 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFA: Real-time Egocentric Facial Animations for Virtual Reality
Jan 07, 2026We present a novel system for real-time tracking of facial expressions using egocentric views captured from a set of infrared cameras embedded in a virtual reality (VR) headset. Our technology facilitates any user to accurately drive the facial expressions of virtual characters in a non-intrusive manner and without the need of a lengthy calibration step. At the core of our system is a distillation based approach to train a machine learning model on heterogeneous data and labels coming form multiple sources, \eg synthetic and real images. As part of our dataset, we collected 18k diverse subjects using a lightweight capture setup consisting of a mobile phone and a custom VR headset with extra cameras. To process this data, we developed a robust differentiable rendering pipeline enabling us to automatically extract facial expression labels. Our system opens up new avenues for communication and expression in virtual environments, with applications in video conferencing, gaming, entertainment, and remote collaboration.
FlexAvatar: Flexible Large Reconstruction Model for Animatable Gaussian Head Avatars with Detailed Deformation
Dec 19, 2025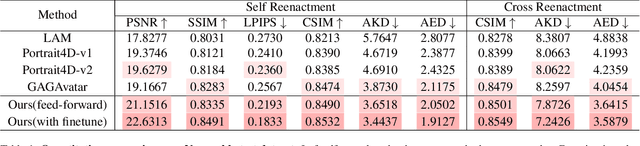
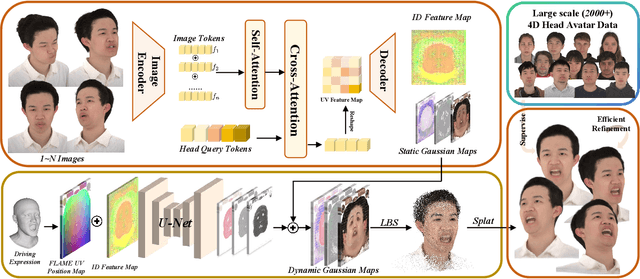
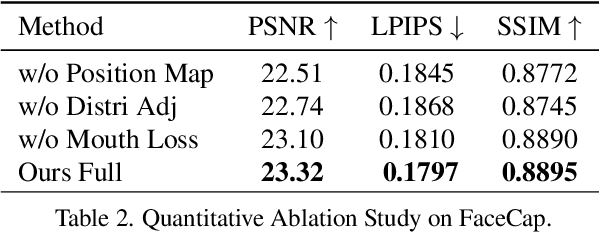

We present FlexAvatar, a flexible large reconstruction model for high-fidelity 3D head avatars with detailed dynamic deformation from single or sparse images, without requiring camera poses or expression labels. It leverages a transformer-based reconstruction model with structured head query tokens as canonical anchor to aggregate flexible input-number-agnostic, camera-pose-free and expression-free inputs into a robust canonical 3D representation. For detailed dynamic deformation, we introduce a lightweight UNet decoder conditioned on UV-space position maps, which can produce detailed expression-dependent deformations in real time. To better capture rare but critical expressions like wrinkles and bared teeth, we also adopt a data distribution adjustment strategy during training to balance the distribution of these expressions in the training set. Moreover, a lightweight 10-second refinement can further enhances identity-specific details in extreme identities without affecting deformation quality. Extensive experiments demonstrate that our FlexAvatar achieves superior 3D consistency, detailed dynamic realism compared with previous methods, providing a practical solution for animatable 3D avatar creation.
TAR-TVG: Enhancing VLMs with Timestamp Anchor-Constrained Reasoning for Temporal Video Grounding
Aug 11, 2025Temporal Video Grounding (TVG) aims to precisely localize video segments corresponding to natural language queries, which is a critical capability for long-form video understanding. Although existing reinforcement learning approaches encourage models to generate reasoning chains before predictions, they fail to explicitly constrain the reasoning process to ensure the quality of the final temporal predictions. To address this limitation, we propose Timestamp Anchor-constrained Reasoning for Temporal Video Grounding (TAR-TVG), a novel framework that introduces timestamp anchors within the reasoning process to enforce explicit supervision to the thought content. These anchors serve as intermediate verification points. More importantly, we require each reasoning step to produce increasingly accurate temporal estimations, thereby ensuring that the reasoning process contributes meaningfully to the final prediction. To address the challenge of low-probability anchor generation in models (e.g., Qwen2.5-VL-3B), we develop an efficient self-distillation training strategy: (1) initial GRPO training to collect 30K high-quality reasoning traces containing multiple timestamp anchors, (2) supervised fine-tuning (SFT) on distilled data, and (3) final GRPO optimization on the SFT-enhanced model. This three-stage training strategy enables robust anchor generation while maintaining reasoning quality. Experiments show that our model achieves state-of-the-art performance while producing interpretable, verifiable reasoning chains with progressively refined temporal estimations.
Invert4TVG: A Temporal Video Grounding Framework with Inversion Tasks for Enhanced Action Understanding
Aug 10, 2025Temporal Video Grounding (TVG) seeks to localize video segments matching a given textual query. Current methods, while optimizing for high temporal Intersection-over-Union (IoU), often overfit to this metric, compromising semantic action understanding in the video and query, a critical factor for robust TVG. To address this, we introduce Inversion Tasks for TVG (Invert4TVG), a novel framework that enhances both localization accuracy and action understanding without additional data. Our approach leverages three inversion tasks derived from existing TVG annotations: (1) Verb Completion, predicting masked action verbs in queries from video segments; (2) Action Recognition, identifying query-described actions; and (3) Video Description, generating descriptions of video segments that explicitly embed query-relevant actions. These tasks, integrated with TVG via a reinforcement learning framework with well-designed reward functions, ensure balanced optimization of localization and semantics. Experiments show our method outperforms state-of-the-art approaches, achieving a 7.1\% improvement in R1@0.7 on Charades-STA for a 3B model compared to Time-R1. By inverting TVG to derive query-related actions from segments, our approach strengthens semantic understanding, significantly raising the ceiling of localization accuracy.
PUMPS: Skeleton-Agnostic Point-based Universal Motion Pre-Training for Synthesis in Human Motion Tasks
Jul 27, 2025Motion skeletons drive 3D character animation by transforming bone hierarchies, but differences in proportions or structure make motion data hard to transfer across skeletons, posing challenges for data-driven motion synthesis. Temporal Point Clouds (TPCs) offer an unstructured, cross-compatible motion representation. Though reversible with skeletons, TPCs mainly serve for compatibility, not for direct motion task learning. Doing so would require data synthesis capabilities for the TPC format, which presents unexplored challenges regarding its unique temporal consistency and point identifiability. Therefore, we propose PUMPS, the primordial autoencoder architecture for TPC data. PUMPS independently reduces frame-wise point clouds into sampleable feature vectors, from which a decoder extracts distinct temporal points using latent Gaussian noise vectors as sampling identifiers. We introduce linear assignment-based point pairing to optimise the TPC reconstruction process, and negate the use of expensive point-wise attention mechanisms in the architecture. Using these latent features, we pre-train a motion synthesis model capable of performing motion prediction, transition generation, and keyframe interpolation. For these pre-training tasks, PUMPS performs remarkably well even without native dataset supervision, matching state-of-the-art performance. When fine-tuned for motion denoising or estimation, PUMPS outperforms many respective methods without deviating from its generalist architecture.
Repurposing 2D Diffusion Models with Gaussian Atlas for 3D Generation
Mar 20, 2025Recent advances in text-to-image diffusion models have been driven by the increasing availability of paired 2D data. However, the development of 3D diffusion models has been hindered by the scarcity of high-quality 3D data, resulting in less competitive performance compared to their 2D counterparts. To address this challenge, we propose repurposing pre-trained 2D diffusion models for 3D object generation. We introduce Gaussian Atlas, a novel representation that utilizes dense 2D grids, enabling the fine-tuning of 2D diffusion models to generate 3D Gaussians. Our approach demonstrates successful transfer learning from a pre-trained 2D diffusion model to a 2D manifold flattened from 3D structures. To support model training, we compile GaussianVerse, a large-scale dataset comprising 205K high-quality 3D Gaussian fittings of various 3D objects. Our experimental results show that text-to-image diffusion models can be effectively adapted for 3D content generation, bridging the gap between 2D and 3D modeling.
Automated 3D Physical Simulation of Open-world Scene with Gaussian Splatting
Nov 19, 2024
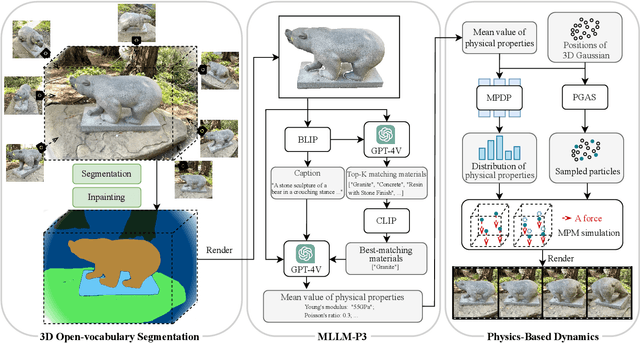
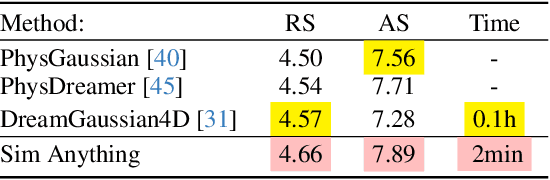
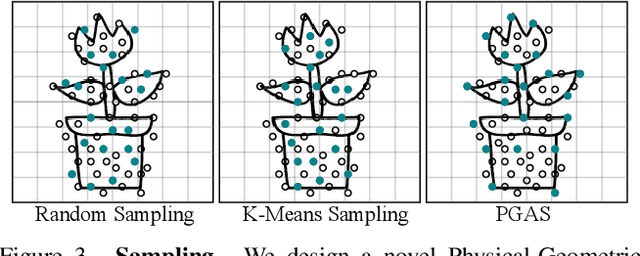
Recent advancements in 3D generation models have opened new possibilities for simulating dynamic 3D object movements and customizing behaviors, yet creating this content remains challenging. Current methods often require manual assignment of precise physical properties for simulations or rely on video generation models to predict them, which is computationally intensive. In this paper, we rethink the usage of multi-modal large language model (MLLM) in physics-based simulation, and present Sim Anything, a physics-based approach that endows static 3D objects with interactive dynamics. We begin with detailed scene reconstruction and object-level 3D open-vocabulary segmentation, progressing to multi-view image in-painting. Inspired by human visual reasoning, we propose MLLM-based Physical Property Perception (MLLM-P3) to predict mean physical properties of objects in a zero-shot manner. Based on the mean values and the object's geometry, the Material Property Distribution Prediction model (MPDP) model then estimates the full distribution, reformulating the problem as probability distribution estimation to reduce computational costs. Finally, we simulate objects in an open-world scene with particles sampled via the Physical-Geometric Adaptive Sampling (PGAS) strategy, efficiently capturing complex deformations and significantly reducing computational costs. Extensive experiments and user studies demonstrate our Sim Anything achieves more realistic motion than state-of-the-art methods within 2 minutes on a single GPU.
Motion Keyframe Interpolation for Any Human Skeleton via Temporally Consistent Point Cloud Sampling and Reconstruction
May 13, 2024In the character animation field, modern supervised keyframe interpolation models have demonstrated exceptional performance in constructing natural human motions from sparse pose definitions. As supervised models, large motion datasets are necessary to facilitate the learning process; however, since motion is represented with fixed hierarchical skeletons, such datasets are incompatible for skeletons outside the datasets' native configurations. Consequently, the expected availability of a motion dataset for desired skeletons severely hinders the feasibility of learned interpolation in practice. To combat this limitation, we propose Point Cloud-based Motion Representation Learning (PC-MRL), an unsupervised approach to enabling cross-compatibility between skeletons for motion interpolation learning. PC-MRL consists of a skeleton obfuscation strategy using temporal point cloud sampling, and an unsupervised skeleton reconstruction method from point clouds. We devise a temporal point-wise K-nearest neighbors loss for unsupervised learning. Moreover, we propose First-frame Offset Quaternion (FOQ) and Rest Pose Augmentation (RPA) strategies to overcome necessary limitations of our unsupervised point cloud-to-skeletal motion process. Comprehensive experiments demonstrate the effectiveness of PC-MRL in motion interpolation for desired skeletons without supervision from native datasets.
Multiple-Crop Human Mesh Recovery with Contrastive Learning and Camera Consistency in A Single Image
Feb 03, 2024



We tackle the problem of single-image Human Mesh Recovery (HMR). Previous approaches are mostly based on a single crop. In this paper, we shift the single-crop HMR to a novel multiple-crop HMR paradigm. Cropping a human from image multiple times by shifting and scaling the original bounding box is feasible in practice, easy to implement, and incurs neglectable cost, but immediately enriches available visual details. With multiple crops as input, we manage to leverage the relation among these crops to extract discriminative features and reduce camera ambiguity. Specifically, (1) we incorporate a contrastive learning scheme to enhance the similarity between features extracted from crops of the same human. (2) We also propose a crop-aware fusion scheme to fuse the features of multiple crops for regressing the target mesh. (3) We compute local cameras for all the input crops and build a camera-consistency loss between the local cameras, which reward us with less ambiguous cameras. Based on the above innovations, our proposed method outperforms previous approaches as demonstrated by the extensive experiments.
Incorporating Exemplar Optimization into Training with Dual Networks for Human Mesh Recovery
Jan 25, 2024



We propose a novel optimization-based human mesh recovery method from a single image. Given a test exemplar, previous approaches optimize the pre-trained regression network to minimize the 2D re-projection loss, which however suffer from over-/under-fitting problems. This is because the ``exemplar optimization'' at testing time has too weak relation to the pre-training process, and the exemplar optimization loss function is different from the training loss function. (1) We incorporate exemplar optimization into the training stage. During training, our method first executes exemplar optimization and subsequently proceeds with training-time optimization. The exemplar optimization may run into a wrong direction, while the subsequent training optimization serves to correct the deviation. Involved in training, the exemplar optimization learns to adapt its behavior to training data, thereby acquires generalibility to test exemplars. (2) We devise a dual-network architecture to convey the novel training paradigm, which is composed of a main regression network and an auxiliary network, in which we can formulate the exemplar optimization loss function in the same form as the training loss function. This further enhances the compatibility between the exemplar and training optimizations. Experiments demonstrate that our exemplar optimization after the novel training scheme significantly outperforms state-of-the-art approaches.