 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Decision Agent: Learning Generalist Policies from Natural Language Supervision
Apr 22, 2025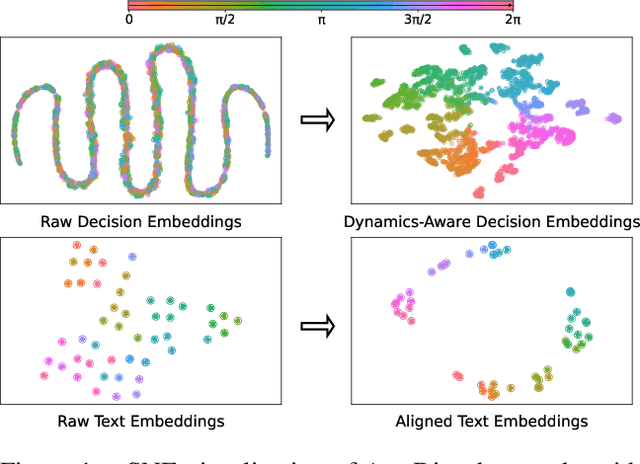

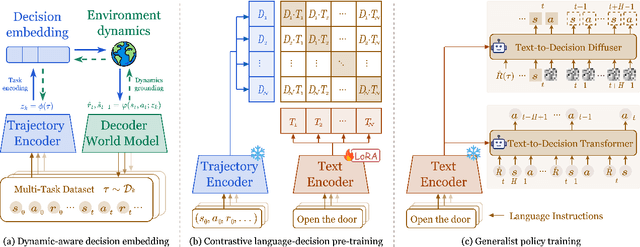
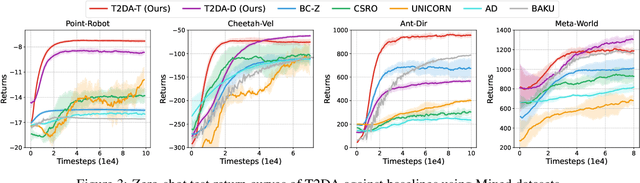
RL systems usually tackle generalization by inferring task beliefs from high-quality samples or warmup explorations. The restricted form limits their generality and usability since these supervision signals are expensive and even infeasible to acquire in advance for unseen tasks. Learning directly from the raw text about decision tasks is a promising alternative to leverage a much broader source of supervision. In the paper, we propose Text-to-Decision Agent (T2DA), a simple and scalable framework that supervises generalist policy learning with natural language. We first introduce a generalized world model to encode multi-task decision data into a dynamics-aware embedding space. Then, inspired by CLIP, we predict which textual description goes with which decision embedding, effectively bridging their semantic gap via contrastive language-decision pre-training and aligning the text embeddings to comprehend the environment dynamics. After training the text-conditioned generalist policy, the agent can directly realize zero-shot text-to-decision generation in response to language instructions. Comprehensive experiments on MuJoCo and Meta-World benchmarks show that T2DA facilitates high-capacity zero-shot generalization and outperforms various types of baselines.
VidTwin: Video VAE with Decoupled Structure and Dynamics
Dec 23, 2024Recent advancements in video autoencoders (Video AEs) have significantly improved the quality and efficiency of video generation. In this paper, we propose a novel and compact video autoencoder, VidTwin, that decouples video into two distinct latent spaces: Structure latent vectors, which capture overall content and global movement, and Dynamics latent vectors, which represent fine-grained details and rapid movements. Specifically, our approach leverages an Encoder-Decoder backbone, augmented with two submodules for extracting these latent spaces, respectively. The first submodule employs a Q-Former to extract low-frequency motion trends, followed by downsampling blocks to remove redundant content details. The second averages the latent vectors along the spatial dimension to capture rapid motion. Extensive experiments show that VidTwin achieves a high compression rate of 0.20% with high reconstruction quality (PSNR of 28.14 on the MCL-JCV dataset), and performs efficiently and effectively in downstream generative tasks. Moreover, our model demonstrates explainability and scalability, paving the way for future research in video latent representation and generation. Our code has been released at https://github.com/microsoft/VidTok/tree/main/vidtwin.
Can bidirectional encoder become the ultimate winner for downstream applications of foundation models?
Nov 27, 2024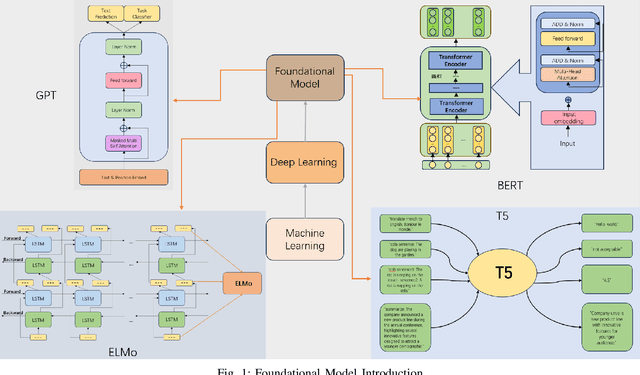
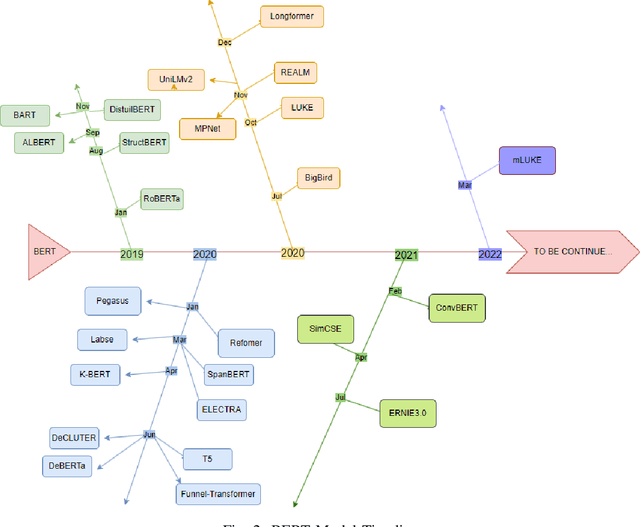

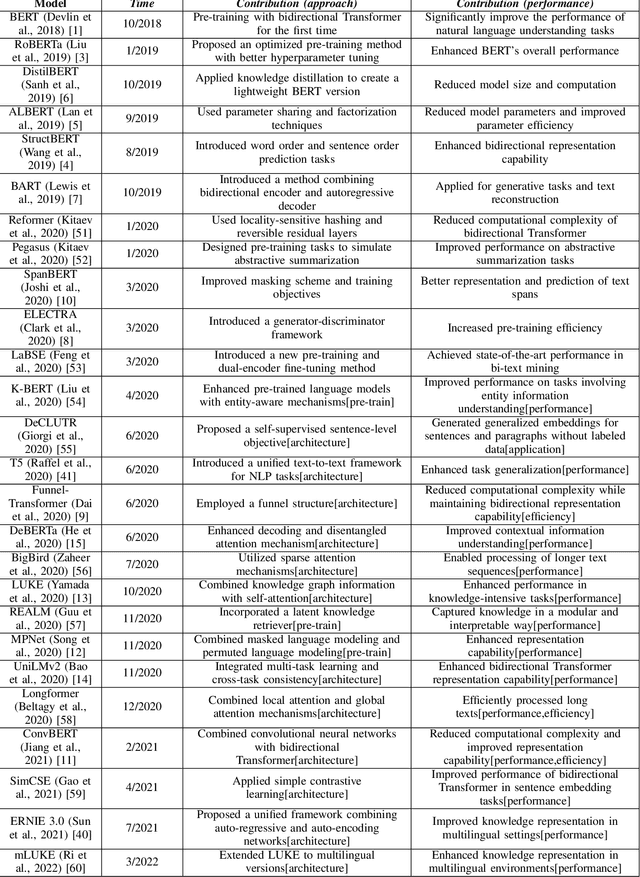
Over the past few decades, Artificial Intelligence(AI) has progressed from the initial machine learning stage to the deep learning stage, and now to the stage of foundational models. Foundational models have the characteristics of pre-training, transfer learning, and self-supervised learning, and pre-trained models can be fine-tuned and applied to various downstream tasks. Under the framework of foundational models, models such as Bidirectional Encoder Representations from Transformers(BERT) and Generative Pre-trained Transformer(GPT) have greatly advanced the development of natural language processing(NLP), especially the emergence of many models based on BERT. BERT broke through the limitation of only using one-way methods for language modeling in pre-training by using a masked language model. It can capture bidirectional context information to predict the masked words in the sequence, this can improve the feature extraction ability of the model. This makes the model very useful for downstream tasks, especially for specialized applications. The model using the bidirectional encoder can better understand the domain knowledge and be better applied to these downstream tasks. So we hope to help understand how this technology has evolved and improved model performance in various natural language processing tasks under the background of foundational models and reveal its importance in capturing context information and improving the model's performance on downstream tasks. This article analyzes one-way and bidirectional models based on GPT and BERT and compares their differences based on the purpose of the model. It also briefly analyzes BERT and the improvements of some models based on BERT. The model's performance on the Stanford Question Answering Dataset(SQuAD) and General Language Understanding Evaluation(GLUE) was compared.