 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAFMat: Hybrid Priors Guided Adaptive Fusion for Single-Image Human Material Estimation
Jun 15, 2026Physically based rendering (PBR) material estimation is a fundamental appearance decomposition task with broad applications in virtual content creation, relighting, and digital human rendering. However, estimating PBR materials from a single human image remains highly ill-posed, since illumination, geometry, and reflectance are heavily entangled in the observed appearance. To mitigate this ambiguity, we propose HAFMat, a hybrid-prior-guided framework for single-image human material estimation. Our method introduces guidance maps that encode complementary cues, including appearance, body geometry, structure, and prior material predictions from pre-trained models. A key observation is that these guidance cues are heterogeneous: some cues mainly provide texture-level constraints, while others convey higher-level semantic information. To exploit this property, we design a Multi-layer Adaptive Feature Fusion Mechanism, which adaptively fuses guidance features with decoder features at different stages. This design enables texture-dominant and semantic-dominant cues to guide material decoding at appropriate levels, leading to more accurate and physically plausible material estimation. Extensive experiments on both synthetic and real data demonstrate that our method achieves state-of-the-art performance in material estimation and downstream relighting.
StoryVideoQA: Scaling Deep Video Understanding with a Large-Scale, Multi-Genre and Auto-Generated Dataset
Jun 04, 2026Video question answering (VideoQA) aims to answer questions about given videos. While existing approaches excel on factoid VideoQA, they struggle with deep video understanding (DVU), which requires the comprehension of complex storylines. This challenge arises from the inherent long-range video content, multi-faceted question types, and instance-level story elements, all of which constrain the scale and diversity of manually constructed DVU datasets. These difficulties constrain the scale and diversity of manually-constructed DVU dataset. To address these, we previously introduced StoryMind to automatically construct DVU datasets with balanced fine-grained topics. Though it can generate high-quality question-answer pairs (QAs) for TV series, it suffers significant performance degradation when handling longer and more complex movies. In this paper, we further design StoryMindv2, an enhanced multi-agent collaboration framework to generate high-quality DVU datasets for both TV series and movies. By integrating a novel supervisor-guided generation mechanism and a refined multi-reviewer voting strategy, the framework is utilized to construct StoryVideoQA, the largest DVU dataset to date, featuring over 363K QAs on 393.2 hours diverse story videos including TV series (avg. 1,635 seconds) and movies (avg. 7,878 seconds). Comprehensive evaluations of 20 state-of-the-art VideoQA methods on this large-scale benchmark reveal that they cannot fully maintain long-range character associations or construct a coherent understanding of complex storylines. To bridge this gap, we propose PlotTree, a novel video understanding agent, re-organizing long-range video content into a hierarchical plot structure, enabling efficient storyline reasoning on StoryVideoQA. Project page: https://github.com/nercms-mmap/StoryVideoQA/
* Accepted by IJCV 2026
Mitigating Knowledge Discrepancies among Multiple Datasets for Task-agnostic Unified Face Alignment
Mar 28, 2025


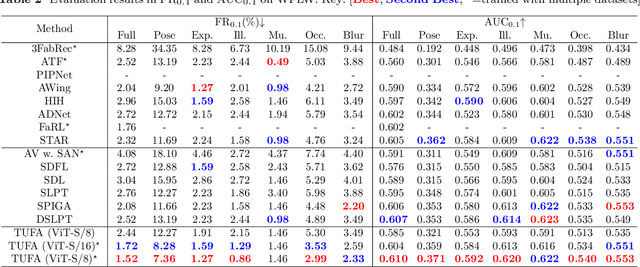
Despite the similar structures of human faces, existing face alignment methods cannot learn unified knowledge from multiple datasets with different landmark annotations. The limited training samples in a single dataset commonly result in fragile robustness in this field. To mitigate knowledge discrepancies among different datasets and train a task-agnostic unified face alignment (TUFA) framework, this paper presents a strategy to unify knowledge from multiple datasets. Specifically, we calculate a mean face shape for each dataset. To explicitly align these mean shapes on an interpretable plane based on their semantics, each shape is then incorporated with a group of semantic alignment embeddings. The 2D coordinates of these aligned shapes can be viewed as the anchors of the plane. By encoding them into structure prompts and further regressing the corresponding facial landmarks using image features, a mapping from the plane to the target faces is finally established, which unifies the learning target of different datasets. Consequently, multiple datasets can be utilized to boost the generalization ability of the model. The successful mitigation of discrepancies also enhances the efficiency of knowledge transferring to a novel dataset, significantly boosts the performance of few-shot face alignment. Additionally, the interpretable plane endows TUFA with a task-agnostic characteristic, enabling it to locate landmarks unseen during training in a zero-shot manner. Extensive experiments are carried on seven benchmarks and the results demonstrate an impressive improvement in face alignment brought by knowledge discrepancies mitigation.
FriendsQA: A New Large-Scale Deep Video Understanding Dataset with Fine-grained Topic Categorization for Story Videos
Dec 22, 2024Video question answering (VideoQA) aims to answer natural language questions according to the given videos. Although existing models perform well in the factoid VideoQA task, they still face challenges in deep video understanding (DVU) task, which focuses on story videos. Compared to factoid videos, the most significant feature of story videos is storylines, which are composed of complex interactions and long-range evolvement of core story topics including characters, actions and locations. Understanding these topics requires models to possess DVU capability. However, existing DVU datasets rarely organize questions according to these story topics, making them difficult to comprehensively assess VideoQA models' DVU capability of complex storylines. Additionally, the question quantity and video length of these dataset are limited by high labor costs of handcrafted dataset building method. In this paper, we devise a large language model based multi-agent collaboration framework, StoryMind, to automatically generate a new large-scale DVU dataset. The dataset, FriendsQA, derived from the renowned sitcom Friends with an average episode length of 1,358 seconds, contains 44.6K questions evenly distributed across 14 fine-grained topics. Finally, We conduct comprehensive experiments on 10 state-of-the-art VideoQA models using the FriendsQA dataset.
GGS: Generalizable Gaussian Splatting for Lane Switching in Autonomous Driving
Sep 04, 2024
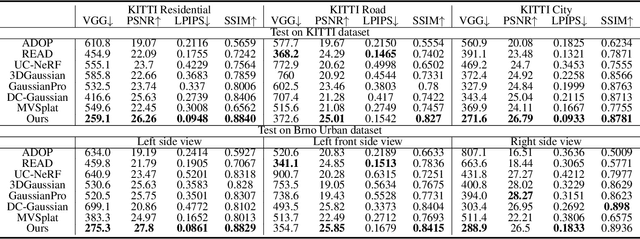
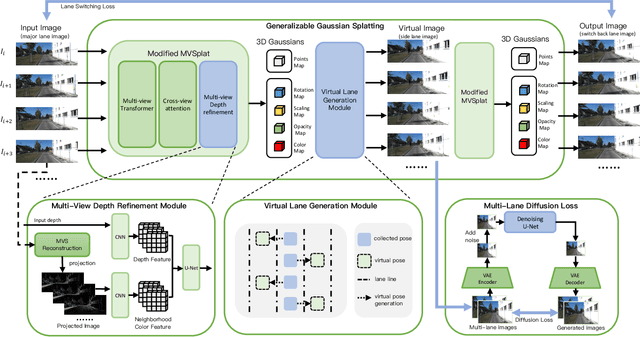

We propose GGS, a Generalizable Gaussian Splatting method for Autonomous Driving which can achieve realistic rendering under large viewpoint changes. Previous generalizable 3D gaussian splatting methods are limited to rendering novel views that are very close to the original pair of images, which cannot handle large differences in viewpoint. Especially in autonomous driving scenarios, images are typically collected from a single lane. The limited training perspective makes rendering images of a different lane very challenging. To further improve the rendering capability of GGS under large viewpoint changes, we introduces a novel virtual lane generation module into GSS method to enables high-quality lane switching even without a multi-lane dataset. Besides, we design a diffusion loss to supervise the generation of virtual lane image to further address the problem of lack of data in the virtual lanes. Finally, we also propose a depth refinement module to optimize depth estimation in the GSS model. Extensive validation of our method, compared to existing approaches, demonstrates state-of-the-art performance.
DLCA-Recon: Dynamic Loose Clothing Avatar Reconstruction from Monocular Videos
Dec 20, 2023



Reconstructing a dynamic human with loose clothing is an important but difficult task. To address this challenge, we propose a method named DLCA-Recon to create human avatars from monocular videos. The distance from loose clothing to the underlying body rapidly changes in every frame when the human freely moves and acts. Previous methods lack effective geometric initialization and constraints for guiding the optimization of deformation to explain this dramatic change, resulting in the discontinuous and incomplete reconstruction surface. To model the deformation more accurately, we propose to initialize an estimated 3D clothed human in the canonical space, as it is easier for deformation fields to learn from the clothed human than from SMPL. With both representations of explicit mesh and implicit SDF, we utilize the physical connection information between consecutive frames and propose a dynamic deformation field (DDF) to optimize deformation fields. DDF accounts for contributive forces on loose clothing to enhance the interpretability of deformations and effectively capture the free movement of loose clothing. Moreover, we propagate SMPL skinning weights to each individual and refine pose and skinning weights during the optimization to improve skinning transformation. Based on more reasonable initialization and DDF, we can simulate real-world physics more accurately. Extensive experiments on public and our own datasets validate that our method can produce superior results for humans with loose clothing compared to the SOTA methods.
Towards High-Quality Specular Highlight Removal by Leveraging Large-Scale Synthetic Data
Sep 12, 2023
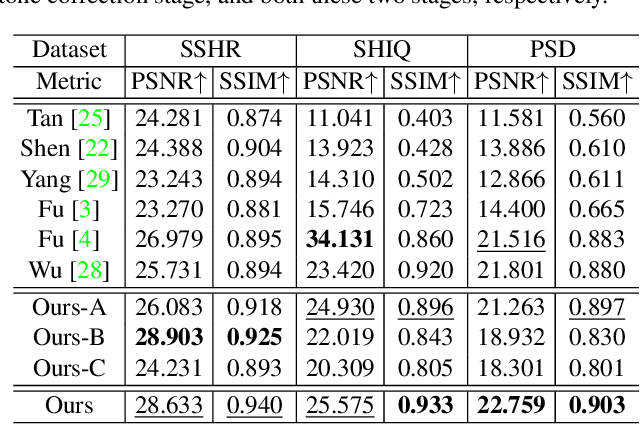
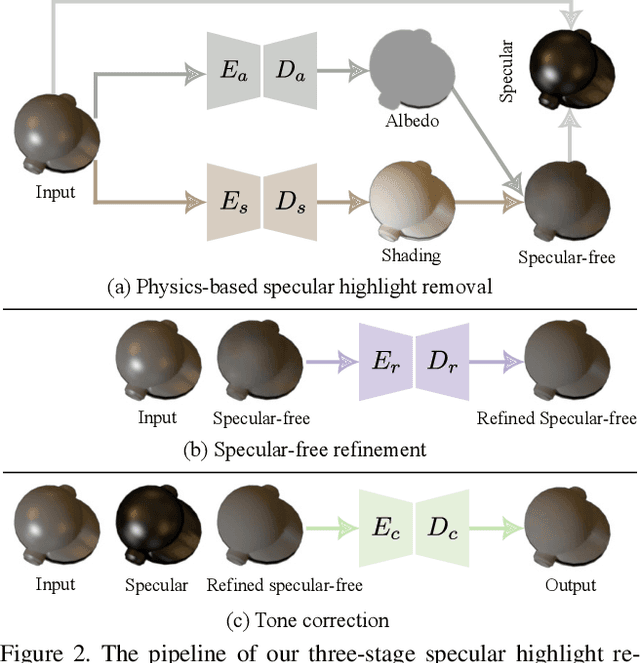

This paper aims to remove specular highlights from a single object-level image. Although previous methods have made some progresses, their performance remains somewhat limited, particularly for real images with complex specular highlights. To this end, we propose a three-stage network to address them. Specifically, given an input image, we first decompose it into the albedo, shading, and specular residue components to estimate a coarse specular-free image. Then, we further refine the coarse result to alleviate its visual artifacts such as color distortion. Finally, we adjust the tone of the refined result to match that of the input as closely as possible. In addition, to facilitate network training and quantitative evaluation, we present a large-scale synthetic dataset of object-level images, covering diverse objects and illumination conditions. Extensive experiments illustrate that our network is able to generalize well to unseen real object-level images, and even produce good results for scene-level images with multiple background objects and complex lighting.
NeTO:Neural Reconstruction of Transparent Objects with Self-Occlusion Aware Refraction-Tracing
Mar 20, 2023
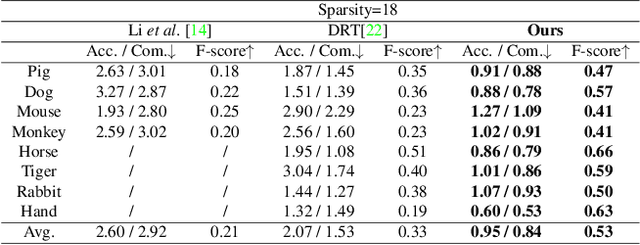
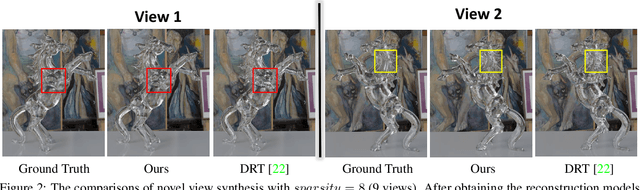
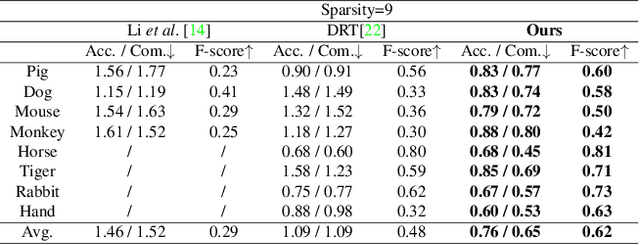
We present a novel method, called NeTO, for capturing 3D geometry of solid transparent objects from 2D images via volume rendering. Reconstructing transparent objects is a very challenging task, which is ill-suited for general-purpose reconstruction techniques due to the specular light transport phenomena. Although existing refraction-tracing based methods, designed specially for this task, achieve impressive results, they still suffer from unstable optimization and loss of fine details, since the explicit surface representation they adopted is difficult to be optimized, and the self-occlusion problem is ignored for refraction-tracing. In this paper, we propose to leverage implicit Signed Distance Function (SDF) as surface representation, and optimize the SDF field via volume rendering with a self-occlusion aware refractive ray tracing. The implicit representation enables our method to be capable of reconstructing high-quality reconstruction even with a limited set of images, and the self-occlusion aware strategy makes it possible for our method to accurately reconstruct the self-occluded regions. Experiments show that our method achieves faithful reconstruction results and outperforms prior works by a large margin. Visit our project page at \url{https://www.xxlong.site/NeTO/}
NeuralRoom: Geometry-Constrained Neural Implicit Surfaces for Indoor Scene Reconstruction
Oct 13, 2022


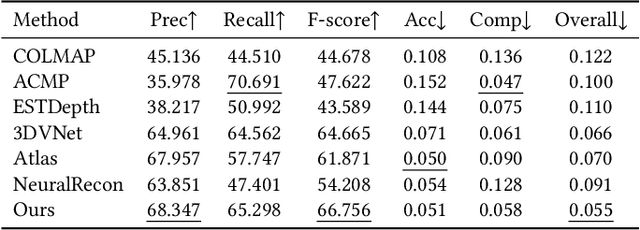
We present a novel neural surface reconstruction method called NeuralRoom for reconstructing room-sized indoor scenes directly from a set of 2D images. Recently, implicit neural representations have become a promising way to reconstruct surfaces from multiview images due to their high-quality results and simplicity. However, implicit neural representations usually cannot reconstruct indoor scenes well because they suffer severe shape-radiance ambiguity. We assume that the indoor scene consists of texture-rich and flat texture-less regions. In texture-rich regions, the multiview stereo can obtain accurate results. In the flat area, normal estimation networks usually obtain a good normal estimation. Based on the above observations, we reduce the possible spatial variation range of implicit neural surfaces by reliable geometric priors to alleviate shape-radiance ambiguity. Specifically, we use multiview stereo results to limit the NeuralRoom optimization space and then use reliable geometric priors to guide NeuralRoom training. Then the NeuralRoom would produce a neural scene representation that can render an image consistent with the input training images. In addition, we propose a smoothing method called perturbation-residual restrictions to improve the accuracy and completeness of the flat region, which assumes that the sampling points in a local surface should have the same normal and similar distance to the observation center. Experiments on the ScanNet dataset show that our method can reconstruct the texture-less area of indoor scenes while maintaining the accuracy of detail. We also apply NeuralRoom to more advanced multiview reconstruction algorithms and significantly improve their reconstruction quality.
Video Shadow Detection via Spatio-Temporal Interpolation Consistency Training
Jun 17, 2022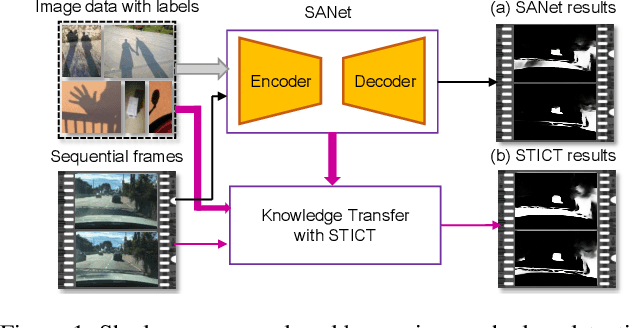

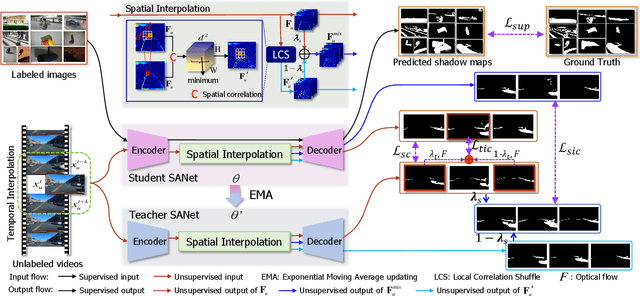
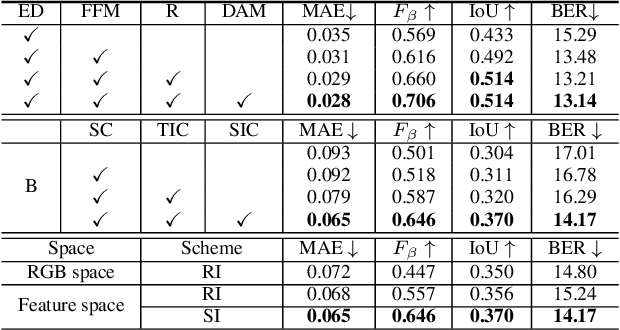
It is challenging to annotate large-scale datasets for supervised video shadow detection methods. Using a model trained on labeled images to the video frames directly may lead to high generalization error and temporal inconsistent results. In this paper, we address these challenges by proposing a Spatio-Temporal Interpolation Consistency Training (STICT) framework to rationally feed the unlabeled video frames together with the labeled images into an image shadow detection network training. Specifically, we propose the Spatial and Temporal ICT, in which we define two new interpolation schemes, \textit{i.e.}, the spatial interpolation and the temporal interpolation. We then derive the spatial and temporal interpolation consistency constraints accordingly for enhancing generalization in the pixel-wise classification task and for encouraging temporal consistent predictions, respectively. In addition, we design a Scale-Aware Network for multi-scale shadow knowledge learning in images, and propose a scale-consistency constraint to minimize the discrepancy among the predictions at different scales. Our proposed approach is extensively validated on the ViSha dataset and a self-annotated dataset. Experimental results show that, even without video labels, our approach is better than most state of the art supervised, semi-supervised or unsupervised image/video shadow detection methods and other methods in related tasks. Code and dataset are available at \url{https://github.com/yihong-97/STICT}.