 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Shadow Detection via Spatio-Temporal Interpolation Consistency Training
Paper and Code
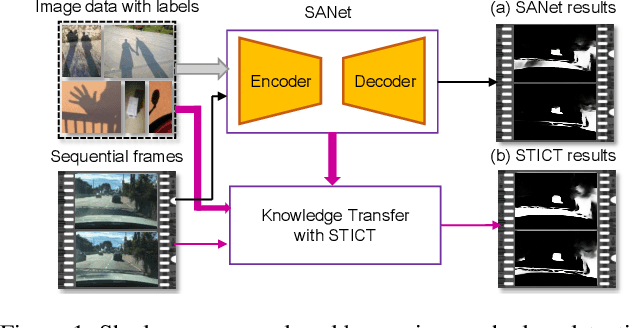

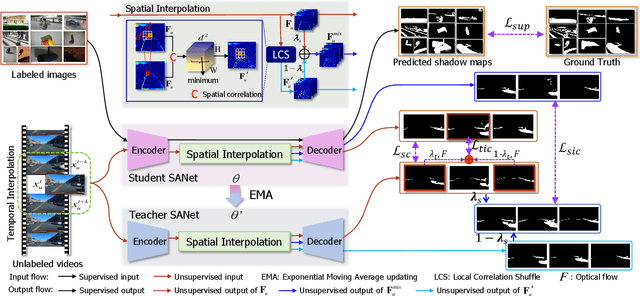
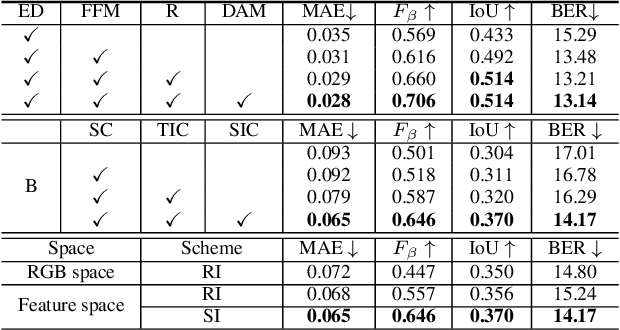
It is challenging to annotate large-scale datasets for supervised video shadow detection methods. Using a model trained on labeled images to the video frames directly may lead to high generalization error and temporal inconsistent results. In this paper, we address these challenges by proposing a Spatio-Temporal Interpolation Consistency Training (STICT) framework to rationally feed the unlabeled video frames together with the labeled images into an image shadow detection network training. Specifically, we propose the Spatial and Temporal ICT, in which we define two new interpolation schemes, \textit{i.e.}, the spatial interpolation and the temporal interpolation. We then derive the spatial and temporal interpolation consistency constraints accordingly for enhancing generalization in the pixel-wise classification task and for encouraging temporal consistent predictions, respectively. In addition, we design a Scale-Aware Network for multi-scale shadow knowledge learning in images, and propose a scale-consistency constraint to minimize the discrepancy among the predictions at different scales. Our proposed approach is extensively validated on the ViSha dataset and a self-annotated dataset. Experimental results show that, even without video labels, our approach is better than most state of the art supervised, semi-supervised or unsupervised image/video shadow detection methods and other methods in related tasks. Code and dataset are available at \url{https://github.com/yihong-97/STICT}.