 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Asynchronous Two-Speed Kalman Filter for Real-Time UUV Cooperative Navigation Under Acoustic Delays
Apr 03, 2026In GNSS-denied underwater environments, individual unmanned underwater vehicles (UUVs) suffer from unbounded dead-reckoning drift, making collaborative navigation crucial for accurate state estimation. However, the severe communication delay inherent in underwater acoustic channels poses serious challenges to real-time state estimation. Traditional filters, such as Extended Kalman Filters (EKF) or Unscented Kalman Filters (UKF), usually block the main control loop while waiting for delayed data, or completely discard Out-of-Sequence Measurements (OOSM), resulting in serious drift. To address this, we propose an Asynchronous Two-Speed Kalman Filter (TSKF) enhanced by a novel projection mechanism, which we term Variational History Distillation (VHD). The proposed architecture decouples the estimation process into two parallel threads: a fast-rate thread that utilizes Gaussian Process (GP) compensated dead reckoning to guarantee high-frequency real-time control, and a slow-rate thread dedicated to processing asynchronously delayed collaborative information. By introducing a finite-length State Buffer, the algorithm applies delayed measurements (t-T) to their corresponding historical states, and utilizes a VHD-based projection to fast-forward the correction to the current time without computationally heavy recalculations. Simulation results demonstrate that the proposed TSKF maintains trajectory Root Mean Square Error (RMSE) comparable to computationally intensive batch-optimization methods under severe delays (up to 30 s). Executing in sub-millisecond time, it significantly outperforms standard EKF/UKF. The results demonstrate an effective control, communication, and computing (3C) co-design that significantly enhances the resilience of autonomous marine automation systems.
Communication Outage-Resistant UUV State Estimation: A Variational History Distillation Approach
Mar 31, 2026The reliable operation of Unmanned Underwater Vehicle (UUV) clusters is highly dependent on continuous acoustic communication. However, this communication method is highly susceptible to intermittent interruptions. When communication outages occur, standard state estimators such as the Unscented Kalman Filter (UKF) will be forced to make open-loop predictions. If the environment contains unmodeled dynamic factors, such as unknown ocean currents, this estimation error will grow rapidly, which may eventually lead to mission failure. To address this critical issue, this paper proposes a Variational History Distillation (VHD) approach. VHD regards trajectory prediction as an approximate Bayesian reasoning process, which links a standard motion model based on physics with a pattern extracted directly from the past trajectory of the UUV. This is achieved by synthesizing ``virtual measurements'' distilled from historical trajectories. Recognizing that the reliability of extrapolated historical trends degrades over extended prediction horizons, an adaptive confidence mechanism is introduced. This mechanism allows the filter to gradually reduce the trust of virtual measurements as the communication outage time is extended. Extensive Monte Carlo simulations in a high-fidelity environment demonstrate that the proposed method achieves a 91\% reduction in prediction Root Mean Square Error (RMSE), reducing the error from approximately 170 m to 15 m during a 40-second communication outage. These results demonstrate that VHD can maintain robust state estimation performance even under complete communication loss.
Dental3R: Geometry-Aware Pairing for Intraoral 3D Reconstruction from Sparse-View Photographs
Nov 18, 2025Intraoral 3D reconstruction is fundamental to digital orthodontics, yet conventional methods like intraoral scanning are inaccessible for remote tele-orthodontics, which typically relies on sparse smartphone imagery. While 3D Gaussian Splatting (3DGS) shows promise for novel view synthesis, its application to the standard clinical triad of unposed anterior and bilateral buccal photographs is challenging. The large view baselines, inconsistent illumination, and specular surfaces common in intraoral settings can destabilize simultaneous pose and geometry estimation. Furthermore, sparse-view photometric supervision often induces a frequency bias, leading to over-smoothed reconstructions that lose critical diagnostic details. To address these limitations, we propose \textbf{Dental3R}, a pose-free, graph-guided pipeline for robust, high-fidelity reconstruction from sparse intraoral photographs. Our method first constructs a Geometry-Aware Pairing Strategy (GAPS) to intelligently select a compact subgraph of high-value image pairs. The GAPS focuses on correspondence matching, thereby improving the stability of the geometry initialization and reducing memory usage. Building on the recovered poses and point cloud, we train the 3DGS model with a wavelet-regularized objective. By enforcing band-limited fidelity using a discrete wavelet transform, our approach preserves fine enamel boundaries and interproximal edges while suppressing high-frequency artifacts. We validate our approach on a large-scale dataset of 950 clinical cases and an additional video-based test set of 195 cases. Experimental results demonstrate that Dental3R effectively handles sparse, unposed inputs and achieves superior novel view synthesis quality for dental occlusion visualization, outperforming state-of-the-art methods.
Silhouette-to-Contour Registration: Aligning Intraoral Scan Models with Cephalometric Radiographs
Nov 18, 2025Reliable 3D-2D alignment between intraoral scan (IOS) models and lateral cephalometric radiographs is critical for orthodontic diagnosis, yet conventional intensity-driven registration methods struggle under real clinical conditions, where cephalograms exhibit projective magnification, geometric distortion, low-contrast dental crowns, and acquisition-dependent variation. These factors hinder the stability of appearance-based similarity metrics and often lead to convergence failures or anatomically implausible alignments. To address these limitations, we propose DentalSCR, a pose-stable, contour-guided framework for accurate and interpretable silhouette-to-contour registration. Our method first constructs a U-Midline Dental Axis (UMDA) to establish a unified cross-arch anatomical coordinate system, thereby stabilizing initialization and standardizing projection geometry across cases. Using this reference frame, we generate radiograph-like projections via a surface-based DRR formulation with coronal-axis perspective and Gaussian splatting, which preserves clinical source-object-detector magnification and emphasizes external silhouettes. Registration is then formulated as a 2D similarity transform optimized with a symmetric bidirectional Chamfer distance under a hierarchical coarse-to-fine schedule, enabling both large capture range and subpixel-level contour agreement. We evaluate DentalSCR on 34 expert-annotated clinical cases. Experimental results demonstrate substantial reductions in landmark error-particularly at posterior teeth-tighter dispersion on the lower jaw, and low Chamfer and controlled Hausdorff distances at the curve level. These findings indicate that DentalSCR robustly handles real-world cephalograms and delivers high-fidelity, clinically inspectable 3D--2D alignment, outperforming conventional baselines.
ArchMap: Arch-Flattening and Knowledge-Guided Vision Language Model for Tooth Counting and Structured Dental Understanding
Nov 18, 2025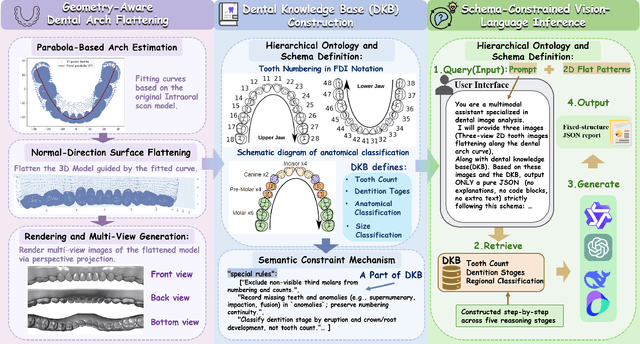
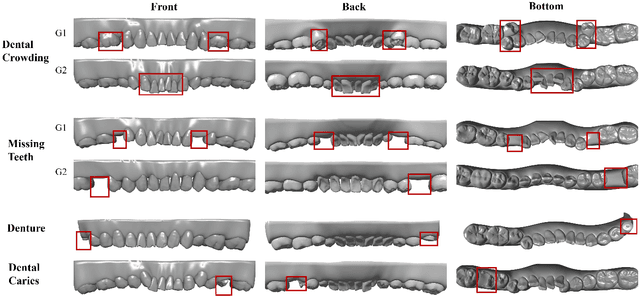
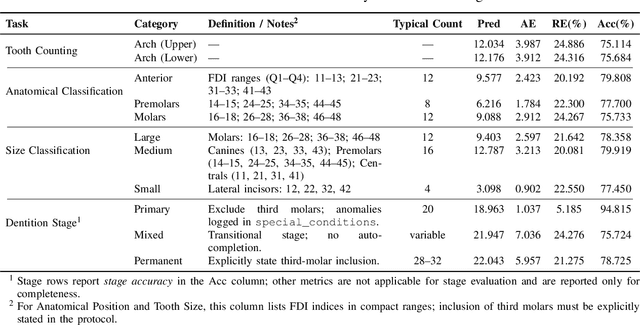
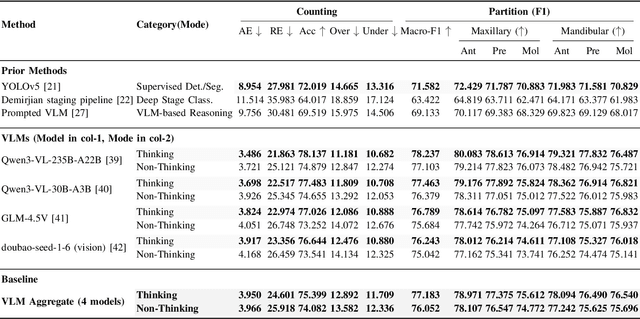
A structured understanding of intraoral 3D scans is essential for digital orthodontics. However, existing deep-learning approaches rely heavily on modality-specific training, large annotated datasets, and controlled scanning conditions, which limit generalization across devices and hinder deployment in real clinical workflows. Moreover, raw intraoral meshes exhibit substantial variation in arch pose, incomplete geometry caused by occlusion or tooth contact, and a lack of texture cues, making unified semantic interpretation highly challenging. To address these limitations, we propose ArchMap, a training-free and knowledge-guided framework for robust structured dental understanding. ArchMap first introduces a geometry-aware arch-flattening module that standardizes raw 3D meshes into spatially aligned, continuity-preserving multi-view projections. We then construct a Dental Knowledge Base (DKB) encoding hierarchical tooth ontology, dentition-stage policies, and clinical semantics to constrain the symbolic reasoning space. We validate ArchMap on 1060 pre-/post-orthodontic cases, demonstrating robust performance in tooth counting, anatomical partitioning, dentition-stage classification, and the identification of clinical conditions such as crowding, missing teeth, prosthetics, and caries. Compared with supervised pipelines and prompted VLM baselines, ArchMap achieves higher accuracy, reduced semantic drift, and superior stability under sparse or artifact-prone conditions. As a fully training-free system, ArchMap demonstrates that combining geometric normalization with ontology-guided multimodal reasoning offers a practical and scalable solution for the structured analysis of 3D intraoral scans in modern digital orthodontics.
EndoWave: Rational-Wavelet 4D Gaussian Splatting for Endoscopic Reconstruction
Oct 27, 2025In robot-assisted minimally invasive surgery, accurate 3D reconstruction from endoscopic video is vital for downstream tasks and improved outcomes. However, endoscopic scenarios present unique challenges, including photometric inconsistencies, non-rigid tissue motion, and view-dependent highlights. Most 3DGS-based methods that rely solely on appearance constraints for optimizing 3DGS are often insufficient in this context, as these dynamic visual artifacts can mislead the optimization process and lead to inaccurate reconstructions. To address these limitations, we present EndoWave, a unified spatio-temporal Gaussian Splatting framework by incorporating an optical flow-based geometric constraint and a multi-resolution rational wavelet supervision. First, we adopt a unified spatio-temporal Gaussian representation that directly optimizes primitives in a 4D domain. Second, we propose a geometric constraint derived from optical flow to enhance temporal coherence and effectively constrain the 3D structure of the scene. Third, we propose a multi-resolution rational orthogonal wavelet as a constraint, which can effectively separate the details of the endoscope and enhance the rendering performance. Extensive evaluations on two real surgical datasets, EndoNeRF and StereoMIS, demonstrate that our method EndoWave achieves state-of-the-art reconstruction quality and visual accuracy compared to the baseline method.
EndoFlow-SLAM: Real-Time Endoscopic SLAM with Flow-Constrained Gaussian Splatting
Jun 26, 2025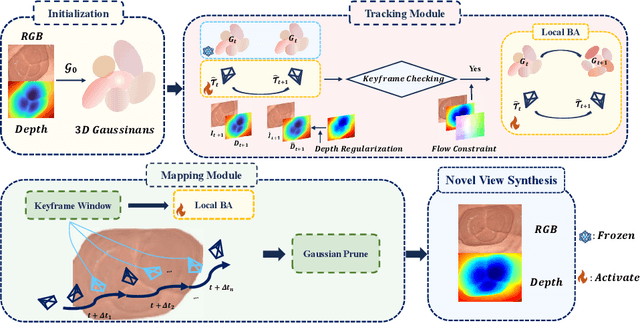
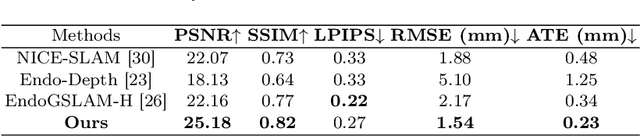
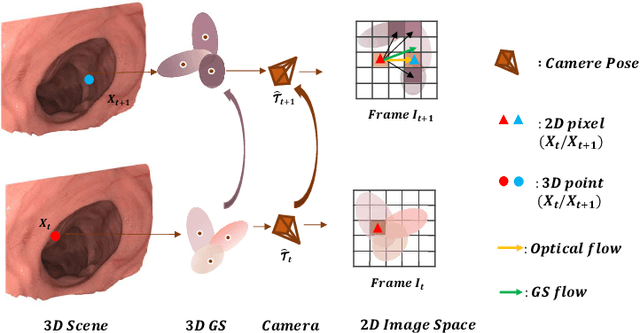
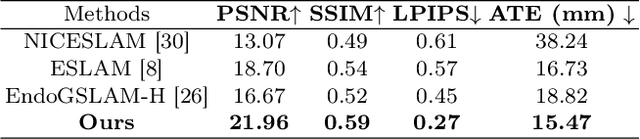
Efficient three-dimensional reconstruction and real-time visualization are critical in surgical scenarios such as endoscopy. In recent years, 3D Gaussian Splatting (3DGS) has demonstrated remarkable performance in efficient 3D reconstruction and rendering. Most 3DGS-based Simultaneous Localization and Mapping (SLAM) methods only rely on the appearance constraints for optimizing both 3DGS and camera poses. However, in endoscopic scenarios, the challenges include photometric inconsistencies caused by non-Lambertian surfaces and dynamic motion from breathing affects the performance of SLAM systems. To address these issues, we additionally introduce optical flow loss as a geometric constraint, which effectively constrains both the 3D structure of the scene and the camera motion. Furthermore, we propose a depth regularisation strategy to mitigate the problem of photometric inconsistencies and ensure the validity of 3DGS depth rendering in endoscopic scenes. In addition, to improve scene representation in the SLAM system, we improve the 3DGS refinement strategy by focusing on viewpoints corresponding to Keyframes with suboptimal rendering quality frames, achieving better rendering results. Extensive experiments on the C3VD static dataset and the StereoMIS dynamic dataset demonstrate that our method outperforms existing state-of-the-art methods in novel view synthesis and pose estimation, exhibiting high performance in both static and dynamic surgical scenes. The source code will be publicly available upon paper acceptance.
Spatial-Temporal Perception with Causal Inference for Naturalistic Driving Action Recognition
Mar 06, 2025



Naturalistic driving action recognition is essential for vehicle cabin monitoring systems. However, the complexity of real-world backgrounds presents significant challenges for this task, and previous approaches have struggled with practical implementation due to their limited ability to observe subtle behavioral differences and effectively learn inter-frame features from video. In this paper, we propose a novel Spatial-Temporal Perception (STP) architecture that emphasizes both temporal information and spatial relationships between key objects, incorporating a causal decoder to perform behavior recognition and temporal action localization. Without requiring multimodal input, STP directly extracts temporal and spatial distance features from RGB video clips. Subsequently, these dual features are jointly encoded by maximizing the expected likelihood across all possible permutations of the factorization order. By integrating temporal and spatial features at different scales, STP can perceive subtle behavioral changes in challenging scenarios. Additionally, we introduce a causal-aware module to explore relationships between video frame features, significantly enhancing detection efficiency and performance. We validate the effectiveness of our approach using two publicly available driver distraction detection benchmarks. The results demonstrate that our framework achieves state-of-the-art performance.
RadarNeXt: Real-Time and Reliable 3D Object Detector Based On 4D mmWave Imaging Radar
Jan 04, 2025



3D object detection is crucial for Autonomous Driving (AD) and Advanced Driver Assistance Systems (ADAS). However, most 3D detectors prioritize detection accuracy, often overlooking network inference speed in practical applications. In this paper, we propose RadarNeXt, a real-time and reliable 3D object detector based on the 4D mmWave radar point clouds. It leverages the re-parameterizable neural networks to catch multi-scale features, reduce memory cost and accelerate the inference. Moreover, to highlight the irregular foreground features of radar point clouds and suppress background clutter, we propose a Multi-path Deformable Foreground Enhancement Network (MDFEN), ensuring detection accuracy while minimizing the sacrifice of speed and excessive number of parameters. Experimental results on View-of-Delft and TJ4DRadSet datasets validate the exceptional performance and efficiency of RadarNeXt, achieving 50.48 and 32.30 mAPs with the variant using our proposed MDFEN. Notably, our RadarNeXt variants achieve inference speeds of over 67.10 FPS on the RTX A4000 GPU and 28.40 FPS on the Jetson AGX Orin. This research demonstrates that RadarNeXt brings a novel and effective paradigm for 3D perception based on 4D mmWave radar.
PLUTO: Pathology-Universal Transformer
May 13, 2024



Pathology is the study of microscopic inspection of tissue, and a pathology diagnosis is often the medical gold standard to diagnose disease. Pathology images provide a unique challenge for computer-vision-based analysis: a single pathology Whole Slide Image (WSI) is gigapixel-sized and often contains hundreds of thousands to millions of objects of interest across multiple resolutions. In this work, we propose PathoLogy Universal TransfOrmer (PLUTO): a light-weight pathology FM that is pre-trained on a diverse dataset of 195 million image tiles collected from multiple sites and extracts meaningful representations across multiple WSI scales that enable a large variety of downstream pathology tasks. In particular, we design task-specific adaptation heads that utilize PLUTO's output embeddings for tasks which span pathology scales ranging from subcellular to slide-scale, including instance segmentation, tile classification, and slide-level prediction. We compare PLUTO's performance to other state-of-the-art methods on a diverse set of external and internal benchmarks covering multiple biologically relevant tasks, tissue types, resolutions, stains, and scanners. We find that PLUTO matches or outperforms existing task-specific baselines and pathology-specific foundation models, some of which use orders-of-magnitude larger datasets and model sizes when compared to PLUTO. Our findings present a path towards a universal embedding to power pathology image analysis, and motivate further exploration around pathology foundation models in terms of data diversity, architectural improvements, sample efficiency, and practical deployability in real-world applications.