 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive-Boundary-Clipping GRPO: Ensuring Bounded Ratios for Stable and Generalizable Training
Jan 07, 2026Group Relative Policy Optimization (GRPO) has emerged as a popular algorithm for reinforcement learning with large language models (LLMs). However, upon analyzing its clipping mechanism, we argue that it is suboptimal in certain scenarios. With appropriate modifications, GRPO can be significantly enhanced to improve both flexibility and generalization. To this end, we propose Adaptive-Boundary-Clipping GRPO (ABC-GRPO), an asymmetric and adaptive refinement of the original GRPO framework. We demonstrate that ABC-GRPO achieves superior performance over standard GRPO on mathematical reasoning tasks using the Qwen3 LLMs. Moreover, ABC-GRPO maintains substantially higher entropy throughout training, thereby preserving the model's exploration capacity and mitigating premature convergence. The implementation code is available online to ease reproducibility https://github.com/chi2liu/ABC-GRPO.
Fraud Detection Through Large-Scale Graph Clustering with Heterogeneous Link Transformation
Dec 22, 2025Collaborative fraud, where multiple fraudulent accounts coordinate to exploit online payment systems, poses significant challenges due to the formation of complex network structures. Traditional detection methods that rely solely on high-confidence identity links suffer from limited coverage, while approaches using all available linkages often result in fragmented graphs with reduced clustering effectiveness. In this paper, we propose a novel graph-based fraud detection framework that addresses the challenge of large-scale heterogeneous graph clustering through a principled link transformation approach. Our method distinguishes between \emph{hard links} (high-confidence identity relationships such as phone numbers, credit cards, and national IDs) and \emph{soft links} (behavioral associations including device fingerprints, cookies, and IP addresses). We introduce a graph transformation technique that first identifies connected components via hard links, merges them into super-nodes, and then reconstructs a weighted soft-link graph amenable to efficient embedding and clustering. The transformed graph is processed using LINE (Large-scale Information Network Embedding) for representation learning, followed by HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) for density-based cluster discovery. Experiments on a real-world payment platform dataset demonstrate that our approach achieves significant graph size reduction (from 25 million to 7.7 million nodes), doubles the detection coverage compared to hard-link-only baselines, and maintains high precision across identified fraud clusters. Our framework provides a scalable and practical solution for industrial-scale fraud detection systems.
Rethinking Bias in Generative Data Augmentation for Medical AI: a Frequency Recalibration Method
Nov 15, 2025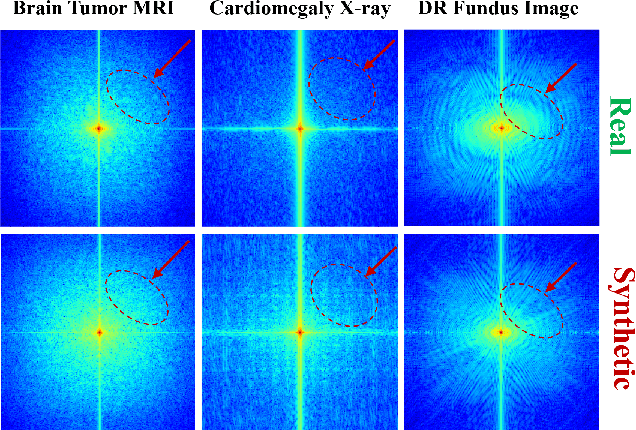

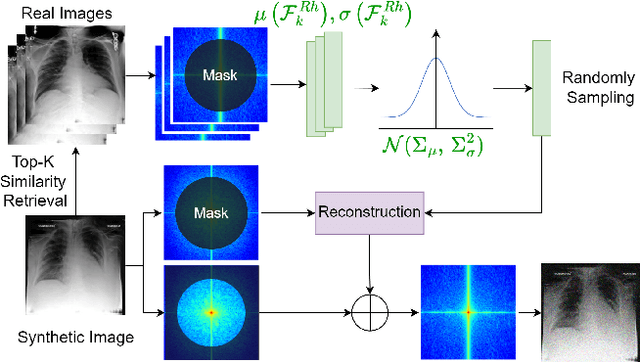
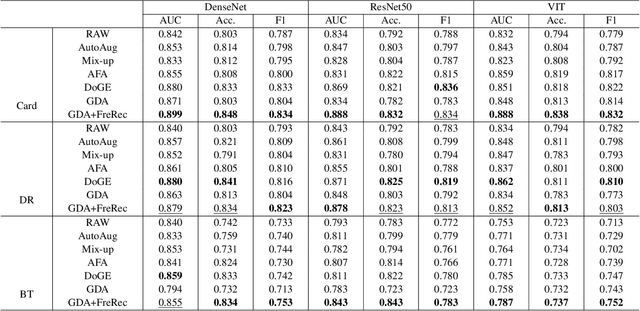
Developing Medical AI relies on large datasets and easily suffers from data scarcity. Generative data augmentation (GDA) using AI generative models offers a solution to synthesize realistic medical images. However, the bias in GDA is often underestimated in medical domains, with concerns about the risk of introducing detrimental features generated by AI and harming downstream tasks. This paper identifies the frequency misalignment between real and synthesized images as one of the key factors underlying unreliable GDA and proposes the Frequency Recalibration (FreRec) method to reduce the frequency distributional discrepancy and thus improve GDA. FreRec involves (1) Statistical High-frequency Replacement (SHR) to roughly align high-frequency components and (2) Reconstructive High-frequency Mapping (RHM) to enhance image quality and reconstruct high-frequency details. Extensive experiments were conducted in various medical datasets, including brain MRIs, chest X-rays, and fundus images. The results show that FreRec significantly improves downstream medical image classification performance compared to uncalibrated AI-synthesized samples. FreRec is a standalone post-processing step that is compatible with any generative model and can integrate seamlessly with common medical GDA pipelines.
Fleming-R1: Toward Expert-Level Medical Reasoning via Reinforcement Learning
Sep 18, 2025While large language models show promise in medical applications, achieving expert-level clinical reasoning remains challenging due to the need for both accurate answers and transparent reasoning processes. To address this challenge, we introduce Fleming-R1, a model designed for verifiable medical reasoning through three complementary innovations. First, our Reasoning-Oriented Data Strategy (RODS) combines curated medical QA datasets with knowledge-graph-guided synthesis to improve coverage of underrepresented diseases, drugs, and multi-hop reasoning chains. Second, we employ Chain-of-Thought (CoT) cold start to distill high-quality reasoning trajectories from teacher models, establishing robust inference priors. Third, we implement a two-stage Reinforcement Learning from Verifiable Rewards (RLVR) framework using Group Relative Policy Optimization, which consolidates core reasoning skills while targeting persistent failure modes through adaptive hard-sample mining. Across diverse medical benchmarks, Fleming-R1 delivers substantial parameter-efficient improvements: the 7B variant surpasses much larger baselines, while the 32B model achieves near-parity with GPT-4o and consistently outperforms strong open-source alternatives. These results demonstrate that structured data design, reasoning-oriented initialization, and verifiable reinforcement learning can advance clinical reasoning beyond simple accuracy optimization. We release Fleming-R1 publicly to promote transparent, reproducible, and auditable progress in medical AI, enabling safer deployment in high-stakes clinical environments.
Causal Fingerprints of AI Generative Models
Sep 18, 2025AI generative models leave implicit traces in their generated images, which are commonly referred to as model fingerprints and are exploited for source attribution. Prior methods rely on model-specific cues or synthesis artifacts, yielding limited fingerprints that may generalize poorly across different generative models. We argue that a complete model fingerprint should reflect the causality between image provenance and model traces, a direction largely unexplored. To this end, we conceptualize the \emph{causal fingerprint} of generative models, and propose a causality-decoupling framework that disentangles it from image-specific content and style in a semantic-invariant latent space derived from pre-trained diffusion reconstruction residual. We further enhance fingerprint granularity with diverse feature representations. We validate causality by assessing attribution performance across representative GANs and diffusion models and by achieving source anonymization using counterfactual examples generated from causal fingerprints. Experiments show our approach outperforms existing methods in model attribution, indicating strong potential for forgery detection, model copyright tracing, and identity protection.
Enhancing Fundus Image-based Glaucoma Screening via Dynamic Global-Local Feature Integration
Apr 01, 2025



With the advancements in medical artificial intelligence (AI), fundus image classifiers are increasingly being applied to assist in ophthalmic diagnosis. While existing classification models have achieved high accuracy on specific fundus datasets, they struggle to address real-world challenges such as variations in image quality across different imaging devices, discrepancies between training and testing images across different racial groups, and the uncertain boundaries due to the characteristics of glaucomatous cases. In this study, we aim to address the above challenges posed by image variations by highlighting the importance of incorporating comprehensive fundus image information, including the optic cup (OC) and optic disc (OD) regions, and other key image patches. Specifically, we propose a self-adaptive attention window that autonomously determines optimal boundaries for enhanced feature extraction. Additionally, we introduce a multi-head attention mechanism to effectively fuse global and local features via feature linear readout, improving the model's discriminative capability. Experimental results demonstrate that our method achieves superior accuracy and robustness in glaucoma classification.
Unleashing the Power of Pre-trained Encoders for Universal Adversarial Attack Detection
Apr 01, 2025



Adversarial attacks pose a critical security threat to real-world AI systems by injecting human-imperceptible perturbations into benign samples to induce misclassification in deep learning models. While existing detection methods, such as Bayesian uncertainty estimation and activation pattern analysis, have achieved progress through feature engineering, their reliance on handcrafted feature design and prior knowledge of attack patterns limits generalization capabilities and incurs high engineering costs. To address these limitations, this paper proposes a lightweight adversarial detection framework based on the large-scale pre-trained vision-language model CLIP. Departing from conventional adversarial feature characterization paradigms, we innovatively adopt an anomaly detection perspective. By jointly fine-tuning CLIP's dual visual-text encoders with trainable adapter networks and learnable prompts, we construct a compact representation space tailored for natural images. Notably, our detection architecture achieves substantial improvements in generalization capability across both known and unknown attack patterns compared to traditional methods, while significantly reducing training overhead. This study provides a novel technical pathway for establishing a parameter-efficient and attack-agnostic defense paradigm, markedly enhancing the robustness of vision systems against evolving adversarial threats.
Can LLMs Assist Computer Education? an Empirical Case Study of DeepSeek
Apr 01, 2025



This study presents an empirical case study to assess the efficacy and reliability of DeepSeek-V3, an emerging large language model, within the context of computer education. The evaluation employs both CCNA simulation questions and real-world inquiries concerning computer network security posed by Chinese network engineers. To ensure a thorough evaluation, diverse dimensions are considered, encompassing role dependency, cross-linguistic proficiency, and answer reproducibility, accompanied by statistical analysis. The findings demonstrate that the model performs consistently, regardless of whether prompts include a role definition or not. In addition, its adaptability across languages is confirmed by maintaining stable accuracy in both original and translated datasets. A distinct contrast emerges between its performance on lower-order factual recall tasks and higher-order reasoning exercises, which underscores its strengths in retrieving information and its limitations in complex analytical tasks. Although DeepSeek-V3 offers considerable practical value for network security education, challenges remain in its capability to process multimodal data and address highly intricate topics. These results provide valuable insights for future refinement of large language models in specialized professional environments.
Fed-NDIF: A Noise-Embedded Federated Diffusion Model For Low-Count Whole-Body PET Denoising
Mar 20, 2025



Low-count positron emission tomography (LCPET) imaging can reduce patients' exposure to radiation but often suffers from increased image noise and reduced lesion detectability, necessitating effective denoising techniques. Diffusion models have shown promise in LCPET denoising for recovering degraded image quality. However, training such models requires large and diverse datasets, which are challenging to obtain in the medical domain. To address data scarcity and privacy concerns, we combine diffusion models with federated learning -- a decentralized training approach where models are trained individually at different sites, and their parameters are aggregated on a central server over multiple iterations. The variation in scanner types and image noise levels within and across institutions poses additional challenges for federated learning in LCPET denoising. In this study, we propose a novel noise-embedded federated learning diffusion model (Fed-NDIF) to address these challenges, leveraging a multicenter dataset and varying count levels. Our approach incorporates liver normalized standard deviation (NSTD) noise embedding into a 2.5D diffusion model and utilizes the Federated Averaging (FedAvg) algorithm to aggregate locally trained models into a global model, which is subsequently fine-tuned on local datasets to optimize performance and obtain personalized models. Extensive validation on datasets from the University of Bern, Ruijin Hospital in Shanghai, and Yale-New Haven Hospital demonstrates the superior performance of our method in enhancing image quality and improving lesion quantification. The Fed-NDIF model shows significant improvements in PSNR, SSIM, and NMSE of the entire 3D volume, as well as enhanced lesion detectability and quantification, compared to local diffusion models and federated UNet-based models.
Anatomically and Metabolically Informed Diffusion for Unified Denoising and Segmentation in Low-Count PET Imaging
Mar 17, 2025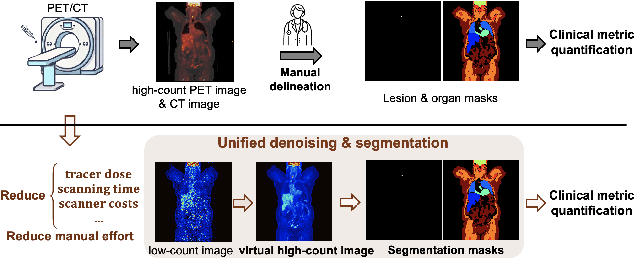
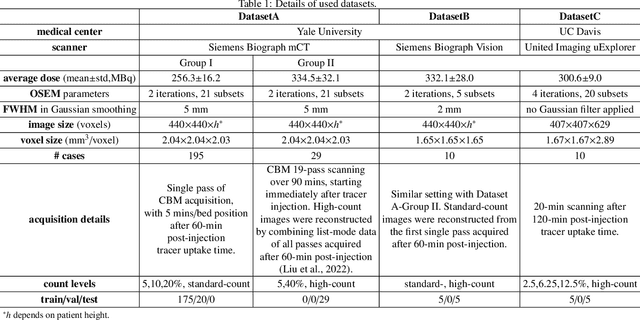
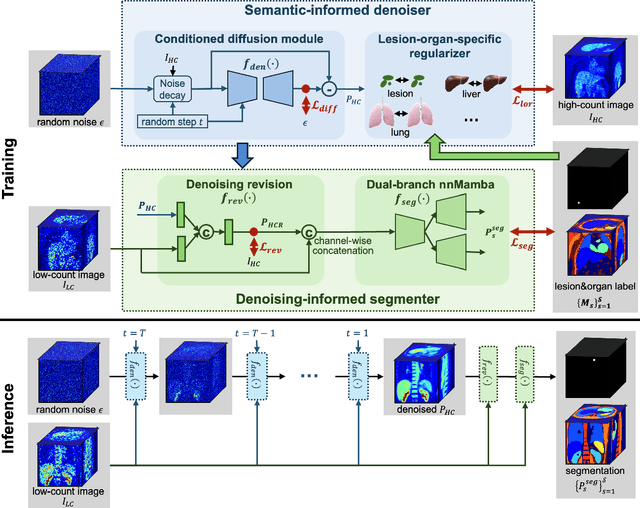
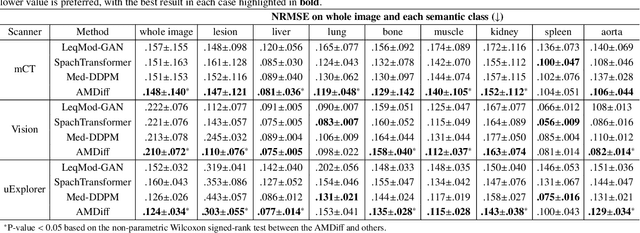
Positron emission tomography (PET) image denoising, along with lesion and organ segmentation, are critical steps in PET-aided diagnosis. However, existing methods typically treat these tasks independently, overlooking inherent synergies between them as correlated steps in the analysis pipeline. In this work, we present the anatomically and metabolically informed diffusion (AMDiff) model, a unified framework for denoising and lesion/organ segmentation in low-count PET imaging. By integrating multi-task functionality and exploiting the mutual benefits of these tasks, AMDiff enables direct quantification of clinical metrics, such as total lesion glycolysis (TLG), from low-count inputs. The AMDiff model incorporates a semantic-informed denoiser based on diffusion strategy and a denoising-informed segmenter utilizing nnMamba architecture. The segmenter constrains denoised outputs via a lesion-organ-specific regularizer, while the denoiser enhances the segmenter by providing enriched image information through a denoising revision module. These components are connected via a warming-up mechanism to optimize multitask interactions. Experiments on multi-vendor, multi-center, and multi-noise-level datasets demonstrate the superior performance of AMDiff. For test cases below 20% of the clinical count levels from participating sites, AMDiff achieves TLG quantification biases of -26.98%, outperforming its ablated versions which yield biases of -35.85% (without the lesion-organ-specific regularizer) and -40.79% (without the denoising revision module).