 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan bidirectional encoder become the ultimate winner for downstream applications of foundation models?
Nov 27, 2024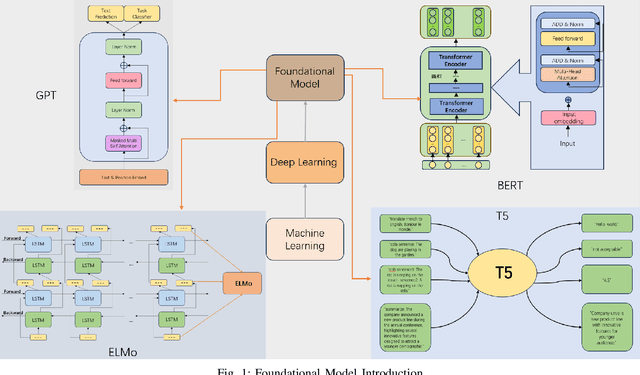
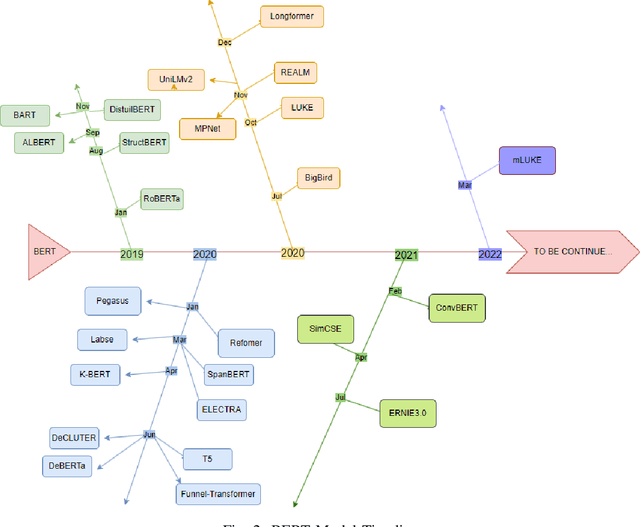

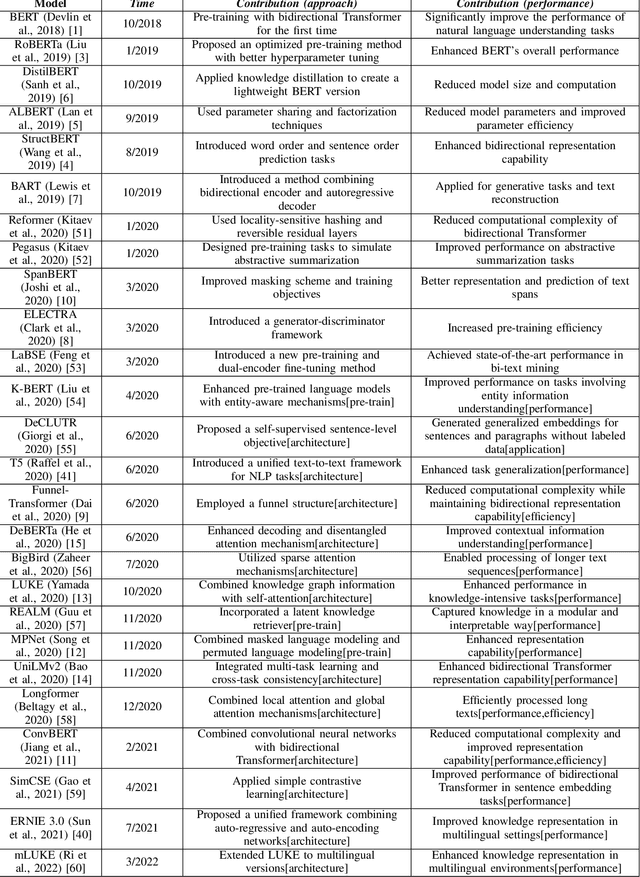
Over the past few decades, Artificial Intelligence(AI) has progressed from the initial machine learning stage to the deep learning stage, and now to the stage of foundational models. Foundational models have the characteristics of pre-training, transfer learning, and self-supervised learning, and pre-trained models can be fine-tuned and applied to various downstream tasks. Under the framework of foundational models, models such as Bidirectional Encoder Representations from Transformers(BERT) and Generative Pre-trained Transformer(GPT) have greatly advanced the development of natural language processing(NLP), especially the emergence of many models based on BERT. BERT broke through the limitation of only using one-way methods for language modeling in pre-training by using a masked language model. It can capture bidirectional context information to predict the masked words in the sequence, this can improve the feature extraction ability of the model. This makes the model very useful for downstream tasks, especially for specialized applications. The model using the bidirectional encoder can better understand the domain knowledge and be better applied to these downstream tasks. So we hope to help understand how this technology has evolved and improved model performance in various natural language processing tasks under the background of foundational models and reveal its importance in capturing context information and improving the model's performance on downstream tasks. This article analyzes one-way and bidirectional models based on GPT and BERT and compares their differences based on the purpose of the model. It also briefly analyzes BERT and the improvements of some models based on BERT. The model's performance on the Stanford Question Answering Dataset(SQuAD) and General Language Understanding Evaluation(GLUE) was compared.
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.
Video Shadow Detection via Spatio-Temporal Interpolation Consistency Training
Jun 17, 2022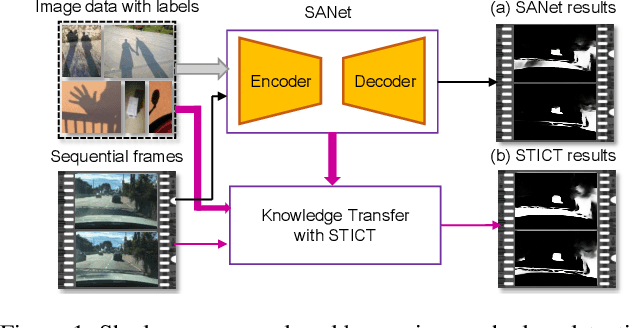

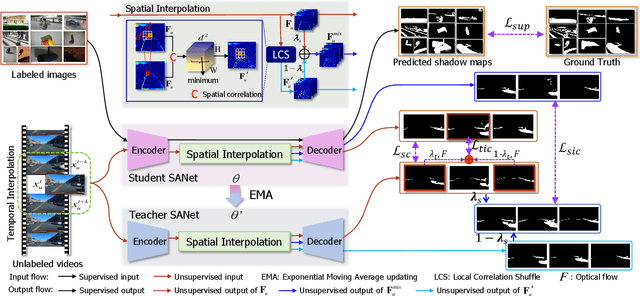
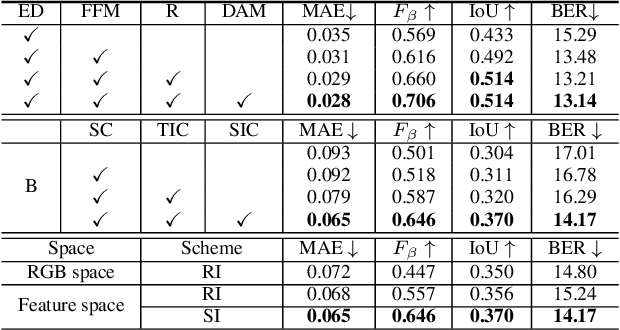
It is challenging to annotate large-scale datasets for supervised video shadow detection methods. Using a model trained on labeled images to the video frames directly may lead to high generalization error and temporal inconsistent results. In this paper, we address these challenges by proposing a Spatio-Temporal Interpolation Consistency Training (STICT) framework to rationally feed the unlabeled video frames together with the labeled images into an image shadow detection network training. Specifically, we propose the Spatial and Temporal ICT, in which we define two new interpolation schemes, \textit{i.e.}, the spatial interpolation and the temporal interpolation. We then derive the spatial and temporal interpolation consistency constraints accordingly for enhancing generalization in the pixel-wise classification task and for encouraging temporal consistent predictions, respectively. In addition, we design a Scale-Aware Network for multi-scale shadow knowledge learning in images, and propose a scale-consistency constraint to minimize the discrepancy among the predictions at different scales. Our proposed approach is extensively validated on the ViSha dataset and a self-annotated dataset. Experimental results show that, even without video labels, our approach is better than most state of the art supervised, semi-supervised or unsupervised image/video shadow detection methods and other methods in related tasks. Code and dataset are available at \url{https://github.com/yihong-97/STICT}.
RIDDLE: Lidar Data Compression with Range Image Deep Delta Encoding
Jun 02, 2022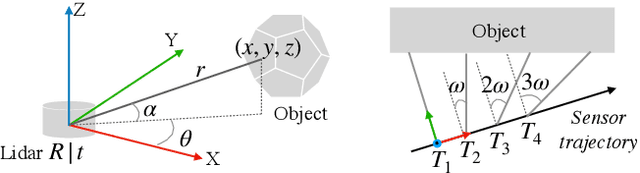
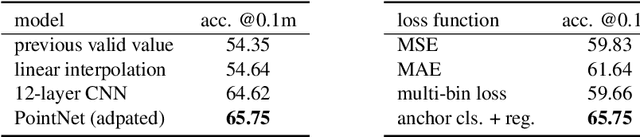

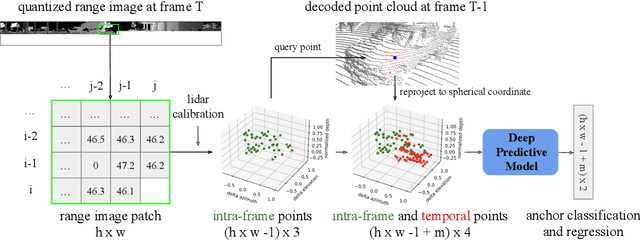
Lidars are depth measuring sensors widely used in autonomous driving and augmented reality. However, the large volume of data produced by lidars can lead to high costs in data storage and transmission. While lidar data can be represented as two interchangeable representations: 3D point clouds and range images, most previous work focus on compressing the generic 3D point clouds. In this work, we show that directly compressing the range images can leverage the lidar scanning pattern, compared to compressing the unprojected point clouds. We propose a novel data-driven range image compression algorithm, named RIDDLE (Range Image Deep DeLta Encoding). At its core is a deep model that predicts the next pixel value in a raster scanning order, based on contextual laser shots from both the current and past scans (represented as a 4D point cloud of spherical coordinates and time). The deltas between predictions and original values can then be compressed by entropy encoding. Evaluated on the Waymo Open Dataset and KITTI, our method demonstrates significant improvement in the compression rate (under the same distortion) compared to widely used point cloud and range image compression algorithms as well as recent deep methods.
SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud
Sep 22, 2018
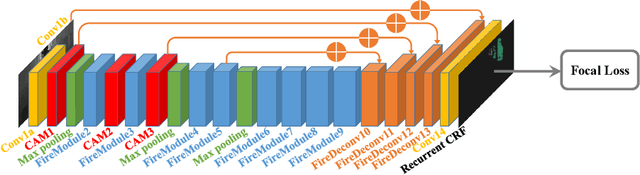
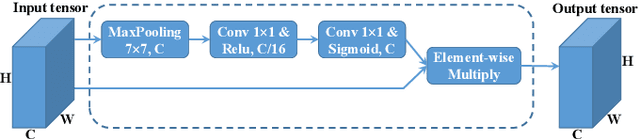
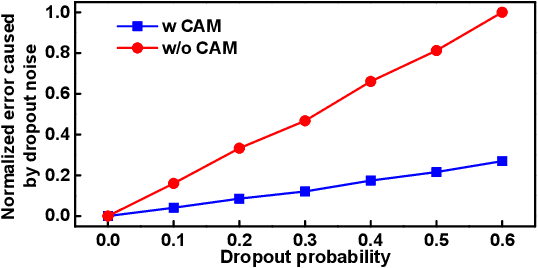
Earlier work demonstrates the promise of deep-learning-based approaches for point cloud segmentation; however, these approaches need to be improved to be practically useful. To this end, we introduce a new model SqueezeSegV2 that is more robust to dropout noise in LiDAR point clouds. With improved model structure, training loss, batch normalization and additional input channel, SqueezeSegV2 achieves significant accuracy improvement when trained on real data. Training models for point cloud segmentation requires large amounts of labeled point-cloud data, which is expensive to obtain. To sidestep the cost of collection and annotation, simulators such as GTA-V can be used to create unlimited amounts of labeled, synthetic data. However, due to domain shift, models trained on synthetic data often do not generalize well to the real world. We address this problem with a domain-adaptation training pipeline consisting of three major components: 1) learned intensity rendering, 2) geodesic correlation alignment, and 3) progressive domain calibration. When trained on real data, our new model exhibits segmentation accuracy improvements of 6.0-8.6% over the original SqueezeSeg. When training our new model on synthetic data using the proposed domain adaptation pipeline, we nearly double test accuracy on real-world data, from 29.0% to 57.4%. Our source code and synthetic dataset will be open-sourced.