to first and second order motion based Eulerian video magnification algorithms. Using data from a surgical video retrieved during a robotic prostatectomy, we show that our method can accentuate cardio-physiological features and produce a more succinct and clearer video for motion magnification, with more similarities in areas without motion to the source video at large magnifications. We validate the approach with a Structure Similarity (SSIM) and Peak Signal to Noise Ratio (PSNR) assessment of three videos at an increasing working distance, using three different levels of optical magnification. Spatio-temporal cross sections are presented to show the effectiveness of our proposal and video samples are provided to demonstrates qualitatively our results.