 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Speech Language Models by Scaling Supervised Fine-Tuning with Over 60,000 Hours of Synthetic Speech Dialogue Data
Dec 03, 2024



The GPT-4o represents a significant milestone in enabling real-time interaction with large language models (LLMs) through speech, its remarkable low latency and high fluency not only capture attention but also stimulate research interest in the field. This real-time speech interaction is particularly valuable in scenarios requiring rapid feedback and immediate responses, dramatically enhancing user experience. However, there is a notable lack of research focused on real-time large speech language models, particularly for Chinese. In this work, we present KE-Omni, a seamless large speech language model built upon Ke-SpeechChat, a large-scale high-quality synthetic speech interaction dataset consisting of 7 million Chinese and English conversations, featuring 42,002 speakers, and totaling over 60,000 hours, This contributes significantly to the advancement of research and development in this field. The demos can be accessed at \url{https://huggingface.co/spaces/KE-Team/KE-Omni}.
Seismogram Transformer: A generic deep learning backbone network for multiple earthquake monitoring tasks
Oct 02, 2023



Seismic records, known as seismograms, are crucial records of ground motion resulting from seismic events, constituting the backbone of earthquake research and monitoring. The latest advancements in deep learning have significantly facilitated various seismic signal processing tasks. This paper introduces a novel backbone neural network model designed for various seismic monitoring tasks, named Seismogram Transformer (SeisT). Thanks to its efficient network architecture, SeisT matches or even outperforms the state-of-the-art models in earthquake detection, seismic phase picking, first-motion polarity classification, magnitude estimation, and azimuth estimation tasks, particularly in terms of out-of-distribution generalization performance. SeisT consists of multiple network layers composed of different foundational blocks, which help the model understand multi-level feature representations of seismograms from low-level to high-level complex features, effectively extracting features such as frequency, phase, and time-frequency relationships from input seismograms. Three different-sized models were customized based on these diverse foundational modules. Through extensive experiments and performance evaluations, this study showcases the capabilities and potential of SeisT in advancing seismic signal processing and earthquake research.
Towards Better Instruction Following Language Models for Chinese: Investigating the Impact of Training Data and Evaluation
Apr 16, 2023Recently, significant public efforts have been directed towards developing low-cost models with capabilities akin to ChatGPT, thereby fostering the growth of open-source conversational models. However, there remains a scarcity of comprehensive and in-depth evaluations of these models' performance. In this study, we examine the influence of training data factors, including quantity, quality, and linguistic distribution, on model performance. Our analysis is grounded in several publicly accessible, high-quality instruction datasets, as well as our own Chinese multi-turn conversations. We assess various models using a evaluation set of 1,000 samples, encompassing nine real-world scenarios. Our goal is to supplement manual evaluations with quantitative analyses, offering valuable insights for the continued advancement of open-source chat models. Furthermore, to enhance the performance and training and inference efficiency of models in the Chinese domain, we extend the vocabulary of LLaMA - the model with the closest open-source performance to proprietary language models like GPT-3 - and conduct secondary pre-training on 3.4B Chinese words. We make our model, data, as well as code publicly available.
Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases
Mar 26, 2023



The success of ChatGPT has recently attracted numerous efforts to replicate it, with instruction-tuning strategies being a key factor in achieving remarkable results. Instruction-tuning not only significantly enhances the model's performance and generalization but also makes the model's generated results more consistent with human speech patterns. However current research rarely studies the impact of different amounts of instruction data on model performance, especially in the real-world use cases. In this paper we explore the performance of large language models based on instruction tuning across different scales of instruction data. An evaluation dataset consisting of 12 major online use cases is constructed in the experiment. With Bloomz-7B1-mt as the base model, the results show that 1) merely increasing the amount of instruction data leads to continuous improvement in tasks such as open-ended generation, 2) in tasks such as math and code, the model performance curve remains quite flat while increasing data size. We further analyze the possible causes of these phenomena and propose potential future research directions such as effectively selecting high-quality training data, scaling base models and training methods specialized for hard tasks. We will release our training and evaluation datasets, as well as model checkpoints.
Dynamical softassign and adaptive parameter tuning for graph matching
Aug 17, 2022

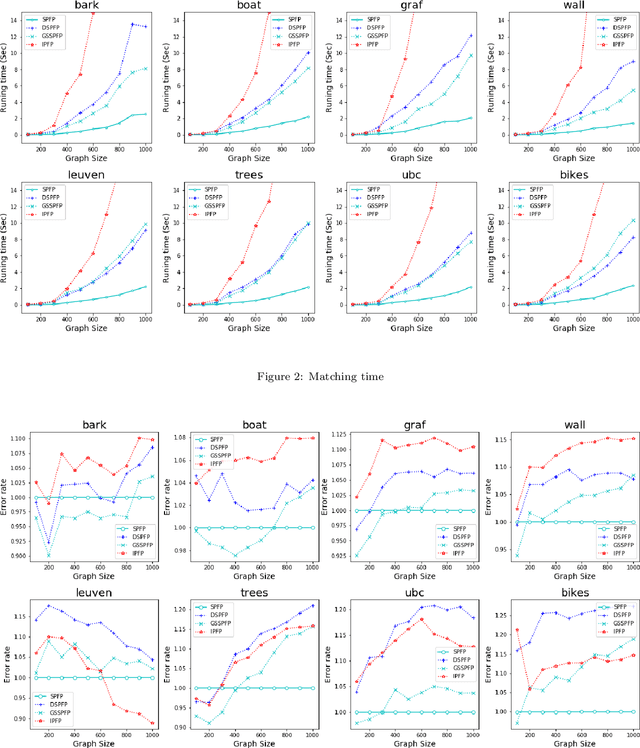

This paper studies a framework, projected fixed-point method, for graph matching. The framework contains a class of popular graph matching algorithms, including graduated assignment (GA), integer projected fixed-point method (IPFP) and doubly stochastic projected fixed-point method (DSPFP). We propose an adaptive strategy to tune the step size parameter in this framework. Such a strategy improves these algorithms in efficiency and accuracy. Further, it guarantees the convergence of the underlying algorithms. Some preliminary analysis based on distance geometry seems to support that the optimal step size parameter has a high probability of 1 when graphs are fully connected. Secondly, it is observed that a popular projection method, softassign, is sensitive to graphs' cardinality(size). We proposed a dynamical softassign algorithm that is robust to graphs' cardinality. Combining the adaptive step size and the dynamical softassign, we propose a novel graph matching algorithm: the adaptive projected fixed-point method with dynamical softassign. Various experiments demonstrate that the proposed algorithm is significantly faster than several other state-of-art algorithms with no loss of accuracy.
Modeling Randomly Walking Volatility with Chained Gamma Distributions
Jul 04, 2022
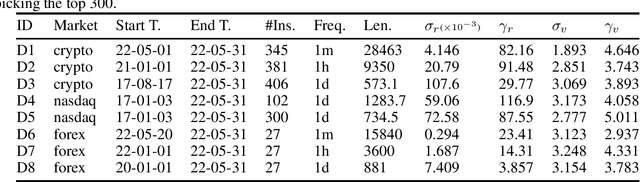
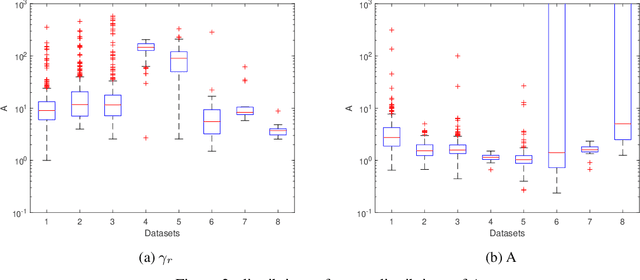
Volatility clustering is a common phenomenon in financial time series. Typically, linear models are used to describe the temporal autocorrelation of the (logarithmic) variance of returns. Considering the difficulty in estimation of this model, we construct a Dynamic Bayesian Network, which utilizes the conjugate prior relation of normal-gamma and gamma-gamma, so that at each node, its posterior form locally remains unchanged. This makes it possible to quickly find approximate solutions using variational methods. Furthermore, we ensure that the volatility expressed by the model is an independent incremental process after inserting dummy gamma nodes between adjacent time steps. We have found that, this model has two advantages: 1) It can be proved that it can express heavier tails than Gaussians, i.e., have positive excess kurtosis, compared to popular linear models. 2) If the variational inference(VI) is used for state estimation, it runs much faster than Monte Carlo(MC) methods, since the calculation of the posterior uses only basic arithmetic operations. And, its convergence process is deterministic. We tested the model, named Gam-Chain, using recent Crypto, Nasdaq, and Forex records of varying resolutions. The results show that: 1) In the same case of using MC, this model can achieve comparable state estimation results with the regular lognormal chain. 2) In the case of only using VI, this model can obtain accuracy that are slightly worse than MC, but still acceptable in practice; 3) Only using VI, the running time of Gam-Chain, under the most conservative settings, can be reduced to below 20% of that based on the lognormal chain via MC.
Sub-GMN: The Subgraph Matching Network Model
Apr 30, 2021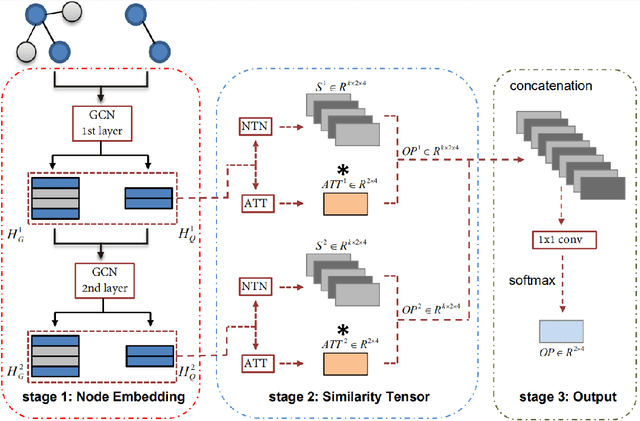


As one of the most fundamental tasks in graph theory, subgraph matching is a crucial task in many fields, ranging from information retrieval, computer vision, biology, chemistry and natural language processing. Yet subgraph matching problem remains to be an NP-complete problem. This study proposes an end-to-end learning-based approximate method for subgraph matching task, called subgraph matching network (Sub-GMN). The proposed Sub-GMN firstly uses graph representation learning to map nodes to node-level embedding. It then combines metric learning and attention mechanisms to model the relationship between matched nodes in the data graph and query graph. To test the performance of the proposed method, we applied our method on two databases. We used two existing methods, GNN and FGNN as baseline for comparison. Our experiment shows that, on dataset 1, on average the accuracy of Sub-GMN are 12.21\% and 3.2\% higher than that of GNN and FGNN respectively. On average running time Sub-GMN runs 20-40 times faster than FGNN. In addition, the average F1-score of Sub-GMN on all experiments with dataset 2 reached 0.95, which demonstrates that Sub-GMN outputs more correct node-to-node matches. Comparing with the previous GNNs-based methods for subgraph matching task, our proposed Sub-GMN allows varying query and data graphes in the test/application stage, while most previous GNNs-based methods can only find a matched subgraph in the data graph during the test/application for the same query graph used in the training stage. Another advantage of our proposed Sub-GMN is that it can output a list of node-to-node matches, while most existing end-to-end GNNs based methods cannot provide the matched node pairs.
Fabricated Pictures Detection with Graph Matching
Jan 16, 2020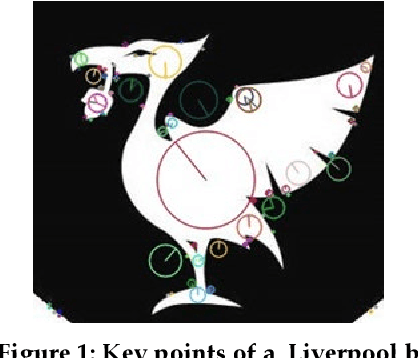
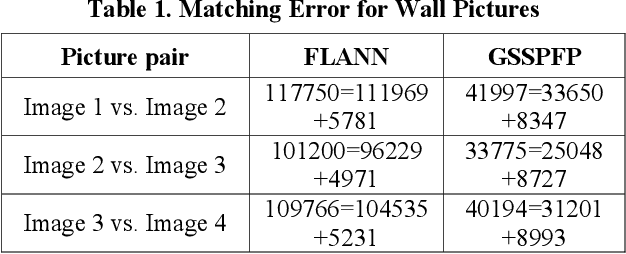

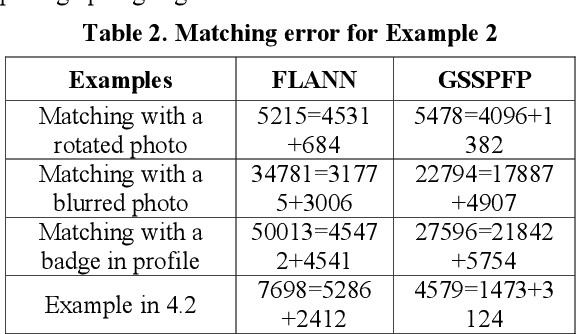
Fabricating experimental pictures in research work is a serious academic misconduct, which should better be detected in the reviewing process. However, due to large number of submissions, the detection whether a picture is fabricated or reused is laborious for reviewers, and sometimes is indistinct with human eyes. A tool for detecting similarity between images may help to alleviate this problem. Some methods based on local feature points matching work for most of the time, while these methods may result in mess of matchings due to ignorance of global relationship between features. We present a framework to detect similar, or perhaps fabricated, pictures with the graph matching techniques. A new iterative method is proposed, and experiments show that such a graph matching technique is better than the methods based only on local features for some cases.