 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD$^2$-LIO: Enhanced Optimization for LiDAR-IMU Odometry Considering Directional Degeneracy
Aug 20, 2025LiDAR-inertial odometry (LIO) plays a vital role in achieving accurate localization and mapping, especially in complex environments. However, the presence of LiDAR feature degeneracy poses a major challenge to reliable state estimation. To overcome this issue, we propose an enhanced LIO framework that integrates adaptive outlier-tolerant correspondence with a scan-to-submap registration strategy. The core contribution lies in an adaptive outlier removal threshold, which dynamically adjusts based on point-to-sensor distance and the motion amplitude of platform. This mechanism improves the robustness of feature matching in varying conditions. Moreover, we introduce a flexible scan-to-submap registration method that leverages IMU data to refine pose estimation, particularly in degenerate geometric configurations. To further enhance localization accuracy, we design a novel weighting matrix that fuses IMU preintegration covariance with a degeneration metric derived from the scan-to-submap process. Extensive experiments conducted in both indoor and outdoor environments-characterized by sparse or degenerate features-demonstrate that our method consistently outperforms state-of-the-art approaches in terms of both robustness and accuracy.
A Character-based Diffusion Embedding Algorithm for Enhancing the Generation Quality of Generative Linguistic Steganographic Texts
May 02, 2025Generating high-quality steganographic text is a fundamental challenge in the field of generative linguistic steganography. This challenge arises primarily from two aspects: firstly, the capabilities of existing models in text generation are limited; secondly, embedding algorithms fail to effectively mitigate the negative impacts of sensitive information's properties, such as semantic content or randomness. Specifically, to ensure that the recipient can accurately extract hidden information, embedding algorithms often have to consider selecting candidate words with relatively low probabilities. This phenomenon leads to a decrease in the number of high-probability candidate words and an increase in low-probability candidate words, thereby compromising the semantic coherence and logical fluency of the steganographic text and diminishing the overall quality of the generated steganographic material. To address this issue, this paper proposes a novel embedding algorithm, character-based diffusion embedding algorithm (CDEA). Unlike existing embedding algorithms that strive to eliminate the impact of sensitive information's properties on the generation process, CDEA leverages sensitive information's properties. It enhances the selection frequency of high-probability candidate words in the candidate pool based on general statistical properties at the character level and grouping methods based on power-law distributions, while reducing the selection frequency of low-probability candidate words in the candidate pool. Furthermore, to ensure the effective transformation of sensitive information in long sequences, we also introduce the XLNet model. Experimental results demonstrate that the combination of CDEA and XLNet significantly improves the quality of generated steganographic text, particularly in terms of perceptual-imperceptibility.
EmoDiffusion: Enhancing Emotional 3D Facial Animation with Latent Diffusion Models
Mar 14, 2025Speech-driven 3D facial animation seeks to produce lifelike facial expressions that are synchronized with the speech content and its emotional nuances, finding applications in various multimedia fields. However, previous methods often overlook emotional facial expressions or fail to disentangle them effectively from the speech content. To address these challenges, we present EmoDiffusion, a novel approach that disentangles different emotions in speech to generate rich 3D emotional facial expressions. Specifically, our method employs two Variational Autoencoders (VAEs) to separately generate the upper face region and mouth region, thereby learning a more refined representation of the facial sequence. Unlike traditional methods that use diffusion models to connect facial expression sequences with audio inputs, we perform the diffusion process in the latent space. Furthermore, we introduce an Emotion Adapter to evaluate upper face movements accurately. Given the paucity of 3D emotional talking face data in the animation industry, we capture facial expressions under the guidance of animation experts using LiveLinkFace on an iPhone. This effort results in the creation of an innovative 3D blendshape emotional talking face dataset (3D-BEF) used to train our network. Extensive experiments and perceptual evaluations validate the effectiveness of our approach, confirming its superiority in generating realistic and emotionally rich facial animations.
Task-Specific Knowledge Distillation from the Vision Foundation Model for Enhanced Medical Image Segmentation
Mar 10, 2025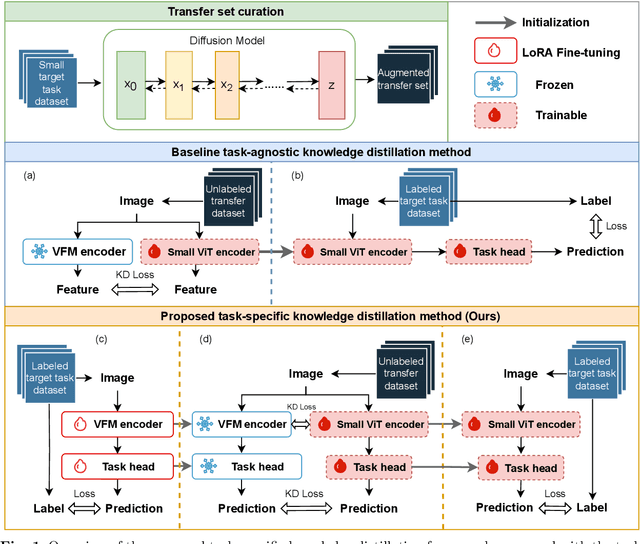
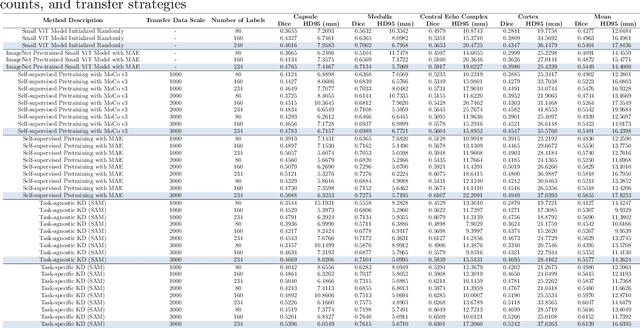
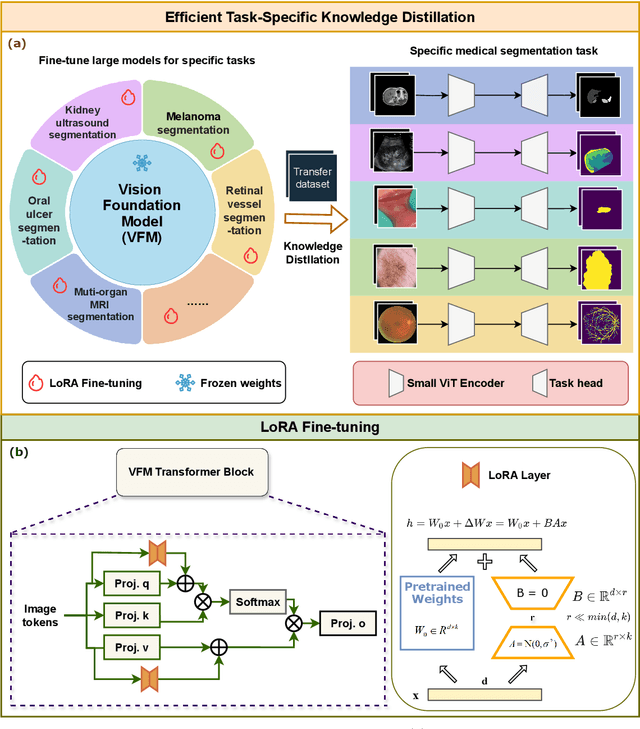
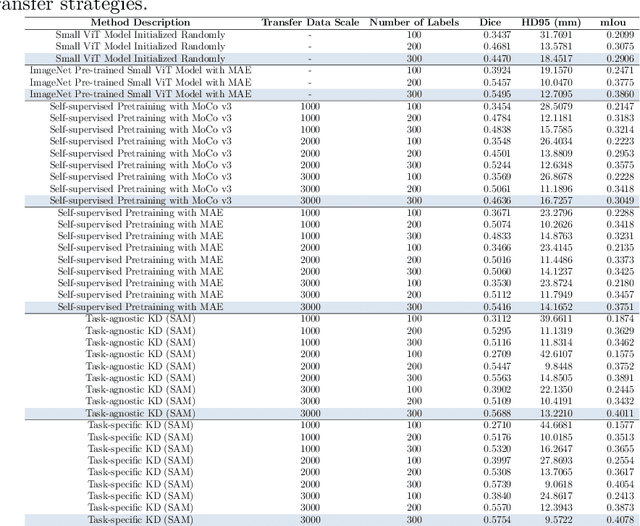
Large-scale pre-trained models, such as Vision Foundation Models (VFMs), have demonstrated impressive performance across various downstream tasks by transferring generalized knowledge, especially when target data is limited. However, their high computational cost and the domain gap between natural and medical images limit their practical application in medical segmentation tasks. Motivated by this, we pose the following important question: "How can we effectively utilize the knowledge of large pre-trained VFMs to train a small, task-specific model for medical image segmentation when training data is limited?" To address this problem, we propose a novel and generalizable task-specific knowledge distillation framework. Our method fine-tunes the VFM on the target segmentation task to capture task-specific features before distilling the knowledge to smaller models, leveraging Low-Rank Adaptation (LoRA) to reduce the computational cost of fine-tuning. Additionally, we incorporate synthetic data generated by diffusion models to augment the transfer set, enhancing model performance in data-limited scenarios. Experimental results across five medical image datasets demonstrate that our method consistently outperforms task-agnostic knowledge distillation and self-supervised pretraining approaches like MoCo v3 and Masked Autoencoders (MAE). For example, on the KidneyUS dataset, our method achieved a 28% higher Dice score than task-agnostic KD using 80 labeled samples for fine-tuning. On the CHAOS dataset, it achieved an 11% improvement over MAE with 100 labeled samples. These results underscore the potential of task-specific knowledge distillation to train accurate, efficient models for medical image segmentation in data-constrained settings.
Spatial-Temporal Perception with Causal Inference for Naturalistic Driving Action Recognition
Mar 06, 2025Naturalistic driving action recognition is essential for vehicle cabin monitoring systems. However, the complexity of real-world backgrounds presents significant challenges for this task, and previous approaches have struggled with practical implementation due to their limited ability to observe subtle behavioral differences and effectively learn inter-frame features from video. In this paper, we propose a novel Spatial-Temporal Perception (STP) architecture that emphasizes both temporal information and spatial relationships between key objects, incorporating a causal decoder to perform behavior recognition and temporal action localization. Without requiring multimodal input, STP directly extracts temporal and spatial distance features from RGB video clips. Subsequently, these dual features are jointly encoded by maximizing the expected likelihood across all possible permutations of the factorization order. By integrating temporal and spatial features at different scales, STP can perceive subtle behavioral changes in challenging scenarios. Additionally, we introduce a causal-aware module to explore relationships between video frame features, significantly enhancing detection efficiency and performance. We validate the effectiveness of our approach using two publicly available driver distraction detection benchmarks. The results demonstrate that our framework achieves state-of-the-art performance.
Pretrained LLMs as Real-Time Controllers for Robot Operated Serial Production Line
Mar 05, 2025The manufacturing industry is undergoing a transformative shift, driven by cutting-edge technologies like 5G, AI, and cloud computing. Despite these advancements, effective system control, which is crucial for optimizing production efficiency, remains a complex challenge due to the intricate, knowledge-dependent nature of manufacturing processes and the reliance on domain-specific expertise. Conventional control methods often demand heavy customization, considerable computational resources, and lack transparency in decision-making. In this work, we investigate the feasibility of using Large Language Models (LLMs), particularly GPT-4, as a straightforward, adaptable solution for controlling manufacturing systems, specifically, mobile robot scheduling. We introduce an LLM-based control framework to assign mobile robots to different machines in robot assisted serial production lines, evaluating its performance in terms of system throughput. Our proposed framework outperforms traditional scheduling approaches such as First-Come-First-Served (FCFS), Shortest Processing Time (SPT), and Longest Processing Time (LPT). While it achieves performance that is on par with state-of-the-art methods like Multi-Agent Reinforcement Learning (MARL), it offers a distinct advantage by delivering comparable throughput without the need for extensive retraining. These results suggest that the proposed LLM-based solution is well-suited for scenarios where technical expertise, computational resources, and financial investment are limited, while decision transparency and system scalability are critical concerns.
Semantic Prior Distillation with Vision Foundation Model for Enhanced Rapid Bone Scintigraphy Image Restoration
Mar 04, 2025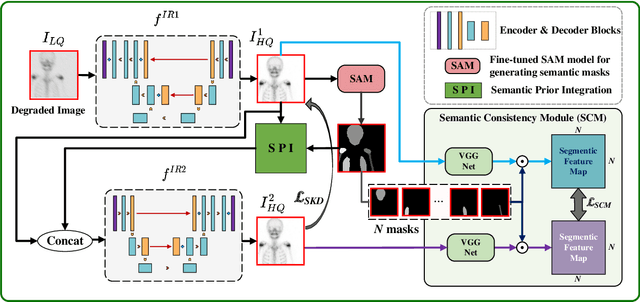
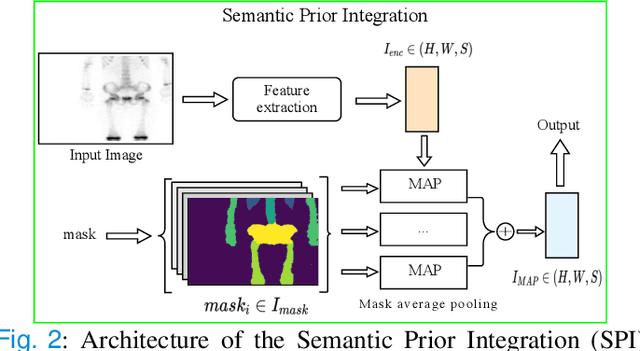
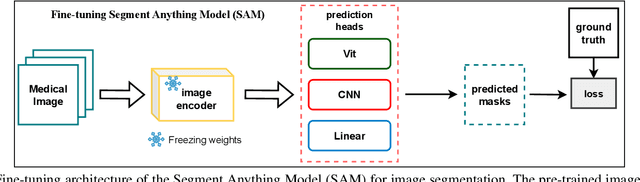
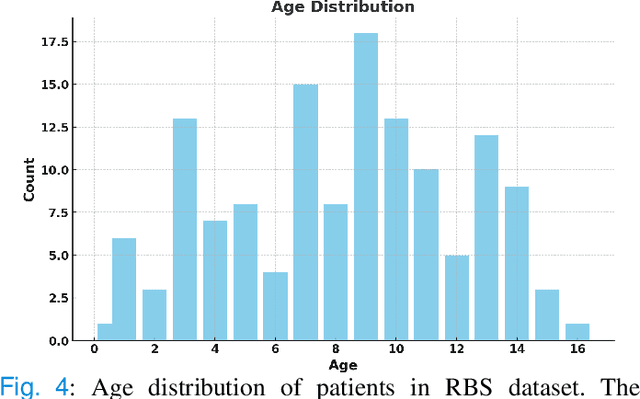
Rapid bone scintigraphy is an essential tool for diagnosing skeletal diseases and tumor metastasis in pediatric patients, as it reduces scan time and minimizes patient discomfort. However, rapid scans often result in poor image quality, potentially affecting diagnosis due to reduced resolution and detail, which make it challenging to identify and evaluate finer anatomical structures. To address this issue, we propose the first application of SAM-based semantic priors for medical image restoration, leveraging the Segment Anything Model (SAM) to enhance rapid bone scintigraphy images in pediatric populations. Our method comprises two cascaded networks, $f^{IR1}$ and $f^{IR2}$, augmented by three key modules: a Semantic Prior Integration (SPI) module, a Semantic Knowledge Distillation (SKD) module, and a Semantic Consistency Module (SCM). The SPI and SKD modules incorporate domain-specific semantic information from a fine-tuned SAM, while the SCM maintains consistent semantic feature representation throughout the cascaded networks. In addition, we will release a novel Rapid Bone Scintigraphy dataset called RBS, the first dataset dedicated to rapid bone scintigraphy image restoration in pediatric patients. RBS consists of 137 pediatric patients aged between 0.5 and 16 years who underwent both standard and rapid bone scans. The dataset includes scans performed at 20 cm/min (standard) and 40 cm/min (rapid), representing a $2\times$ acceleration. We conducted extensive experiments on both the publicly available endoscopic dataset and RBS. The results demonstrate that our method outperforms all existing methods across various metrics, including PSNR, SSIM, FID, and LPIPS.
Hybrid Robot Learning for Automatic Robot Motion Planning in Manufacturing
Feb 26, 2025Industrial robots are widely used in diverse manufacturing environments. Nonetheless, how to enable robots to automatically plan trajectories for changing tasks presents a considerable challenge. Further complexities arise when robots operate within work cells alongside machines, humans, or other robots. This paper introduces a multi-level hybrid robot motion planning method combining a task space Reinforcement Learning-based Learning from Demonstration (RL-LfD) agent and a joint-space based Deep Reinforcement Learning (DRL) based agent. A higher level agent learns to switch between the two agents to enable feasible and smooth motion. The feasibility is computed by incorporating reachability, joint limits, manipulability, and collision risks of the robot in the given environment. Therefore, the derived hybrid motion planning policy generates a feasible trajectory that adheres to task constraints. The effectiveness of the method is validated through sim ulated robotic scenarios and in a real-world setup.
Vision Foundation Models in Medical Image Analysis: Advances and Challenges
Feb 21, 2025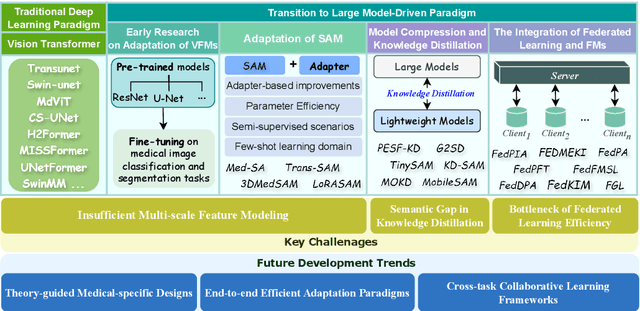
The rapid development of Vision Foundation Models (VFMs), particularly Vision Transformers (ViT) and Segment Anything Model (SAM), has sparked significant advances in the field of medical image analysis. These models have demonstrated exceptional capabilities in capturing long-range dependencies and achieving high generalization in segmentation tasks. However, adapting these large models to medical image analysis presents several challenges, including domain differences between medical and natural images, the need for efficient model adaptation strategies, and the limitations of small-scale medical datasets. This paper reviews the state-of-the-art research on the adaptation of VFMs to medical image segmentation, focusing on the challenges of domain adaptation, model compression, and federated learning. We discuss the latest developments in adapter-based improvements, knowledge distillation techniques, and multi-scale contextual feature modeling, and propose future directions to overcome these bottlenecks. Our analysis highlights the potential of VFMs, along with emerging methodologies such as federated learning and model compression, to revolutionize medical image analysis and enhance clinical applications. The goal of this work is to provide a comprehensive overview of current approaches and suggest key areas for future research that can drive the next wave of innovation in medical image segmentation.
Topology-Aware Wavelet Mamba for Airway Structure Segmentation in Postoperative Recurrent Nasopharyngeal Carcinoma CT Scans
Feb 20, 2025Nasopharyngeal carcinoma (NPC) patients often undergo radiotherapy and chemotherapy, which can lead to postoperative complications such as limited mouth opening and joint stiffness, particularly in recurrent cases that require re-surgery. These complications can affect airway function, making accurate postoperative airway risk assessment essential for managing patient care. Accurate segmentation of airway-related structures in postoperative CT scans is crucial for assessing these risks. This study introduces TopoWMamba (Topology-aware Wavelet Mamba), a novel segmentation model specifically designed to address the challenges of postoperative airway risk evaluation in recurrent NPC patients. TopoWMamba combines wavelet-based multi-scale feature extraction, state-space sequence modeling, and topology-aware modules to segment airway-related structures in CT scans robustly. By leveraging the Wavelet-based Mamba Block (WMB) for hierarchical frequency decomposition and the Snake Conv VSS (SCVSS) module to preserve anatomical continuity, TopoWMamba effectively captures both fine-grained boundaries and global structural context, crucial for accurate segmentation in complex postoperative scenarios. Through extensive testing on the NPCSegCT dataset, TopoWMamba achieves an average Dice score of 88.02%, outperforming existing models such as UNet, Attention UNet, and SwinUNet. Additionally, TopoWMamba is tested on the SegRap 2023 Challenge dataset, where it shows a significant improvement in trachea segmentation with a Dice score of 95.26%. The proposed model provides a strong foundation for automated segmentation, enabling more accurate postoperative airway risk evaluation.