 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGGBond: Growing Graph-Based AI-Agent Society for Socially-Aware Recommender Simulation
May 27, 2025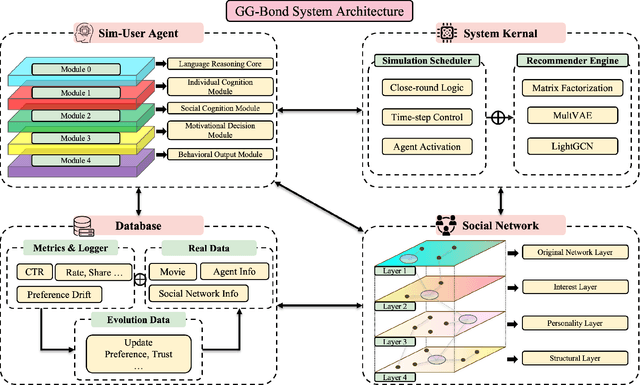
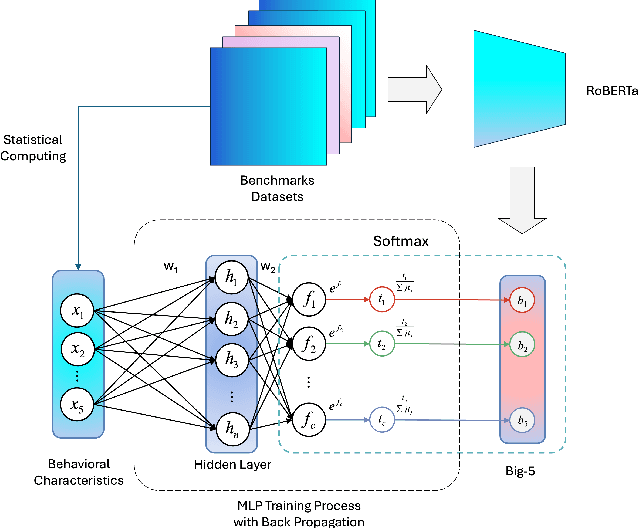
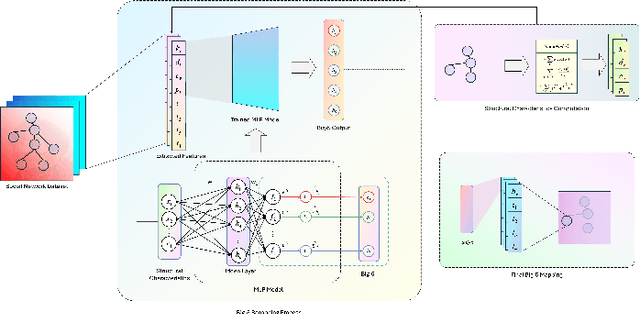
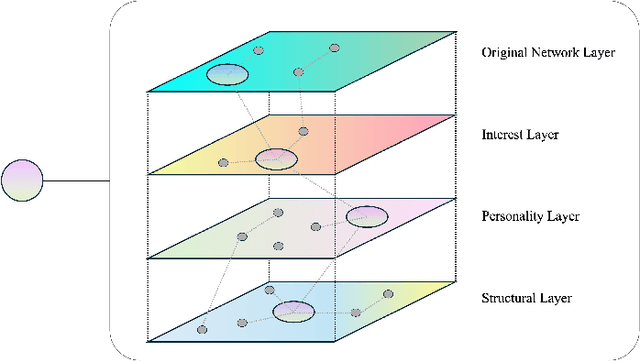
Current personalized recommender systems predominantly rely on static offline data for algorithm design and evaluation, significantly limiting their ability to capture long-term user preference evolution and social influence dynamics in real-world scenarios. To address this fundamental challenge, we propose a high-fidelity social simulation platform integrating human-like cognitive agents and dynamic social interactions to realistically simulate user behavior evolution under recommendation interventions. Specifically, the system comprises a population of Sim-User Agents, each equipped with a five-layer cognitive architecture that encapsulates key psychological mechanisms, including episodic memory, affective state transitions, adaptive preference learning, and dynamic trust-risk assessments. In particular, we innovatively introduce the Intimacy--Curiosity--Reciprocity--Risk (ICR2) motivational engine grounded in psychological and sociological theories, enabling more realistic user decision-making processes. Furthermore, we construct a multilayer heterogeneous social graph (GGBond Graph) supporting dynamic relational evolution, effectively modeling users' evolving social ties and trust dynamics based on interest similarity, personality alignment, and structural homophily. During system operation, agents autonomously respond to recommendations generated by typical recommender algorithms (e.g., Matrix Factorization, MultVAE, LightGCN), deciding whether to consume, rate, and share content while dynamically updating their internal states and social connections, thereby forming a stable, multi-round feedback loop. This innovative design transcends the limitations of traditional static datasets, providing a controlled, observable environment for evaluating long-term recommender effects.
Can bidirectional encoder become the ultimate winner for downstream applications of foundation models?
Nov 27, 2024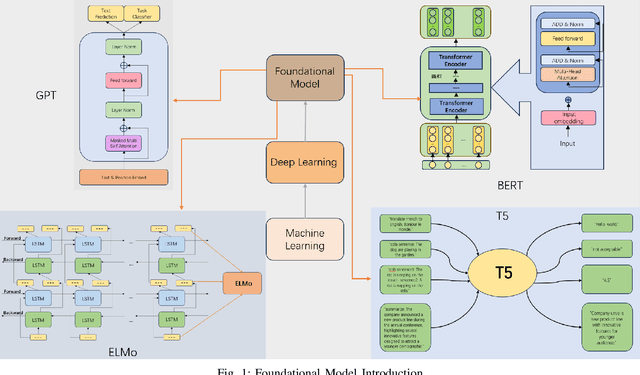
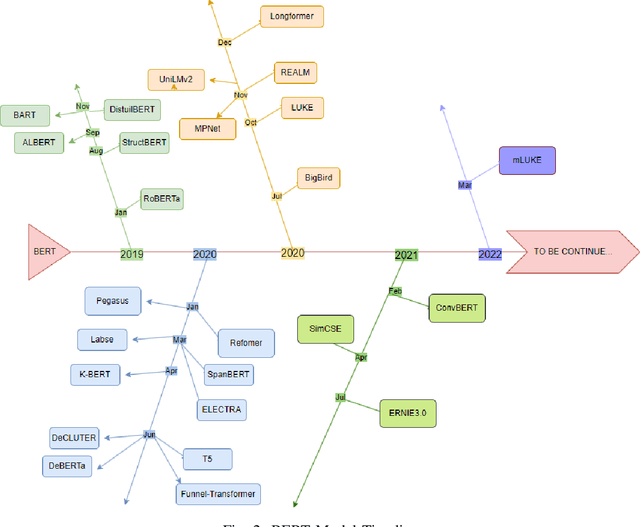

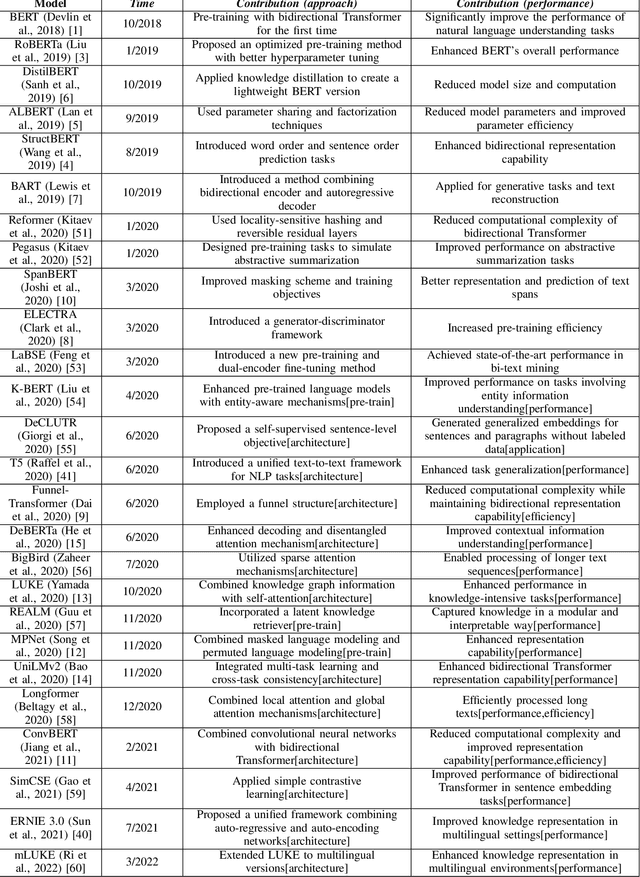
Over the past few decades, Artificial Intelligence(AI) has progressed from the initial machine learning stage to the deep learning stage, and now to the stage of foundational models. Foundational models have the characteristics of pre-training, transfer learning, and self-supervised learning, and pre-trained models can be fine-tuned and applied to various downstream tasks. Under the framework of foundational models, models such as Bidirectional Encoder Representations from Transformers(BERT) and Generative Pre-trained Transformer(GPT) have greatly advanced the development of natural language processing(NLP), especially the emergence of many models based on BERT. BERT broke through the limitation of only using one-way methods for language modeling in pre-training by using a masked language model. It can capture bidirectional context information to predict the masked words in the sequence, this can improve the feature extraction ability of the model. This makes the model very useful for downstream tasks, especially for specialized applications. The model using the bidirectional encoder can better understand the domain knowledge and be better applied to these downstream tasks. So we hope to help understand how this technology has evolved and improved model performance in various natural language processing tasks under the background of foundational models and reveal its importance in capturing context information and improving the model's performance on downstream tasks. This article analyzes one-way and bidirectional models based on GPT and BERT and compares their differences based on the purpose of the model. It also briefly analyzes BERT and the improvements of some models based on BERT. The model's performance on the Stanford Question Answering Dataset(SQuAD) and General Language Understanding Evaluation(GLUE) was compared.
Stochastic diagonal estimation with adaptive parameter selection
Oct 15, 2024



In this paper, we investigate diagonal estimation for large or implicit matrices, aiming to develop a novel and efficient stochastic algorithm that incorporates adaptive parameter selection. We explore the influence of different eigenvalue distributions on diagonal estimation and analyze the necessity of introducing the projection method and adaptive parameter optimization into the stochastic diagonal estimator. Based on this analysis, we derive a lower bound on the number of random query vectors needed to satisfy a given probabilistic error bound, which forms the foundation of our adaptive stochastic diagonal estimation algorithm. Finally, numerical experiments demonstrate the effectiveness of the proposed estimator for various matrix types, showcasing its efficiency and stability compared to other existing stochastic diagonal estimation methods.
Movie Recommendation with Poster Attention via Multi-modal Transformer Feature Fusion
Jul 12, 2024



Pre-trained models learn general representations from large datsets which can be fine-turned for specific tasks to significantly reduce training time. Pre-trained models like generative pretrained transformers (GPT), bidirectional encoder representations from transformers (BERT), vision transfomers (ViT) have become a cornerstone of current research in machine learning. This study proposes a multi-modal movie recommendation system by extract features of the well designed posters for each movie and the narrative text description of the movie. This system uses the BERT model to extract the information of text modality, the ViT model applied to extract the information of poster/image modality, and the Transformer architecture for feature fusion of all modalities to predict users' preference. The integration of pre-trained foundational models with some smaller data sets in downstream applications capture multi-modal content features in a more comprehensive manner, thereby providing more accurate recommendations. The efficiency of the proof-of-concept model is verified by the standard benchmark problem the MovieLens 100K and 1M datasets. The prediction accuracy of user ratings is enhanced in comparison to the baseline algorithm, thereby demonstrating the potential of this cross-modal algorithm to be applied for movie or video recommendation.
EchoMamba4Rec: Harmonizing Bidirectional State Space Models with Spectral Filtering for Advanced Sequential Recommendation
Jun 04, 2024Sequential recommendation aims to estimate dynamic user preferences and sequential dependencies among historical user behaviors. Attention-based models have proven effective for sequential recommendation, but they suffer from inference inefficiency due to the quadratic computational complexity of attention mechanisms, particularly for long-range behavior sequences. Inspired by the recent success of state space models (SSMs) in control theory, which provide a robust framework for modeling and controlling dynamic systems, we present EchoMamba4Rec. Control theory emphasizes the use of SSMs for managing long-range dependencies and maintaining inferential efficiency through structured state matrices. EchoMamba4Rec leverages these control relationships in sequential recommendation and integrates bi-directional processing with frequency-domain filtering to capture complex patterns and dependencies in user interaction data more effectively. Our model benefits from the ability of state space models (SSMs) to learn and perform parallel computations, significantly enhancing computational efficiency and scalability. It features a bi-directional Mamba module that incorporates both forward and reverse Mamba components, leveraging information from both past and future interactions. Additionally, a filter layer operates in the frequency domain using learnable Fast Fourier Transform (FFT) and learnable filters, followed by an inverse FFT to refine item embeddings and reduce noise. We also integrate Gate Linear Units (GLU) to dynamically control information flow, enhancing the model's expressiveness and training stability. Experimental results demonstrate that EchoMamba significantly outperforms existing models, providing more accurate and personalized recommendations.
From attention to profit: quantitative trading strategy based on transformer
Mar 30, 2024In traditional quantitative trading practice, navigating the complicated and dynamic financial market presents a persistent challenge. Former machine learning approaches have struggled to fully capture various market variables, often ignore long-term information and fail to catch up with essential signals that may lead the profit. This paper introduces an enhanced transformer architecture and designs a novel factor based on the model. By transfer learning from sentiment analysis, the proposed model not only exploits its original inherent advantages in capturing long-range dependencies and modelling complex data relationships but is also able to solve tasks with numerical inputs and accurately forecast future returns over a period. This work collects more than 5,000,000 rolling data of 4,601 stocks in the Chinese capital market from 2010 to 2019. The results of this study demonstrated the model's superior performance in predicting stock trends compared with other 100 factor-based quantitative strategies with lower turnover rates and a more robust half-life period. Notably, the model's innovative use transformer to establish factors, in conjunction with market sentiment information, has been shown to enhance the accuracy of trading signals significantly, thereby offering promising implications for the future of quantitative trading strategies.
Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review
Oct 27, 2023



This paper delves into the pivotal role of prompt engineering in unleashing the capabilities of Large Language Models (LLMs). Prompt engineering is the process of structuring input text for LLMs and is a technique integral to optimizing the efficacy of LLMs. This survey elucidates foundational principles of prompt engineering, such as role-prompting, one-shot, and few-shot prompting, as well as more advanced methodologies such as the chain-of-thought and tree-of-thoughts prompting. The paper sheds light on how external assistance in the form of plugins can assist in this task, and reduce machine hallucination by retrieving external knowledge. We subsequently delineate prospective directions in prompt engineering research, emphasizing the need for a deeper understanding of structures and the role of agents in Artificial Intelligence-Generated Content (AIGC) tools. We discuss how to assess the efficacy of prompt methods from different perspectives and using different methods. Finally, we gather information about the application of prompt engineering in such fields as education and programming, showing its transformative potential. This comprehensive survey aims to serve as a friendly guide for anyone venturing through the big world of LLMs and prompt engineering.
Learning with linear mixed model for group recommendation systems
Dec 17, 2022


Accurate prediction of users' responses to items is one of the main aims of many computational advising applications. Examples include recommending movies, news articles, songs, jobs, clothes, books and so forth. Accurate prediction of inactive users' responses still remains a challenging problem for many applications. In this paper, we explore the linear mixed model in recommendation system. The recommendation process is naturally modelled as the mixed process between objective effects (fixed effects) and subjective effects (random effects). The latent association between the subjective effects and the users' responses can be mined through the restricted maximum likelihood method. It turns out the linear mixed models can collaborate items' attributes and users' characteristics naturally and effectively. While this model cannot produce the most precisely individual level personalized recommendation, it is relative fast and accurate for group (users)/class (items) recommendation. Numerical examples on GroupLens benchmark problems are presented to show the effectiveness of this method.
* 5 pages, 9 figures, published
Dynamical softassign and adaptive parameter tuning for graph matching
Aug 17, 2022

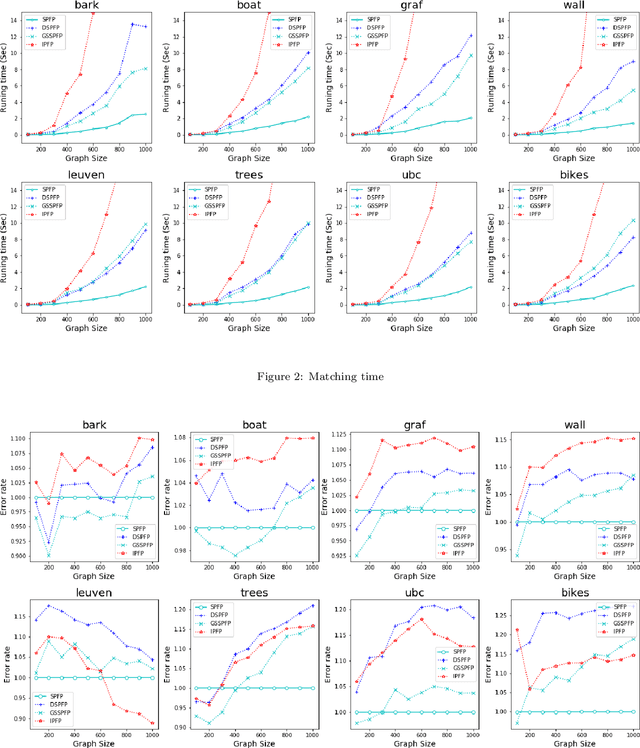

This paper studies a framework, projected fixed-point method, for graph matching. The framework contains a class of popular graph matching algorithms, including graduated assignment (GA), integer projected fixed-point method (IPFP) and doubly stochastic projected fixed-point method (DSPFP). We propose an adaptive strategy to tune the step size parameter in this framework. Such a strategy improves these algorithms in efficiency and accuracy. Further, it guarantees the convergence of the underlying algorithms. Some preliminary analysis based on distance geometry seems to support that the optimal step size parameter has a high probability of 1 when graphs are fully connected. Secondly, it is observed that a popular projection method, softassign, is sensitive to graphs' cardinality(size). We proposed a dynamical softassign algorithm that is robust to graphs' cardinality. Combining the adaptive step size and the dynamical softassign, we propose a novel graph matching algorithm: the adaptive projected fixed-point method with dynamical softassign. Various experiments demonstrate that the proposed algorithm is significantly faster than several other state-of-art algorithms with no loss of accuracy.
Fabricated Pictures Detection with Graph Matching
Jan 16, 2020
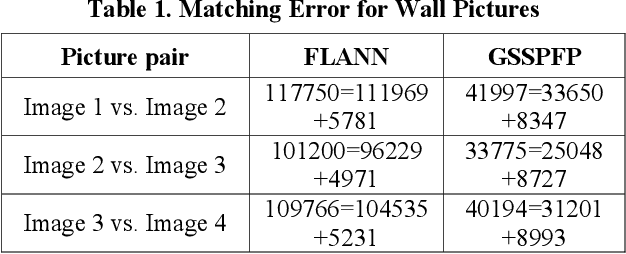

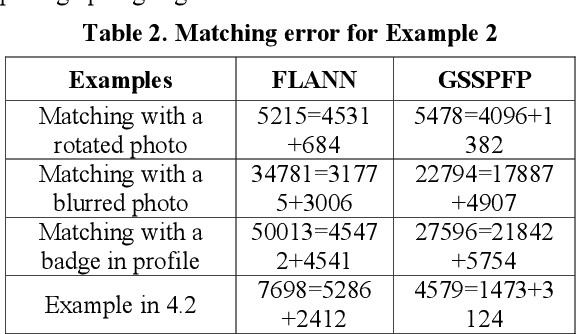
Fabricating experimental pictures in research work is a serious academic misconduct, which should better be detected in the reviewing process. However, due to large number of submissions, the detection whether a picture is fabricated or reused is laborious for reviewers, and sometimes is indistinct with human eyes. A tool for detecting similarity between images may help to alleviate this problem. Some methods based on local feature points matching work for most of the time, while these methods may result in mess of matchings due to ignorance of global relationship between features. We present a framework to detect similar, or perhaps fabricated, pictures with the graph matching techniques. A new iterative method is proposed, and experiments show that such a graph matching technique is better than the methods based only on local features for some cases.