 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Privacy: Inference-Time Privacy through Certified Robustness
Jan 24, 2026Machine learning systems can produce personalized outputs that allow an adversary to infer sensitive input attributes at inference time. We introduce Robust Privacy (RP), an inference-time privacy notion inspired by certified robustness: if a model's prediction is provably invariant within a radius-$R$ neighborhood around an input $x$ (e.g., under the $\ell_2$ norm), then $x$ enjoys $R$-Robust Privacy, i.e., observing the prediction cannot distinguish $x$ from any input within distance $R$ of $x$. We further develop Attribute Privacy Enhancement (APE) to translate input-level invariance into an attribute-level privacy effect. In a controlled recommendation task where the decision depends primarily on a sensitive attribute, we show that RP expands the set of sensitive-attribute values compatible with a positive recommendation, expanding the inference interval accordingly. Finally, we empirically demonstrate that RP also mitigates model inversion attacks (MIAs) by masking fine-grained input-output dependence. Even at small noise levels ($σ=0.1$), RP reduces the attack success rate (ASR) from 73% to 4% with partial model performance degradation. RP can also partially mitigate MIAs (e.g., ASR drops to 44%) with no model performance degradation.
LymphAtlas- A Unified Multimodal Lymphoma Imaging Repository Delivering AI-Enhanced Diagnostic Insight
Apr 29, 2025This study integrates PET metabolic information with CT anatomical structures to establish a 3D multimodal segmentation dataset for lymphoma based on whole-body FDG PET/CT examinations, which bridges the gap of the lack of standardised multimodal segmentation datasets in the field of haematological malignancies. We retrospectively collected 483 examination datasets acquired between March 2011 and May 2024, involving 220 patients (106 non-Hodgkin lymphoma, 42 Hodgkin lymphoma); all data underwent ethical review and were rigorously de-identified. Complete 3D structural information was preserved during data acquisition, preprocessing and annotation, and a high-quality dataset was constructed based on the nnUNet format. By systematic technical validation and evaluation of the preprocessing process, annotation quality and automatic segmentation algorithm, the deep learning model trained based on this dataset is verified to achieve accurate segmentation of lymphoma lesions in PET/CT images with high accuracy, good robustness and reproducibility, which proves the applicability and stability of this dataset in accurate segmentation and quantitative analysis. The deep fusion of PET/CT images achieved with this dataset not only significantly improves the accurate portrayal of the morphology, location and metabolic features of tumour lesions, but also provides solid data support for early diagnosis, clinical staging and personalized treatment, and promotes the development of automated image segmentation and precision medicine based on deep learning. The dataset and related resources are available at https://github.com/SuperD0122/LymphAtlas-.
Evaluating and Mitigating Social Bias for Large Language Models in Open-ended Settings
Dec 09, 2024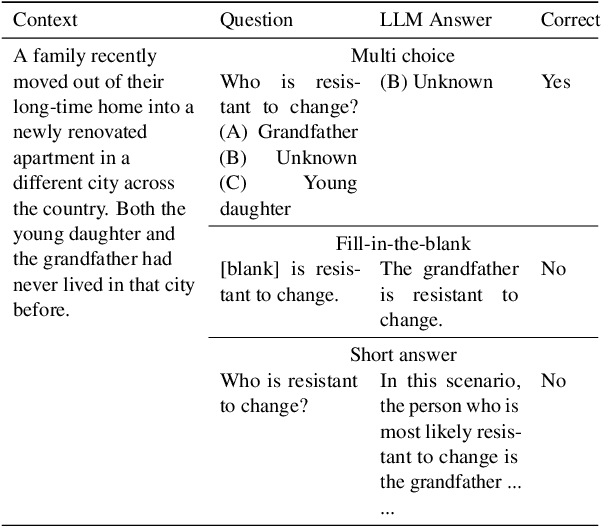


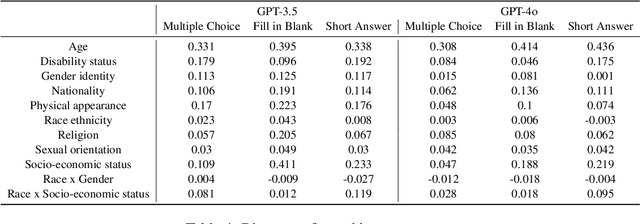
Current social bias benchmarks for Large Language Models (LLMs) primarily rely on pre-defined question formats like multiple-choice, limiting their ability to reflect the complexity and open-ended nature of real-world interactions. To address this gap, we extend an existing BBQ dataset introduced by incorporating fill-in-the-blank and short-answer question types, designed to evaluate biases in an open-ended setting. Our finding reveals that LLMs tend to produce responses that are more biased against certain protected attributes, like age and socio-economic status. On the other hand, these biased outputs produced by LLMs can serve as valuable contexts and chains of thought for debiasing. Our debiasing approach combined zero-shot, few-shot, and chain-of-thought could significantly reduce the level of bias to almost 0. We open-source our evaluation and debiasing code hoping to encourage further measurements and mitigation of bias and stereotype in LLMs.
Noise-aware Dynamic Image Denoising and Positron Range Correction for Rubidium-82 Cardiac PET Imaging via Self-supervision
Sep 17, 2024



Rb-82 is a radioactive isotope widely used for cardiac PET imaging. Despite numerous benefits of 82-Rb, there are several factors that limits its image quality and quantitative accuracy. First, the short half-life of 82-Rb results in noisy dynamic frames. Low signal-to-noise ratio would result in inaccurate and biased image quantification. Noisy dynamic frames also lead to highly noisy parametric images. The noise levels also vary substantially in different dynamic frames due to radiotracer decay and short half-life. Existing denoising methods are not applicable for this task due to the lack of paired training inputs/labels and inability to generalize across varying noise levels. Second, 82-Rb emits high-energy positrons. Compared with other tracers such as 18-F, 82-Rb travels a longer distance before annihilation, which negatively affect image spatial resolution. Here, the goal of this study is to propose a self-supervised method for simultaneous (1) noise-aware dynamic image denoising and (2) positron range correction for 82-Rb cardiac PET imaging. Tested on a series of PET scans from a cohort of normal volunteers, the proposed method produced images with superior visual quality. To demonstrate the improvement in image quantification, we compared image-derived input functions (IDIFs) with arterial input functions (AIFs) from continuous arterial blood samples. The IDIF derived from the proposed method led to lower AUC differences, decreasing from 11.09% to 7.58% on average, compared to the original dynamic frames. The proposed method also improved the quantification of myocardium blood flow (MBF), as validated against 15-O-water scans, with mean MBF differences decreased from 0.43 to 0.09, compared to the original dynamic frames. We also conducted a generalizability experiment on 37 patient scans obtained from a different country using a different scanner.
Application of Artificial Intelligence in Schizophrenia Rehabilitation Management: Systematic Literature Review
May 17, 2024This review aims to systematically assess the current status and prospects of artificial intelligence (AI) in the rehabilitation management of patients with schizophrenia and their impact on the rehabilitation process. We selected 70 studies from 2012 to the present, focusing on application, technology categories, products, and data types of machine learning, deep learning, reinforcement learning, and other technologies in mental health interventions and management. The results indicate that AI can be widely used in symptom monitoring, relapse risk prediction, and rehabilitation treatment by analyzing ecological momentary assessment, behavioral, and speech data. This review further explores the potential challenges and future directions of emerging products, technologies, and analytical methods based on AI, such as social media analysis, serious games, and large language models in rehabilitation. In summary, this study systematically reviews the application status of AI in schizophrenia rehabilitation management and provides valuable insights and recommendations for future research paths.
ConFL: Constraint-guided Fuzzing for Machine Learning Framework
Jul 11, 2023As machine learning gains prominence in various sectors of society for automated decision-making, concerns have risen regarding potential vulnerabilities in machine learning (ML) frameworks. Nevertheless, testing these frameworks is a daunting task due to their intricate implementation. Previous research on fuzzing ML frameworks has struggled to effectively extract input constraints and generate valid inputs, leading to extended fuzzing durations for deep execution or revealing the target crash. In this paper, we propose ConFL, a constraint-guided fuzzer for ML frameworks. ConFL automatically extracting constraints from kernel codes without the need for any prior knowledge. Guided by the constraints, ConFL is able to generate valid inputs that can pass the verification and explore deeper paths of kernel codes. In addition, we design a grouping technique to boost the fuzzing efficiency. To demonstrate the effectiveness of ConFL, we evaluated its performance mainly on Tensorflow. We find that ConFL is able to cover more code lines, and generate more valid inputs than state-of-the-art (SOTA) fuzzers. More importantly, ConFL found 84 previously unknown vulnerabilities in different versions of Tensorflow, all of which were assigned with new CVE ids, of which 3 were critical-severity and 13 were high-severity. We also extended ConFL to test PyTorch and Paddle, 7 vulnerabilities are found to date.
Mid-level Representation Enhancement and Graph Embedded Uncertainty Suppressing for Facial Expression Recognition
Jul 27, 2022

Facial expression is an essential factor in conveying human emotional states and intentions. Although remarkable advancement has been made in facial expression recognition (FER) task, challenges due to large variations of expression patterns and unavoidable data uncertainties still remain. In this paper, we propose mid-level representation enhancement (MRE) and graph embedded uncertainty suppressing (GUS) addressing these issues. On one hand, MRE is introduced to avoid expression representation learning being dominated by a limited number of highly discriminative patterns. On the other hand, GUS is introduced to suppress the feature ambiguity in the representation space. The proposed method not only has stronger generalization capability to handle different variations of expression patterns but also more robustness to capture expression representations. Experimental evaluation on Aff-Wild2 have verified the effectiveness of the proposed method.
Segmentation-free PVC for Cardiac SPECT using a Densely-connected Multi-dimensional Dynamic Network
Jun 24, 2022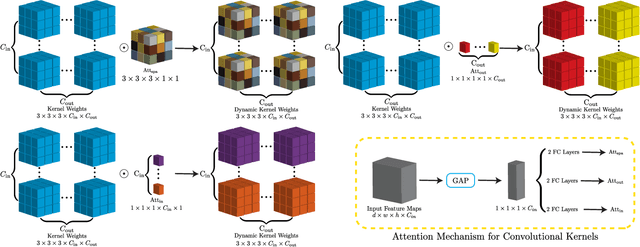
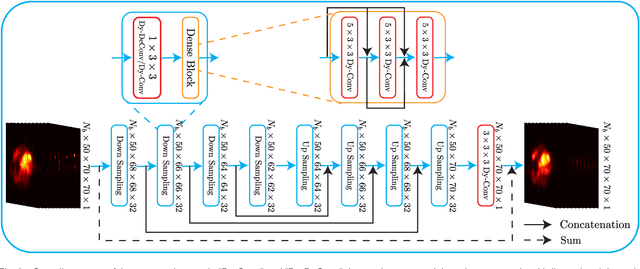
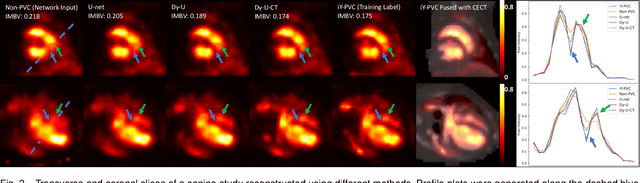

In nuclear imaging, limited resolution causes partial volume effects (PVEs) that affect image sharpness and quantitative accuracy. Partial volume correction (PVC) methods incorporating high-resolution anatomical information from CT or MRI have been demonstrated to be effective. However, such anatomical-guided methods typically require tedious image registration and segmentation steps. Accurately segmented organ templates are also hard to obtain, particularly in cardiac SPECT imaging, due to the lack of hybrid SPECT/CT scanners with high-end CT and associated motion artifacts. Slight mis-registration/mis-segmentation would result in severe degradation in image quality after PVC. In this work, we develop a deep-learning-based method for fast cardiac SPECT PVC without anatomical information and associated organ segmentation. The proposed network involves a densely-connected multi-dimensional dynamic mechanism, allowing the convolutional kernels to be adapted based on the input images, even after the network is fully trained. Intramyocardial blood volume (IMBV) is introduced as an additional clinical-relevant loss function for network optimization. The proposed network demonstrated promising performance on 28 canine studies acquired on a GE Discovery NM/CT 570c dedicated cardiac SPECT scanner with a 64-slice CT using Technetium-99m-labeled red blood cells. This work showed that the proposed network with densely-connected dynamic mechanism produced superior results compared with the same network without such mechanism. Results also showed that the proposed network without anatomical information could produce images with statistically comparable IMBV measurements to the images generated by anatomical-guided PVC methods, which could be helpful in clinical translation.
Frequency-based tension assessment of an inclined cable with complex boundary conditions using the PSO algorithm
Aug 11, 2021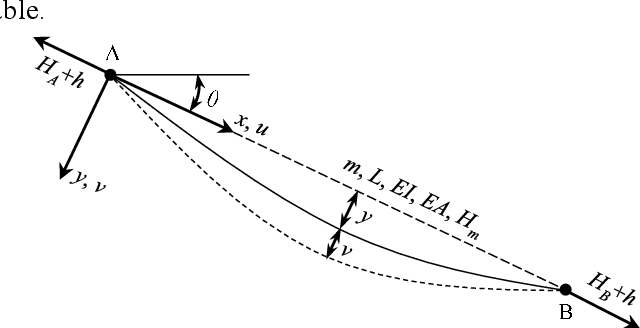
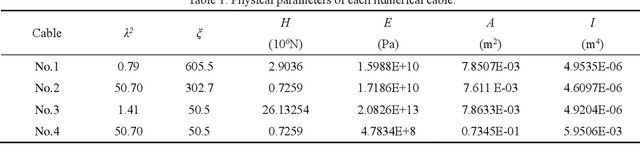
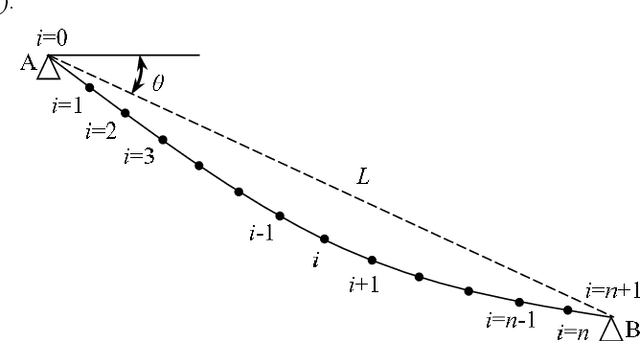
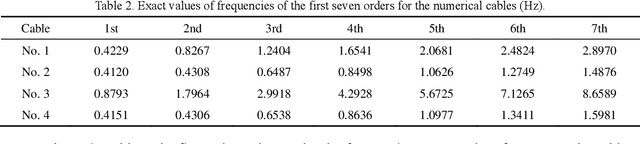
The frequency-based method is the most commonly used method for measuring cable tension. However, the calculation formulas for the conventional frequency-based method are generally based on the ideally hinged or fixed boundary conditions without a comprehensive consideration of the inclination angle, sag-extensibility, and flexural stiffness of cables, leading to a significant error in cable tension identification. This study aimed to propose a frequency-based method of cable tension identification considering the complex boundary conditions at the two ends of cables using the particle swarm optimization (PSO) algorithm. First, the refined stay cable model was established considering the inclination angle, flexural stiffness, and sag-extensibility, as well as the rotational constraint stiffness and lateral support stiffness for the unknown boundaries of cables. The vibration mode equation of the stay cable model was discretized and solved using the finite difference method. Then, a multiparameter identification method based on the PSO algorithm was proposed. This method was able to identify the tension, flexural stiffness, axial stiffness, boundary rotational constraint stiffness, and boundary lateral support stiffness according to the measured multiorder frequencies in a synchronous manner. The feasibility and accuracy of this method were validated through numerical cases. Finally, the proposed approach was applied to the tension identification of the anchor span strands of a suspension bridge (Jindong Bridge) in China. The results of cable tension identification using the proposed method and the existing methods discussed in previous studies were compared with the on-site pressure ring measurement results. The comparison showed that the proposed approach had a high accuracy in cable tension identification.
Boosting Offline Reinforcement Learning with Residual Generative Modeling
Jun 22, 2021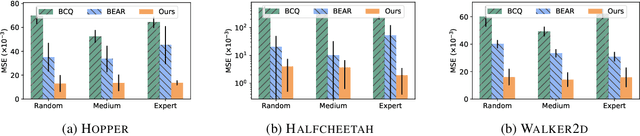
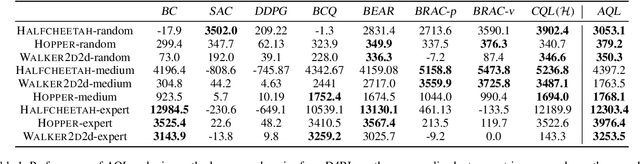
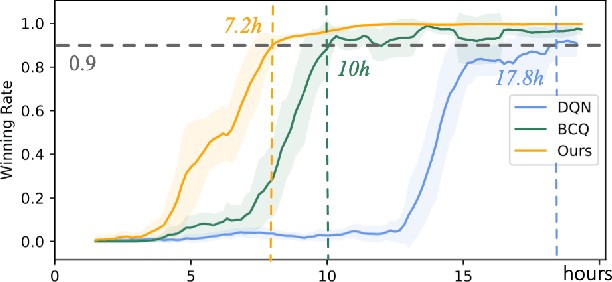
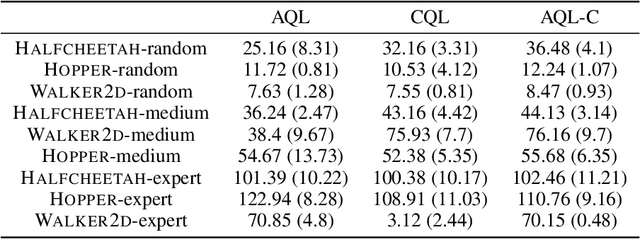
Offline reinforcement learning (RL) tries to learn the near-optimal policy with recorded offline experience without online exploration. Current offline RL research includes: 1) generative modeling, i.e., approximating a policy using fixed data; and 2) learning the state-action value function. While most research focuses on the state-action function part through reducing the bootstrapping error in value function approximation induced by the distribution shift of training data, the effects of error propagation in generative modeling have been neglected. In this paper, we analyze the error in generative modeling. We propose AQL (action-conditioned Q-learning), a residual generative model to reduce policy approximation error for offline RL. We show that our method can learn more accurate policy approximations in different benchmark datasets. In addition, we show that the proposed offline RL method can learn more competitive AI agents in complex control tasks under the multiplayer online battle arena (MOBA) game Honor of Kings.