 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Synergy-Driven Iterative Visual Narrative Synthesis
Jul 17, 2025Automated generation of high-quality media presentations is challenging, requiring robust content extraction, narrative planning, visual design, and overall quality optimization. Existing methods often produce presentations with logical inconsistencies and suboptimal layouts, thereby struggling to meet professional standards. To address these challenges, we introduce RCPS (Reflective Coherent Presentation Synthesis), a novel framework integrating three key components: (1) Deep Structured Narrative Planning; (2) Adaptive Layout Generation; (3) an Iterative Optimization Loop. Additionally, we propose PREVAL, a preference-based evaluation framework employing rationale-enhanced multi-dimensional models to assess presentation quality across Content, Coherence, and Design. Experimental results demonstrate that RCPS significantly outperforms baseline methods across all quality dimensions, producing presentations that closely approximate human expert standards. PREVAL shows strong correlation with human judgments, validating it as a reliable automated tool for assessing presentation quality.
Hybrid Robot Learning for Automatic Robot Motion Planning in Manufacturing
Feb 26, 2025Industrial robots are widely used in diverse manufacturing environments. Nonetheless, how to enable robots to automatically plan trajectories for changing tasks presents a considerable challenge. Further complexities arise when robots operate within work cells alongside machines, humans, or other robots. This paper introduces a multi-level hybrid robot motion planning method combining a task space Reinforcement Learning-based Learning from Demonstration (RL-LfD) agent and a joint-space based Deep Reinforcement Learning (DRL) based agent. A higher level agent learns to switch between the two agents to enable feasible and smooth motion. The feasibility is computed by incorporating reachability, joint limits, manipulability, and collision risks of the robot in the given environment. Therefore, the derived hybrid motion planning policy generates a feasible trajectory that adheres to task constraints. The effectiveness of the method is validated through sim ulated robotic scenarios and in a real-world setup.
Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models
Nov 29, 2024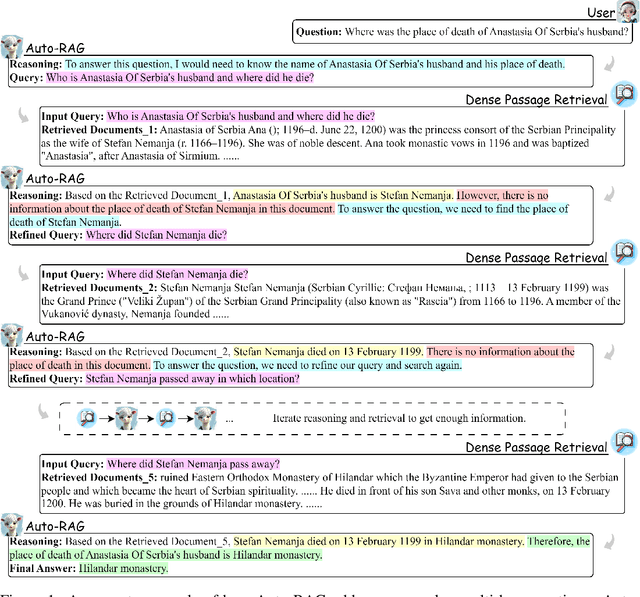

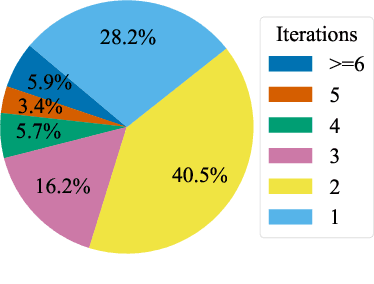

Iterative retrieval refers to the process in which the model continuously queries the retriever during generation to enhance the relevance of the retrieved knowledge, thereby improving the performance of Retrieval-Augmented Generation (RAG). Existing work typically employs few-shot prompting or manually constructed rules to implement iterative retrieval. This introduces additional inference overhead and overlooks the remarkable reasoning capabilities of Large Language Models (LLMs). In this paper, we introduce Auto-RAG, an autonomous iterative retrieval model centered on the LLM's powerful decision-making capabilities. Auto-RAG engages in multi-turn dialogues with the retriever, systematically planning retrievals and refining queries to acquire valuable knowledge. This process continues until sufficient external information is gathered, at which point the results are presented to the user. To this end, we develop a method for autonomously synthesizing reasoning-based decision-making instructions in iterative retrieval and fine-tuned the latest open-source LLMs. The experimental results indicate that Auto-RAG is capable of autonomous iterative interaction with the retriever, effectively leveraging the remarkable reasoning and decision-making abilities of LLMs, which lead to outstanding performance across six benchmarks. Further analysis reveals that Auto-RAG can autonomously adjust the number of iterations based on the difficulty of the questions and the utility of the retrieved knowledge, without requiring any human intervention. Moreover, Auto-RAG expresses the iterative retrieval process in natural language, enhancing interpretability while providing users with a more intuitive experience\footnote{Code is available at \url{https://github.com/ictnlp/Auto-RAG}.
Tractography with T1-weighted MRI and associated anatomical constraints on clinical quality diffusion MRI
Mar 27, 2024Diffusion MRI (dMRI) streamline tractography, the gold standard for in vivo estimation of brain white matter (WM) pathways, has long been considered indicative of macroscopic relationships with WM microstructure. However, recent advances in tractography demonstrated that convolutional recurrent neural networks (CoRNN) trained with a teacher-student framework have the ability to learn and propagate streamlines directly from T1 and anatomical contexts. Training for this network has previously relied on high-resolution dMRI. In this paper, we generalize the training mechanism to traditional clinical resolution data, which allows generalizability across sensitive and susceptible study populations. We train CoRNN on a small subset of the Baltimore Longitudinal Study of Aging (BLSA), which better resembles clinical protocols. Then, we define a metric, termed the epsilon ball seeding method, to compare T1 tractography and traditional diffusion tractography at the streamline level. Under this metric, T1 tractography generated by CoRNN reproduces diffusion tractography with approximately two millimeters of error.
Truth-Aware Context Selection: Mitigating the Hallucinations of Large Language Models Being Misled by Untruthful Contexts
Mar 14, 2024



Although large language models (LLMs) have demonstrated impressive text generation capabilities, they are easily misled by the untruthful context provided by users or knowledge augmentation tools, thereby producing hallucinations. To alleviate the LLMs from being misled by untruthful information and take advantage of knowledge augmentation, we propose Truth-Aware Context Selection (TACS), a lightweight method to shield untruthful context from the inputs. TACS begins by performing truth detection on the input context, leveraging the parameterized knowledge within the LLM. Subsequently, it constructs a corresponding attention mask based on the truthfulness of each position, selecting the truthful context and discarding the untruthful context. Additionally, we introduce a new evaluation metric, Disturbance Adaption Rate, to further study the LLMs' ability to accept truthful information and resist untruthful information. Experimental results show that TACS can effectively filter information in context and significantly improve the overall quality of LLMs' responses when presented with misleading information.
TruthX: Alleviating Hallucinations by Editing Large Language Models in Truthful Space
Feb 27, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks. However, they sometimes suffer from producing hallucinations, particularly in cases where they may generate untruthful responses despite possessing the correct knowledge. In this paper, we propose TruthX, an inference-time method to elicit the truthfulness of LLMs by editing their internal representations in truthful space. TruthX employs an auto-encoder to map LLM's representations into semantic and truthful latent spaces respectively, and applies contrastive learning to identify a truthful editing direction within the truthful space. During inference, by editing LLM's internal representations in truthful space, TruthX effectively enhances the truthfulness of LLMs. Experiments show that TruthX effectively improves the truthfulness of 13 advanced LLMs by an average of 20% on TruthfulQA benchmark. Further analyses suggest that the truthful space acquired by TruthX plays a pivotal role in controlling LLM to produce truthful or hallucinatory responses.
ConFL: Constraint-guided Fuzzing for Machine Learning Framework
Jul 11, 2023As machine learning gains prominence in various sectors of society for automated decision-making, concerns have risen regarding potential vulnerabilities in machine learning (ML) frameworks. Nevertheless, testing these frameworks is a daunting task due to their intricate implementation. Previous research on fuzzing ML frameworks has struggled to effectively extract input constraints and generate valid inputs, leading to extended fuzzing durations for deep execution or revealing the target crash. In this paper, we propose ConFL, a constraint-guided fuzzer for ML frameworks. ConFL automatically extracting constraints from kernel codes without the need for any prior knowledge. Guided by the constraints, ConFL is able to generate valid inputs that can pass the verification and explore deeper paths of kernel codes. In addition, we design a grouping technique to boost the fuzzing efficiency. To demonstrate the effectiveness of ConFL, we evaluated its performance mainly on Tensorflow. We find that ConFL is able to cover more code lines, and generate more valid inputs than state-of-the-art (SOTA) fuzzers. More importantly, ConFL found 84 previously unknown vulnerabilities in different versions of Tensorflow, all of which were assigned with new CVE ids, of which 3 were critical-severity and 13 were high-severity. We also extended ConFL to test PyTorch and Paddle, 7 vulnerabilities are found to date.
Edge Deep Learning Enabled Freezing of Gait Detection in Parkinson's Patients
Nov 27, 2022


This paper presents the design of a wireless sensor network for detecting and alerting the freezing of gait (FoG) symptoms in patients with Parkinson's disease. Three sensor nodes, each integrating a 3-axis accelerometer, can be placed on a patient at ankle, thigh, and truck. Each sensor node can independently detect FoG using an on-device deep learning (DL) model, featuring a squeeze and excitation convolutional neural network (CNN). In a validation using a public dataset, the prototype developed achieved a FoG detection sensitivity of 88.8% and an F1 score of 85.34%, using less than 20 k trainable parameters per sensor node. Once FoG is detected, an auditory signal will be generated to alert users, and the alarm signal will also be sent to mobile phones for further actions if needed. The sensor node can be easily recharged wirelessly by inductive coupling. The system is self-contained and processes all user data locally without streaming data to external devices or the cloud, thus eliminating the cybersecurity risks and power penalty associated with wireless data transmission. The developed methodology can be used in a wide range of applications.
Mastering the working sequence in human-robot collaborative assembly based on reinforcement learning
Jul 08, 2020



A long-standing goal of the Human-Robot Collaboration (HRC) in manufacturing systems is to increase the collaborative working efficiency. In line with the trend of Industry 4.0 to build up the smart manufacturing system, the Co-robot in the HRC system deserves better designing to be more self-organized and to find the superhuman proficiency by self-learning. Inspired by the impressive machine learning algorithms developed by Google Deep Mind like Alphago Zero, in this paper, the human-robot collaborative assembly working process is formatted into a chessboard and the selection of moves in the chessboard is used to analogize the decision making by both human and robot in the HRC assembly working process. To obtain the optimal policy of working sequence to maximize the working efficiency, the robot is trained with a self-play algorithm based on reinforcement learning, without guidance or domain knowledge beyond game rules. A neural network is also trained to predict the distribution of the priority of move selections and whether a working sequence is the one resulting in the maximum of the HRC efficiency. An adjustable desk assembly is used to demonstrate the proposed HRC assembly algorithm and its efficiency.