 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving with DINO: Vision Foundation Features as a Unified Bridge for Sim-to-Real Generation in Autonomous Driving
Feb 09, 2026Driven by the emergence of Controllable Video Diffusion, existing Sim2Real methods for autonomous driving video generation typically rely on explicit intermediate representations to bridge the domain gap. However, these modalities face a fundamental Consistency-Realism Dilemma. Low-level signals (e.g., edges, blurred images) ensure precise control but compromise realism by "baking in" synthetic artifacts, whereas high-level priors (e.g., depth, semantics, HDMaps) facilitate photorealism but lack the structural detail required for consistent guidance. In this work, we present Driving with DINO (DwD), a novel framework that leverages Vision Foundation Module (VFM) features as a unified bridge between the simulation and real-world domains. We first identify that these features encode a spectrum of information, from high-level semantics to fine-grained structure. To effectively utilize this, we employ Principal Subspace Projection to discard the high-frequency elements responsible for "texture baking," while concurrently introducing Random Channel Tail Drop to mitigate the structural loss inherent in rigid dimensionality reduction, thereby reconciling realism with control consistency. Furthermore, to fully leverage DINOv3's high-resolution capabilities for enhancing control precision, we introduce a learnable Spatial Alignment Module that adapts these high-resolution features to the diffusion backbone. Finally, we propose a Causal Temporal Aggregator employing causal convolutions to explicitly preserve historical motion context when integrating frame-wise DINO features, which effectively mitigates motion blur and guarantees temporal stability. Project page: https://albertchen98.github.io/DwD-project/
MeSS: City Mesh-Guided Outdoor Scene Generation with Cross-View Consistent Diffusion
Aug 21, 2025Mesh models have become increasingly accessible for numerous cities; however, the lack of realistic textures restricts their application in virtual urban navigation and autonomous driving. To address this, this paper proposes MeSS (Meshbased Scene Synthesis) for generating high-quality, styleconsistent outdoor scenes with city mesh models serving as the geometric prior. While image and video diffusion models can leverage spatial layouts (such as depth maps or HD maps) as control conditions to generate street-level perspective views, they are not directly applicable to 3D scene generation. Video diffusion models excel at synthesizing consistent view sequences that depict scenes but often struggle to adhere to predefined camera paths or align accurately with rendered control videos. In contrast, image diffusion models, though unable to guarantee cross-view visual consistency, can produce more geometry-aligned results when combined with ControlNet. Building on this insight, our approach enhances image diffusion models by improving cross-view consistency. The pipeline comprises three key stages: first, we generate geometrically consistent sparse views using Cascaded Outpainting ControlNets; second, we propagate denser intermediate views via a component dubbed AGInpaint; and third, we globally eliminate visual inconsistencies (e.g., varying exposure) using the GCAlign module. Concurrently with generation, a 3D Gaussian Splatting (3DGS) scene is reconstructed by initializing Gaussian balls on the mesh surface. Our method outperforms existing approaches in both geometric alignment and generation quality. Once synthesized, the scene can be rendered in diverse styles through relighting and style transfer techniques.
GGS: Generalizable Gaussian Splatting for Lane Switching in Autonomous Driving
Sep 04, 2024
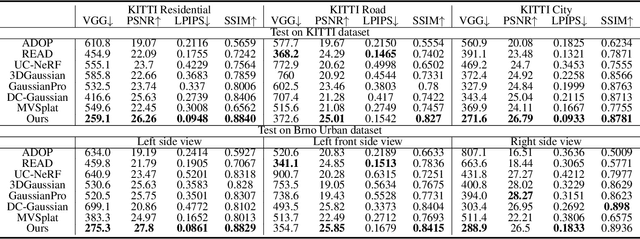
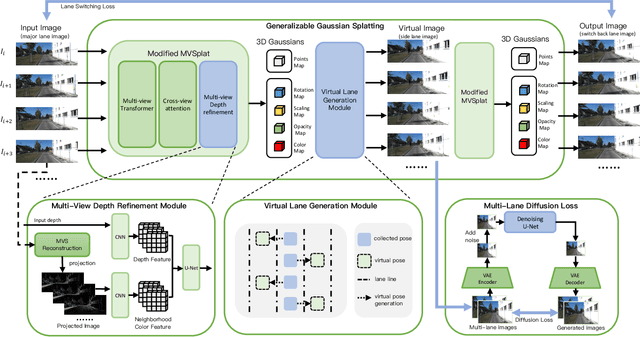

We propose GGS, a Generalizable Gaussian Splatting method for Autonomous Driving which can achieve realistic rendering under large viewpoint changes. Previous generalizable 3D gaussian splatting methods are limited to rendering novel views that are very close to the original pair of images, which cannot handle large differences in viewpoint. Especially in autonomous driving scenarios, images are typically collected from a single lane. The limited training perspective makes rendering images of a different lane very challenging. To further improve the rendering capability of GGS under large viewpoint changes, we introduces a novel virtual lane generation module into GSS method to enables high-quality lane switching even without a multi-lane dataset. Besides, we design a diffusion loss to supervise the generation of virtual lane image to further address the problem of lack of data in the virtual lanes. Finally, we also propose a depth refinement module to optimize depth estimation in the GSS model. Extensive validation of our method, compared to existing approaches, demonstrates state-of-the-art performance.
SAT3D: Image-driven Semantic Attribute Transfer in 3D
Aug 03, 2024GAN-based image editing task aims at manipulating image attributes in the latent space of generative models. Most of the previous 2D and 3D-aware approaches mainly focus on editing attributes in images with ambiguous semantics or regions from a reference image, which fail to achieve photographic semantic attribute transfer, such as the beard from a photo of a man. In this paper, we propose an image-driven Semantic Attribute Transfer method in 3D (SAT3D) by editing semantic attributes from a reference image. For the proposed method, the exploration is conducted in the style space of a pre-trained 3D-aware StyleGAN-based generator by learning the correlations between semantic attributes and style code channels. For guidance, we associate each attribute with a set of phrase-based descriptor groups, and develop a Quantitative Measurement Module (QMM) to quantitatively describe the attribute characteristics in images based on descriptor groups, which leverages the image-text comprehension capability of CLIP. During the training process, the QMM is incorporated into attribute losses to calculate attribute similarity between images, guiding target semantic transferring and irrelevant semantics preserving. We present our 3D-aware attribute transfer results across multiple domains and also conduct comparisons with classical 2D image editing methods, demonstrating the effectiveness and customizability of our SAT3D.
NeuralRoom: Geometry-Constrained Neural Implicit Surfaces for Indoor Scene Reconstruction
Oct 13, 2022


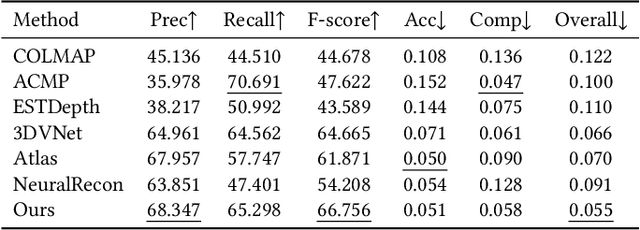
We present a novel neural surface reconstruction method called NeuralRoom for reconstructing room-sized indoor scenes directly from a set of 2D images. Recently, implicit neural representations have become a promising way to reconstruct surfaces from multiview images due to their high-quality results and simplicity. However, implicit neural representations usually cannot reconstruct indoor scenes well because they suffer severe shape-radiance ambiguity. We assume that the indoor scene consists of texture-rich and flat texture-less regions. In texture-rich regions, the multiview stereo can obtain accurate results. In the flat area, normal estimation networks usually obtain a good normal estimation. Based on the above observations, we reduce the possible spatial variation range of implicit neural surfaces by reliable geometric priors to alleviate shape-radiance ambiguity. Specifically, we use multiview stereo results to limit the NeuralRoom optimization space and then use reliable geometric priors to guide NeuralRoom training. Then the NeuralRoom would produce a neural scene representation that can render an image consistent with the input training images. In addition, we propose a smoothing method called perturbation-residual restrictions to improve the accuracy and completeness of the flat region, which assumes that the sampling points in a local surface should have the same normal and similar distance to the observation center. Experiments on the ScanNet dataset show that our method can reconstruct the texture-less area of indoor scenes while maintaining the accuracy of detail. We also apply NeuralRoom to more advanced multiview reconstruction algorithms and significantly improve their reconstruction quality.